Convolution Neural Network
1. Convolution
1.1 기본 공식
- Continuous: $ (f * g) (x) = \int_{R^d} f(z) g(x-z)dz = \int_{R^d} f(x-z) g(z)dz = (g * f)(x) $
- Discrete: $ (f * g) (i) = \sum_a f(a)g(i-a) = \sum_a f(i-a)g(a) = (g * f) (i) $
- 2d image: $ (I * K) (i,j) = \sum_{m,n} I(m,n)K(i-m,j-n) $
1.2 의미?
- 필터모양에 따라 결과가 달라진다
- Feature map
- Conv layer의 결과
- Filter의 개수와 동일
- 주의점
- Feature map의 크기 계산
- $(H, W) \rightarrow (K_H, K_W) \rightarrow (O_H, O_W)$
- $O_H = H - K_H + 1$
- $O_W = W - K_W + 1$
1.3 Convolution Neural Networks
- layer 종류
- Feature extraction
- Convolution layer
- pooling layer
- Decision making
- fully connected layer (E.g. 분류)
- 발전 동향
- 파라미터의 숫자가 많아질수록 학습이 어렵고 일반화 성능이 떨어진다!
- Conv layer를 deep 하게 가져가지만, 동시에 파라미터 수를 줄이기 위해 노력
- CNN 구성
- Stride
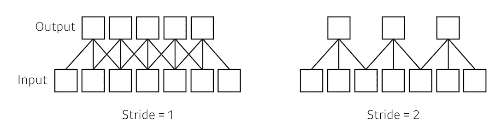
- Padding
- 가장자리를 계산할 수 없기 때문에
- 값을 덧대주는 역활
- 파라미터 수 계산
- E.g 1
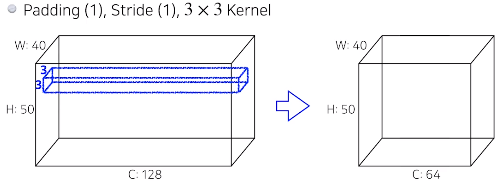
- $3 \times 3 \times 128 \times 64 = 73,728$
- $3 \times 3 \times 128$ : 필터 크기
- $64$ : 원하는 feature map 수
- E.g 2
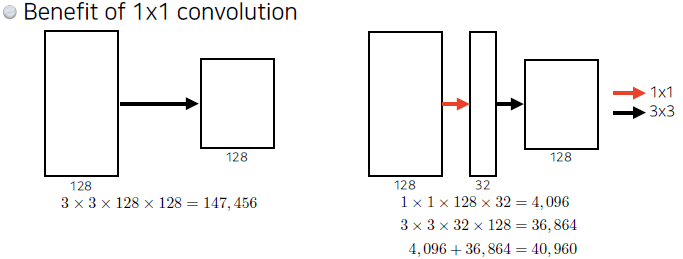
- 1x1 Convolution?
- Dimension reduction
- 깊이는 늘리고, 파라미터의 수는 줄일 수 있음!
- E.g. bottleneck architecture
