
1. 대회 개요
1.1 대회 의의
문장 속에서 단어간에 관계성을 파악하는 것은 의미나 의도를 해석함에 있어서 많은 도움을 줍니다. 그림의 예시와 같이 요약된 정보를 사용해 QA 시스템 구축과 활용이 가능하며, 이외에도 요약된 언어 정보를 바탕으로 효율적인 시스템 및 서비스 구성이 가능합니다. 관계 추출(Relation Extraction)은 문장의 단어(Entity)에 대한 속성과 관계를 예측하는 문제입니다. 관계 추출은 지식 그래프 구축을 위한 핵심 구성 요소로, 구조화된 검색, 감정 분석, 질문 답변하기, 요약과 같은 자연어처리 응용 프로그램에서 중요합니다. 비구조적인 자연어 문장에서 구조적인 triple을 추출해 정보를 요약하고, 중요한 성분을 핵심적으로 파악할 수 있습니다. 이번 대회에서는 문장, 단어에 대한 정보를 통해 ,문장 속에서 단어 사이의 관계를 추론하는 모델을 학습시킵니다. 이를 통해 우리의 인공지능 모델이 단어들의 속성과 관계를 파악하며 개념을 학습할 수 있습니다. 우리의 model이 정말 언어를 잘 이해하고 있는 지, 평가해 보도록 합니다.
1.2 Input and Output
- input: sentence, subject_entity, object_entity의 정보
- output: relation 30개 중 하나를 예측한 pred_label, 그리고 30개 클래스 각각에 대해 예측한 확률 probs을 제출
1.3 Task 정리
sentence, subject_entity, object_entity 3개의 입력을 받아 subject_entity, object_entity 사이의 관계를 30개의 라벨로 분류
2. 대회 결과 요약
2.1 최종 Score 및 랭킹
- 최종 score
- public
- f1-score: 72.940, auprc: 76.668
- f1-score: 72.669, auprc: 77.220
- private
- f1-score:71.910, auprc: 79.132
- f1-score:71.697, auprc: 78.287
- public
- 최종 rangking: 13
3. 데이터
3.1 데이터 통계
- train.csv: 총 32470개
- test_data.csv: 총 7765개 (정답 라벨 blind = 100으로 임의 표현)
- 학습을 위한 데이터는 총 32470개 이며, 7765개의 test 데이터를 통해 리더보드 순위를 갱신 (public과 private 2가지 종류의 리더보드가 운영)
3.2 EDA
- Class imbalance
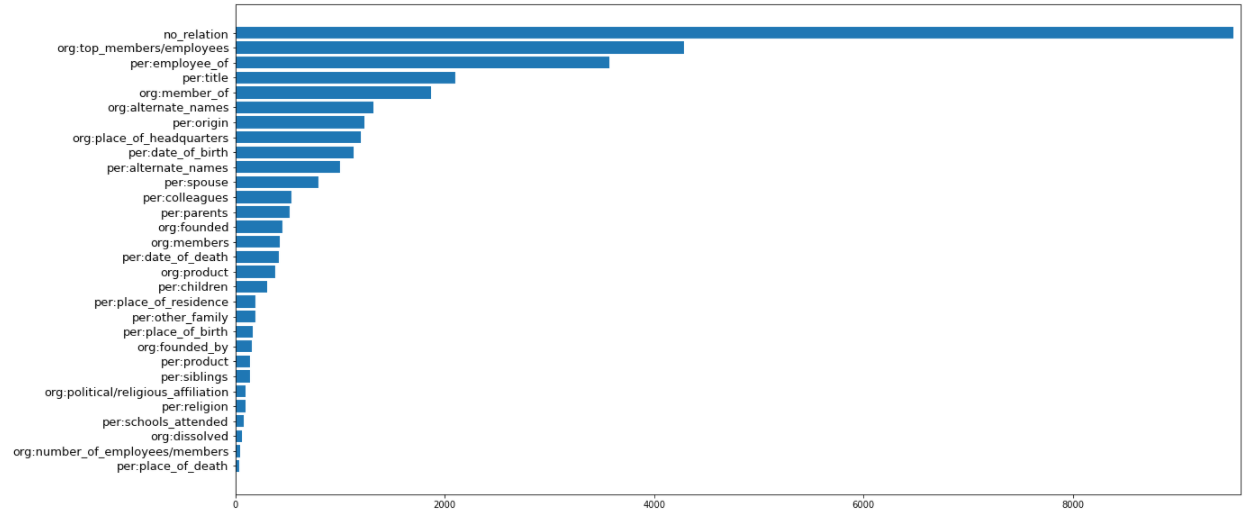
- no_relation 비중이 굉장히 높음 (9534 건)
- 가장 적은 class 가 40 건
- 비율을 맞추거나 보완할 방법 필요
- subject entity와 object entity에는 6가지 타입이 존재
