
1. Vanishing gradient problem
def sigmoid(x):
return 1 / (1 + np.exp(-x))
- Sigmoid
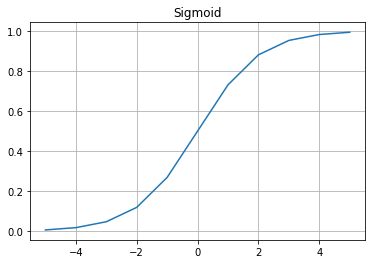
- 미분 했을 때, 기울기가 큰 부분?
- 0 근처 -> 0.25 정도 밖에 안됨
- $sigmoid’() = {e^x \over (1+e^x)^2}$
- $x=0$ 일때 0.25
- 신경망이 너무 깊어지면!
- 계속 곱해지기 때문에 입력단에 가까울수록 작아질 수 밖에 없음
- Update가 잘 안일어 남
- 0 근처 -> 0.25 정도 밖에 안됨
- 미분값을 너무 작은 activation 함수를 써서 문제가 된다.
- 미분 했을 때, 기울기가 큰 부분?
2. ReLU
def relu(x):
return np.maximum(0, x)
- 기울기가 1 or 0
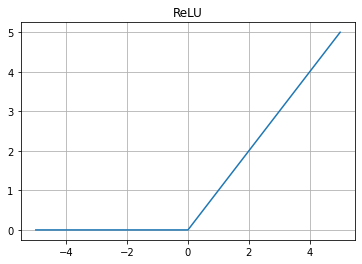
- Gradient가 vanising 되는 문제는 방지 가능
- 왜 0 밑은 0임?
- activation은 딥러닝 모델을 비선형으로 만들어줌
- 똑같이 y=x를 사용하면 linear regression이 됨
3. Leaky ReLU
def leakyrelu(x, a):
return np.maximum(a*x, x)
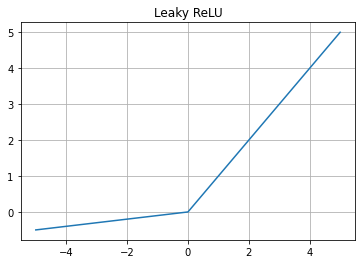
- Dying ReLU 현상 보완
- Dying ReLU
- backpropagation 도중 음수가 나오면 그뒤로는 0이 곱해져 업데이트가 되지않고 죽은 노드가 됨
- 신경망이 deep 해질 수록 죽는 노드가 많이 생김
- Dying ReLU
- 기울기: 양수일때 1, 음수일 때 a