
1. 대회 개요
COVID-19의 확산으로 우리나라는 물론 전 세계 사람들은 경제적, 생산적인 활동에 많은 제약을 가지게 되었습니다. 우리나라는 COVID-19 확산 방지를 위해 사회적 거리 두기를 단계적으로 시행하는 등의 많은 노력을 하고 있습니다. 과거 높은 사망률을 가진 사스(SARS)나 에볼라(Ebola)와는 달리 COVID-19의 치사율은 오히려 비교적 낮은 편에 속합니다. 그럼에도 불구하고, 이렇게 오랜 기간 동안 우리를 괴롭히고 있는 근본적인 이유는 바로 COVID-19의 강력한 전염력 때문입니다.
감염자의 입, 호흡기로부터 나오는 비말, 침 등으로 인해 다른 사람에게 쉽게 전파가 될 수 있기 때문에 감염 확산 방지를 위해 무엇보다 중요한 것은 모든 사람이 마스크로 코와 입을 가려서 혹시 모를 감염자로부터의 전파 경로를 원천 차단하는 것입니다. 이를 위해 공공 장소에 있는 사람들은 반드시 마스크를 착용해야 할 필요가 있으며, 무엇 보다도 코와 입을 완전히 가릴 수 있도록 올바르게 착용하는 것이 중요합니다. 하지만 넓은 공공장소에서 모든 사람들의 올바른 마스크 착용 상태를 검사하기 위해서는 추가적인 인적자원이 필요할 것입니다.
따라서, 우리는 카메라로 비춰진 사람 얼굴 이미지 만으로 이 사람이 마스크를 쓰고 있는지, 쓰지 않았는지, 정확히 쓴 것이 맞는지 자동으로 가려낼 수 있는 시스템이 필요합니다. 이 시스템이 공공장소 입구에 갖춰져 있다면 적은 인적자원으로도 충분히 검사가 가능할 것입니다.
2. 대회 결과 요약
- f1-score 73.1% -> 72.1%
- 최종 24 등
3. 데이터
- 4,500 명 (훈련: 2,700명 / 평가: 1,800명)
- 남녀, 20 ~ 70대 다양하게 분포
-
Class imbalanced 데이터
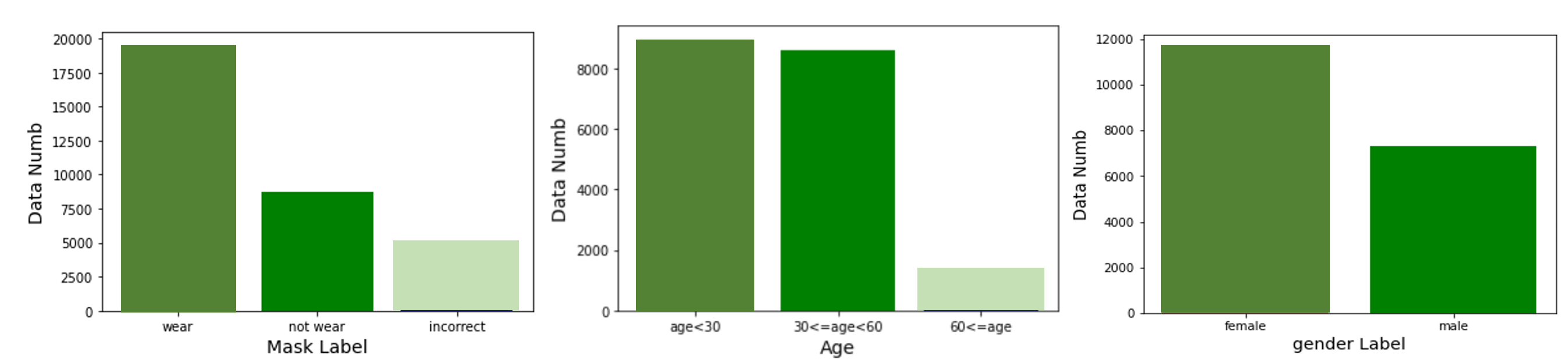
항목 설명 이미지 크기 512 x 384 cropped 이미지 312 x 258
4. 시도 및 결과 정리
- 개인 도전
- Backbone 변경을 통해 피쳐를 가장 잘 만들 수 있는 backbone 찾기 ImageNet 데이터로 학습된 모델들을 backbone으로 선택하기 위해, timm 라이브러리에서 성능 순위를 참고하였습니다. EfficientNet, Vision transformer이 주를 이루었기 때문에 두 모델을 중심으로 Pretrained 모델을 변경해 가며 실험을 해보았습니다. 실험 결과 모델들의 성능이 유사했지만, 그래도 EfficientNet 성능이 좋아 기본 backbone으로 선정하였습니다.