- “PER”:”사람”, “ORG”:”단체”, “POH” : “기타”, “LOC” : “장소”, “NOH” : “수량”, “DAT” : “날짜”
- 하지만 데이터를 살펴보다 보면, 잘못 라벨링된 데이터들이 존재
- 테스트 데이터에서도, 분명 잘못 라벨링된 데이터들이 존재할 것이기 때문에 이것을 수정해야되는 지는 고민해 볼 필요가 있음
- Sentence는 대체로 깔끔해 따로 전처리할 필요 없음
4. 시도 및 결과 정리
4.1 Class imbalance 보완을 위한 시도
- Data Augmentaion
- 가설: KLUE RE task는 사전지식 없이 문장내에서 알 수 있는 관계를 분류하는 것이기 때문에, random으로 적용하는 것이 가능하다고 판단
- 내부 Entity change
- 역방향 관계가 성립하는 라벨들 subject entity와 object entity 교체
- 예를 들어, ‘per:sibling’은 형제 자매 관계를 나타냄, 따라서 subject entity와 object entity를 바꾸어도 관계가 성립
- 예를 들어, ‘org:member_of’ 데이터들은 두 entity를 교체하면 ‘org:members’가 됨
- “서울”은 “대한민국”의 한 도시이다. // 서울:대한민국 = org:member_of $\rightarrow$ 대한민국:서울 = org:members
- 랜덤 Entity change
- “서울”은 “대한민국”의 한 도시이다. // 서울:대한민국 = org:member_of $\rightarrow$ 대한민국:서울 = org:members
- 대부분의 관계는 subject 타입과 object 타입이 정해져 있음, 따라서 각 타입에 맞는 entity를 랜덤으로 변경
- 예를 들어, ‘per:sibling’은 PER과 PER 사이의 관계임, 그래서 두 entity에 랜덤한 PER type의 entity를 부여
- “민지”와 “영희”는 자매이다. $\rightarrow$ “민수”와 “메시”는 자매이다.
- 결과
- 성능 개선 효과는 미미했다. 아마도 entity만 바뀌고, 동일한 문장들이 여럿 있었기 때문에 처음에는 데이터의 정보량이 늘어났다고 생각했지만, 결과를 보니 이러한 방식으로는 데이터의 정보량을 늘리지 못한다는 것을 배웠다.
- 가설: KLUE RE task는 사전지식 없이 문장내에서 알 수 있는 관계를 분류하는 것이기 때문에, random으로 적용하는 것이 가능하다고 판단
- Weighted Loss
- Weighted Cross-entropy: 각 클래스의 데이터 수에 따라 가중치 부여
- Focal Loss: 예측하기 쉬운 example에는 0에 가까운 loss를 부여하고, 예측하기 어려운 negative example에는 기존보다 높은 loss를 부여
- 결과
- Focal Loss의 비중을 높였을 때, 약간 더 빠르게 학습하고, 더 좋은 성능에 도달했다. 하지만 수렴점이 비슷한 것으로보아 데이터의 정보량이나 학습 모델, 알고리즘의 변경이 필요해 보인다.
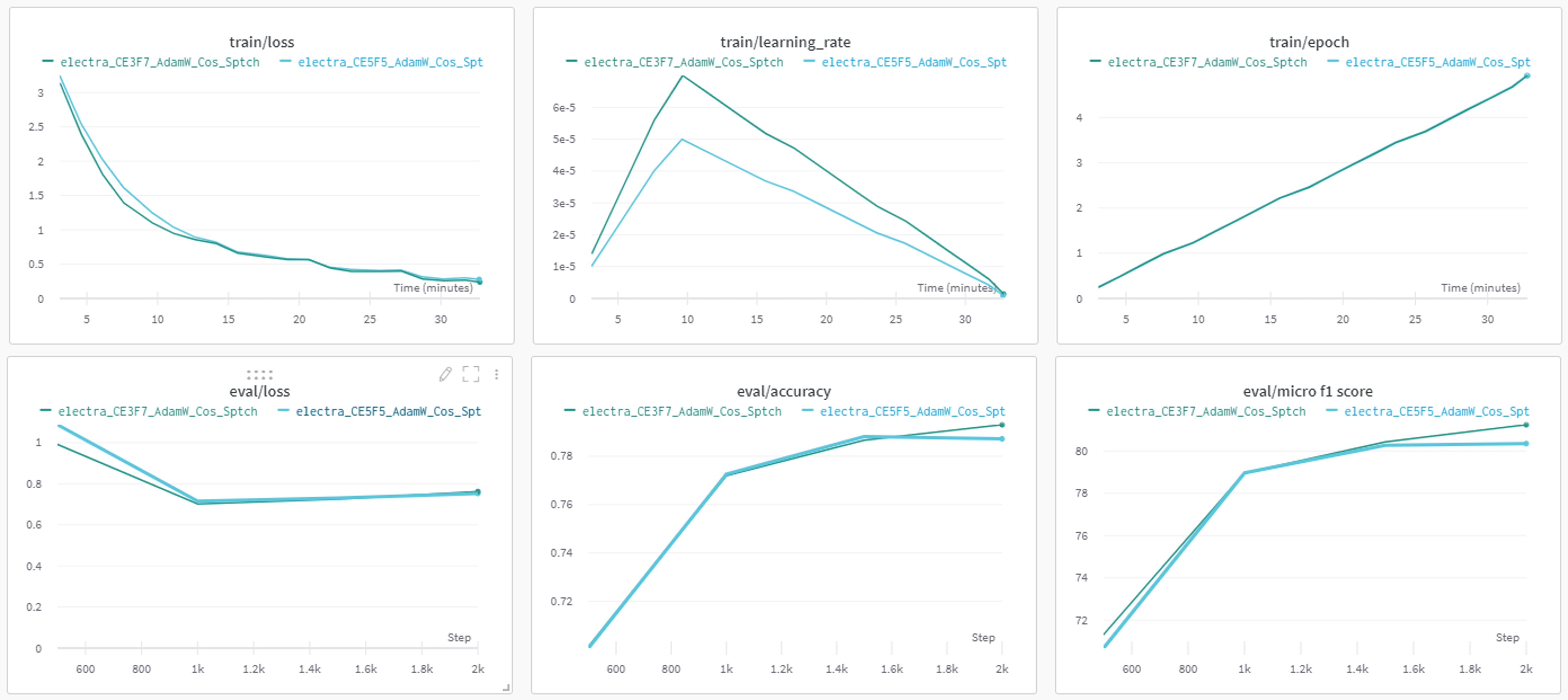
- Focal Loss의 비중을 높였을 때, 약간 더 빠르게 학습하고, 더 좋은 성능에 도달했다. 하지만 수렴점이 비슷한 것으로보아 데이터의 정보량이나 학습 모델, 알고리즘의 변경이 필요해 보인다.
4.3 모델 구조 및 알고리즘 개선 시도
- 문장 내에 Entity 표시
- Special token 추가 [E1] [/E1] [E2] [/E2] 로 문장 내에서 Entity 표시
- E.g. [E1] 이순신 [/E1] 은 조선의 [E2] 무신 [/E2] 이다.
- Punctuation
- E.g. @* 이순신 @ 은 조선의 +^ 무신 + 이다.
- Punctuation + type
- E.g. @ * 사람 * 이순신 @ 은 조선의 + ^ POH ^ 무신 + 이다.
- Special token 추가 [E1] [/E1] [E2] [/E2] 로 문장 내에서 Entity 표시
- Two stage 학습
- 가설: 데이터셋의 약 30%가 no_relation 이다. test_data 또한 no_relation이 많은 비중을 차지할 가능성이 높다. 따라서 먼저 noise가 될 수 있는 No_relation 데이터들을 분리해 내고 남은 데이터 안에서 29 라벨로 분류학습을 한다면, 이전에 비해 각 라벨들의 특성에 조금 더 집중 할 수 있을 것이다.