- Learning rate 및 Optimizer 변경해보기, Scheduler 사용하기 실험 결과 Learning rate와 Scheduler를 어떻게 사용하냐에 따라서 동일한 모델이라도 성능이 많이 달라질 수 있다는 것을 알 수 있었습니다. 따라서 EfficientNet, VIT, MobileNet, VGG19, Resnet 5개의 모델에서 Optimizer, Learning rate와 Scheduler를 변경해보았습니다. 결과적으로 MobileNet과 AdamW, Cosine Annealing Scheduler가 조합이 가장 좋은 성능을 보여주어 실험 진행 모델로 채택을 하였습니다.
- Augmentation, Transform을 이용한 데이터 변화주기 이번 문제를 풀기 위해서는 사람의 성별, 나이, 마스크 착용 유무를 제대로 판별해야 한다고 생각했습니다. 그리고 클래스 별로 데이터가 불균형하기 때문에 이를 맞추어 주기 위한 방법이 필요했습니다. 따라서 Center crop을 이용해 위, 아래 불필요한 정보가 담긴 부분을 제거하였습니다. 또한 사진이 흐릿해지거나, 해상도가 낮은 이미지도 있을 수 있기 때문에, Blur와 밝기를 확률 적으로 조절하도록 설정하였습니다. 거기에 더해 학습 전 부족한 클래스의 이미지를 다양하게 변형에 데이터를 늘려주었습니다. 또한 Loss에 class별로 weight를 주어 차이를 보완하였습니다.
- 앙상블 (K-fold, Cross validation) 60%의 훈련데이터를 완전히 활용하기 위해 5-fold로 나누어 Cross validation을 적용했습니다. 마지막 Submission 파일을 만들기 위해서, 5개의 fold 모델의 결과를 Soft Voting을 활용해 조합했습니다.
- 결과 정리 F1-score: 72%까지 달성할 수 있었습니다. 모델에 적절한 Learning rate와 Scheduler를 찾았을 때가 가장 좋은 성능 향상이 있었습니다. 이미 다른 종류의 많은 이미지로 학습된 모델이기 때문에 다른 문제에 적응하기 위해 로컬 미니멈을 잘 탈출하게 해주는 것이 중요했다고 생각합니다. 또한 K-fold를 이용해 앙상블을 하고, 클래스의 균형을 맞추어 주기 위해 Augmentation으로 부족한 클래스의 이미지를 보충해 주었던 것도 성능 향상에 큰 도움이 된 것 같습니다.
- 팀도전
- 모델 분할하기 1주차 후반부터 팀제출이 되면서, 처음 시도한 것은 성별, 나이, 마스크 착용상태를 판별하는 3가지 모델을 따로 만드는 것이었습니다. 저는 나이 모델을 담당하게 되었는데, 성별과 마스크 착용상태에 비해 나이 모델의 성능이 많이 안좋았습니다. 오분류 이미지를 분석해본 결과 클래스를 나누는 경계에 있으신 분들과 비교적 데이터가 부족한 60대 분들을 모델이 잘 판별하지 못하였습니다. 그래서 저는 클래스를 나누는 기준이 너무 광범위하다고 판단해, 클래스를 더 세분화하거나 나이의 값 자체를 MSELoss를 이용해 예측하도록 모델을 만들어 보았습니다. 결과는 기존 보다 더 성능이 떨어졌습니다. 분석결과 오분류 이미지들이 유사했기 때문에 그래서 데이터를 더 잘 만들어야 겠다는 결론을 내릴 수 있었습니다.
- 외부데이터 추가하기 팀원분들이 다양한 외부데이터를 찾아주셔서, 데이터를 늘려서도 실험을 해볼 수 있었습니다. 대회 데이터와 유사하게 가공하기 위해 많은 노력을 기울였지만, 결과는 크게 달라지지 않아서 많이 아쉬웠던 부분입니다.
- Pseudo labeling 대회 막바지에 Pseudo labeling을 이용해, 조금 더 성능 향상을 할 수 없을까 생각해 훈련과정에서 학습된 모델을 활용해 Eval 데이터를 labeling하고 훈련 데이터로 추가시켜 학습하고, 다시 학습된 모델로 라벨을 만들어 학습데이터에 추가하는 과정을 포함해보았습니다. 결과는 오히려 성능이 떨어지게 되었습니다. Label을 만들어주는 모델의 성능에 좌우된다는 점과, 전체 데이터가 아니라 Confidence를 계산해서 Confidence가 높은 데이터만 훈련데이터로 추가했어야 하는데, 시간이 부족해 추가적인 알고리즘을 적용하지 못해 아쉬운 부분입니다.
- FaceNet 활용하기 대회 후반, 토론 게시판에서 얼굴 인식모델의 성능이 좋다는 것을 알 수 있었습니다. 팀원 분께서 base 코드를 만들어 주셔서, 이미지들에 얼굴부분만 남도록 만들 수 있었습니다. 이렇게 가공된 데이터를 활용해, 팀원과 함께 만든 3분할 모델을 학습시켰고, 성능향상에 성공할 수 있었습니다.