- 먼저 비중이 큰 No_relation/relation으로 이진 분류한 뒤, relation으로 판단된 데이터에 대해 2차 분류
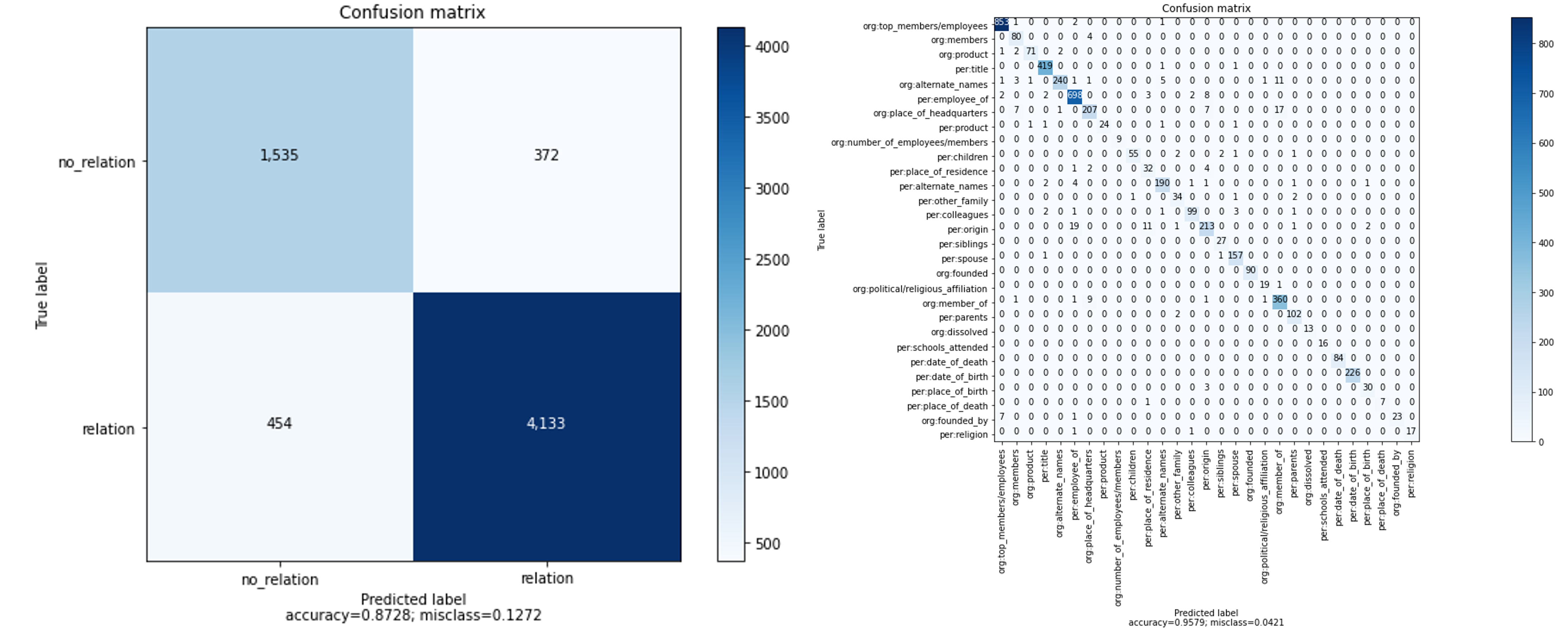
- 결과
- 20% valid set에 대한 결과 (왼-binary classification 모델 / 오-multi classification 모델)
- valid set에서는 나름 좋은 결과를 보여주었지만, 리더보드에서는 f1-score 58점대에 그쳤다. no_relation로 판단된 데이터의 비율을 봤을 때, multi classification 모델이 약간 test_data에서 약했다고 생각된다.
- Entity Embedding 추가
- 가설: BERT에서 두문장을 동시에 학습할 때, 첫번째 문장과 두번째 문장을 구분하기 위해 token_type_ids라는 벡터를 사용한다. 유사한 방식으로 entity의 위치를 알려주면 모델이 조금더 entity에 집중해서 feature를 학습할 것이다.
- transformers의 Embedding 모듈에 torch.nn.Embedding layer 추가, 입력 값도 추가 (엔티티 위치를 표시한 벡터)
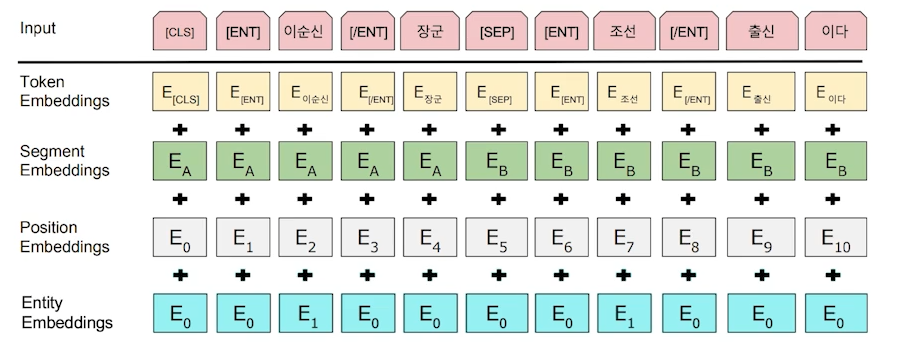
- 결과
- torch.nn.Embedding layer의 가중치 초기값이 어떻게 잡히냐에 따라 성능이 많이 좌지우지 되는 것 같은 현상을 보였다. 초기 값에 따라 성능이 오차범위 3% 정도 차이가 났다.
- 결과적으로 완전 기본 모델인 pretrained roberta-large 모델에 비해서는 성능의 상승이 있었다. (f1-score: 64.491 $\rightarrow$ 67.42)
- Classification Head 수정
- 가설: RE task를 수행할때, [CLS] token만 쓰는 것은 이상하다. 한문장안에 여러 관계가 있을 수 있는데, 그 모든 것을 담고 있는 [CLS] token을 사용하는 것이 맞을까? Entity의 임베딩 값도 같이 사용해보자!
- RobertaPreTrainedModel class를 상속받는 MyRobertaForSequenceClassification 새롭게 정의하고, 안에서 classifier를 새롭게 정의했다. classifier에서는 Entity의 위치 값을 기반으로 각 entity의 encoder output들의 평균과 [CLS] token의 encoder output을 concat해서 사용했다. 그러면 classifier가 더 많은 정보를 받을 수 있기 때문에, 여러 관계가 있는 문장에서 혼동이 적어질 것이라 예상했다.
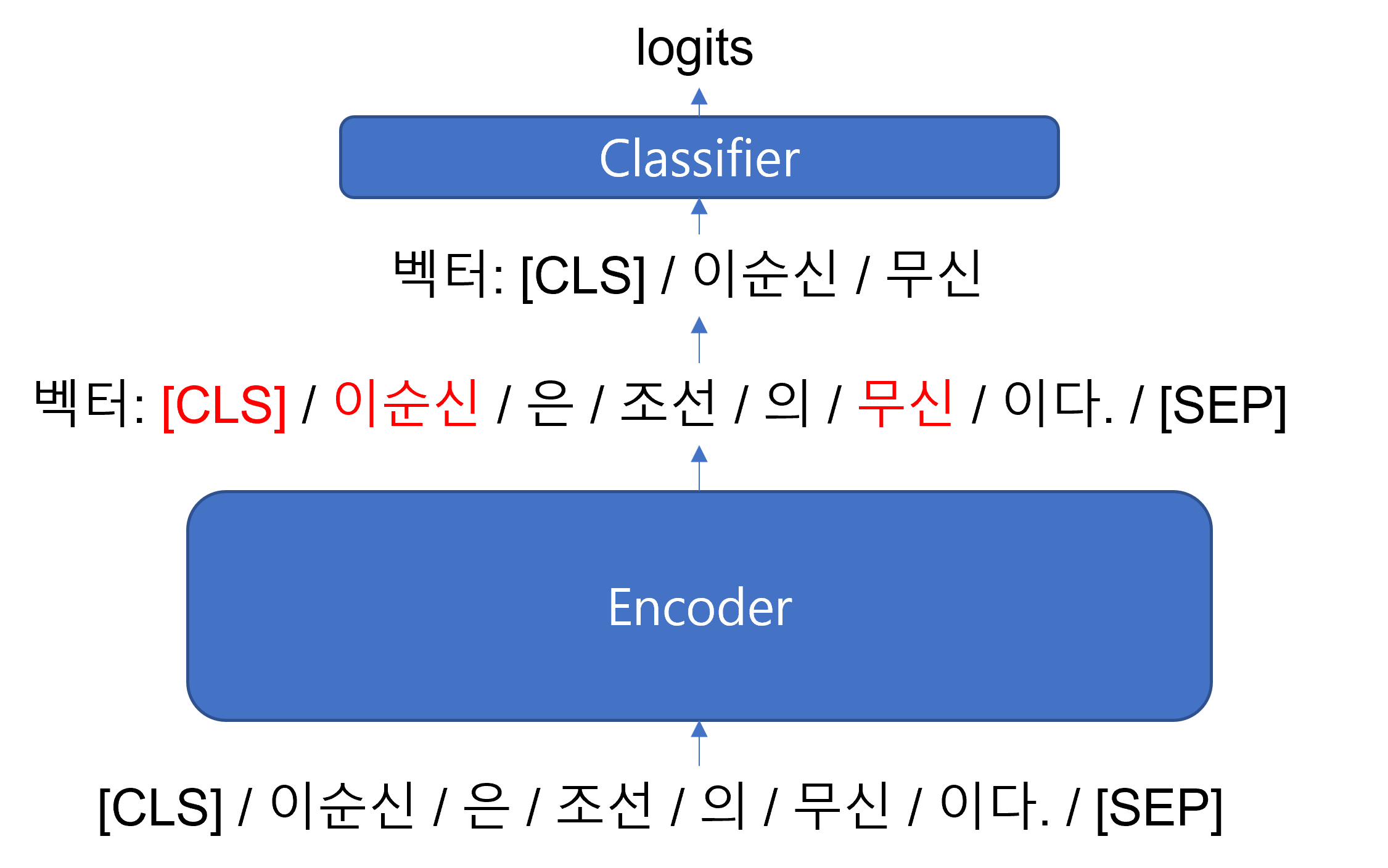
- 결과
- Entity Embedding과 동시에 적용을 해보았기때문에 결과는 동일하다. (f1-score: 64.491 $\rightarrow$ 67.42)
- 지금까지 시도했던 방법중 가장 큰 개선 효과를 보여주었다.
5. 최종 제출
- Base: RoBERTa-large
- Ensemble
- 지금까지 점수가 높았던 모든 모델들 Ensemble $\rightarrow$ Soft voting 방식으로 합산
6. 서비스 관점에서 생각되는 문제점