5. 최종 모델
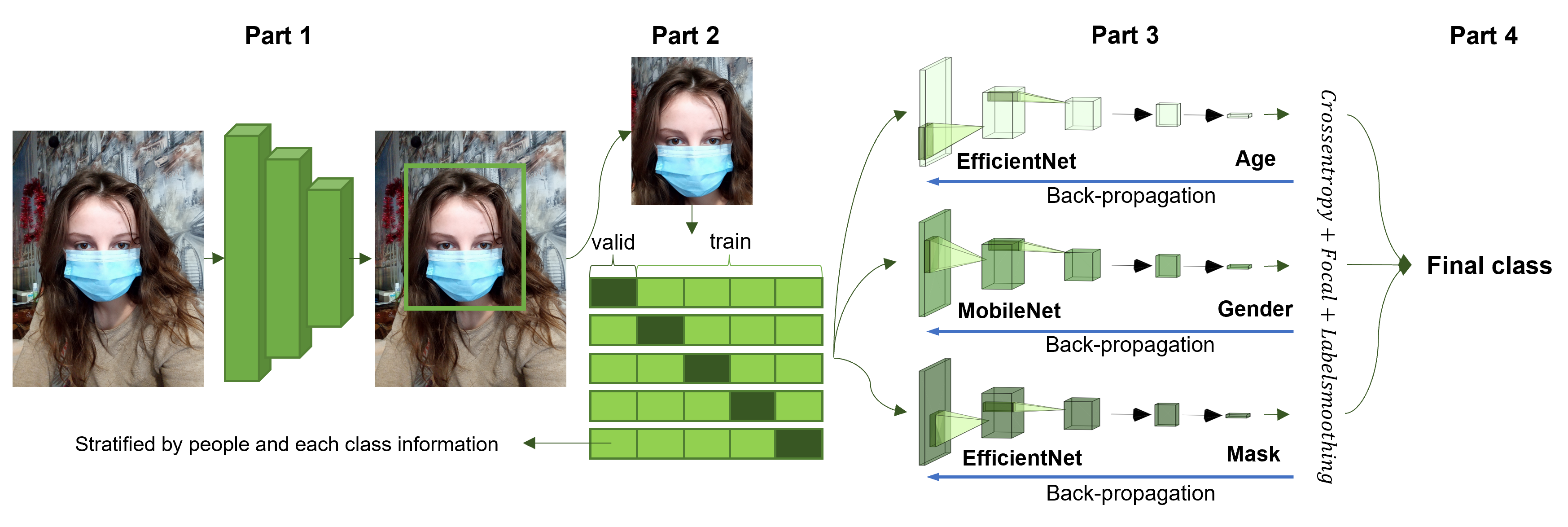
- FaceNet, Retina-face pretrained 모델을 활용해 이미지에서 Face Detection
- Detection된 정보를 활용해 이미지 cropping
- 사람 및 클래스를 Stratified 하게 k-fold 생성
- Age, Gender, Mask 클래스를 각각 다른 모델로 학습
- 각각 5 fold 모델을 Ensemble해 최종 클래스 도출
6. 서비스 관점에서 생각되는 문제점
- 전처리 비용이 있고, FaceNet과 Retina-face 모델의 성능의 영향을 받음
- 서비스 관점에서는 모델 추론 시간이 비효율적
7. 새롭게 해볼 시도
- Unsupervised learning
- 샴네트워크, 트리플넷 로스 등 클러스터링 기법 활용 해보기
- meta learning
- Backbone 모델을 가벼운 것으로 바꾸기 - 오버피팅 방지
8. 대회 회고
Base 코드를 짜고 오류를 고치면서, 시간을 많이 보냈던 것 같습니다. 팀원들에게 base 코드를 제공했는데, 자잘한 오류들이 많았습니다. 조금 더 책임감을 가지고, 한 번 더 확인하고 배포하는 습관을 익혀야겠다는 생각이 들었습니다. 그리고 대회 초반에, 학습을 진행하기 전에 어떤 것을 결과로 둘지 미리 설계하지 않아 학습 후에 후회를 했던 일이 있었습니다. 이렇게 처음 진행해보는 대회였기 때문에 시간이 많이 소요되었던 것 같습니다. 그만큼 많이 배울 수 있었고 성장할 수 있었던 것 같습니다. 이제는 제가 이해하고 사용할 수 있는 Base Line 코드를 갖추었기 때문에 다음 P-stage에는 더 빨리 적응하고 많은 실험을 더 체계적으로 진행할 수 있을 것 같습니다. 같이 밤을 새고, 노력해준 팀원분들이 있어서 많이 배우고 또 대회 진행이 굉장히 재밌었습니다. 비록 메달권에는 들지 못했지만, 혼자였다면 아마 개인 제출 결과에 머물러 있지 않았을까 생각이 듭니다. 협력을 통해 계속 토론하고, 의견을 주고받으면서 빠르게 의문점도 해결할 수 있었습니다. 다시 한번 다같이 끝까지 노력해준 팀원들에게 감사하다는 말을 전하고 싶습니다.