- 학습과 inference에 굉장한 시간이 소요된다. 따라서 실시간 서비스에는 사용이 어려울 듯하다. 하지만 관계추출이라는 task 특성상 어떤 문장안에서 미리 지식 그래프를 생성하기 위한 것이기 때문에 충분히 서비스 전단계로서는 가치가 있는 것 같다. 하지만 아직 성능이 완벽하지 못하기 때문에, 사람의 검수가 필요하다는 점이 있어, 성능 개선을 위한 연구가 지속적으로 필요할 것 같다.
7. 새롭게 해볼 시도
- 시간이 부족해서 시도해 보지 못했지만, 나중에 AI camp가 끝나고 여유가 생기면, classifer에 transfomer를 사용해 보면 좋을 것 같다. 지금은 단순히 Dense layer로만 이루어져 있기 때문에 model의 capacity에 한계가 있을 것 같다.
- 질문 문장 만들어서 이어서 입력 넣기
- E.g. 이순신은 조선의 무신이다. $\rightarrow$ 이순신은 조신의 무신이다. 이 문장에서 이순신과 무신은 어떤 관계일까?
8. 대회 회고
많이 아쉬운 대회이다. 동시에 두개의 대회를 시작해서 초반 KLUE 대회에 신경을 쓰지 못했지만, 이건 순위를 높이지 못한 변명이 될 수는 없을 것 같다. 문제를 해결하기 위해, 많은 가설을 세우고, 시도해 보았지만, 그렇게 큰 효과(1등을 할 수 있을만한) 결과는 얻지 못했다. 하지만 굉장히 많은 것을 배운것만은 확실하다. NLP 분야에 대해 공부하기 시작한지 한달 조금 더 된 시점에서 많은 이론들을 접하고, 실제로 활용해 보면서 많은 것들을 얻을 수 있었다. 특히 NLP 분야의 필수적인 라이브러리인 Hugging face를 다루고, 단순히 함수를 호출하는 것을 넘어서 내부를 뜯어 커스터마이징 해보면서 BERT에 대해 더 깊게 이해해 볼 수 있었다. 그리고 이번에도 스스로 Base line 코드를 구축해보면서, 이전 보다 성장한 자신을 발견할 수 있었다. 저번에는 코드를 고쳐나가면서 base 라인의 형태가 갖추어 졌는데, 이번에는 저번 시도를 경험삼아 대부분의 기능을 한번에 구현할 수 있었다. 이정도만 해도 큰 수확이 있었던 대회인 것 같다. 이제 바로 다음 대회들이 시작되는데, 한번더 발전할 수 있도록 최선을 다해야겠다.