2. Visual Recognition Challenge 주요 모델
2.0 ILSVRC
- ImageNet Large-Scale Visual Recognition Challenge
- Classification / Detection / Localization / Segmentation
- 1000 categories
- Over 1 million images
- Training set: 456,567 imgages
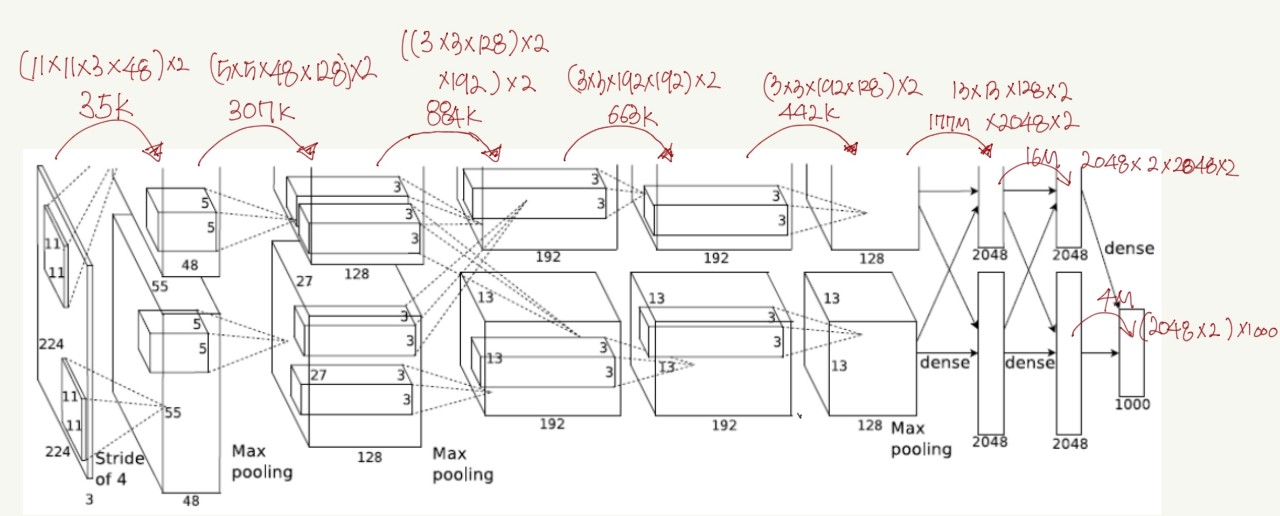
2.1 AlexNet
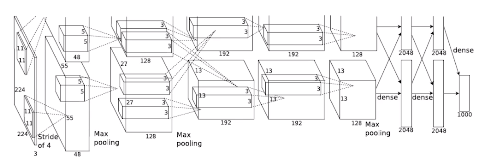
- ImageNet Classification with Deep Convolutional Neural Networks, NIPS, 2012
- 5 conv layers + 3 dense layers
- Key ideas
- ReLU activation: Gradient vanishing 방지
- GPI implementation (2 GPUs): 메모리 문제
- Local response normalization, Overlapping pooling
- Data augmentation
- Dropout
2.2 VGGNet
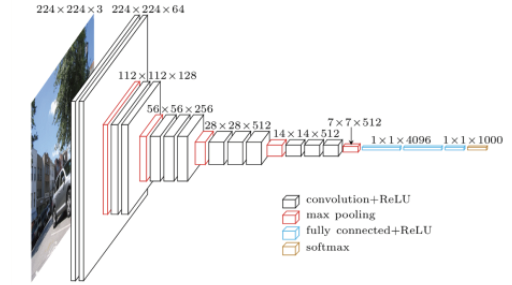
- 3x3 conv filter 만 사용 (stride 1)
- Receptive field: # of params
특정 위치의 픽셀들이 주변에 있는 픽셀들 하고만 상관관계가 높고, 위치가 멀수록 관계성이 떨어진다.
이러한 특성을 이용해 이미지 또는 영상을 분석하여 어떤 Task를 수행하려고 할 경우,
입력 이미지/영상 전체 영역에 대해 서로 동일한 중요도를 부여하여 처리하는 대신에 특정 범위를 한정해 처리를 하면 훨씬 효과적일 것이라는 것.
따라서, 큰 필터를 하나만 쓰는 것 보다, 작은 필더를 여러번 사용하는 것이 더 좋은 결과를 유도 할 수 있다.
- 큰 필터를 사용하는 것 보다 3x3 필터를 여러번 적용하는 것이 deep하면서 파라미터수를 줄일 수 있다
2.3 GoogLeNet
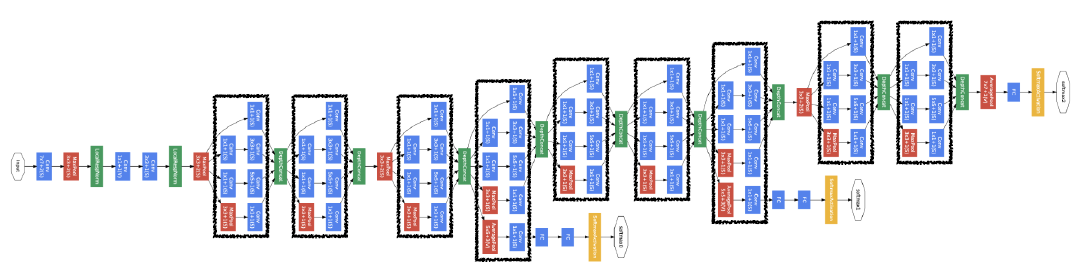
- Inception blocks
- 중간 중간 1x1 conv를 사용하면 parameter수를 잘 줄일 수 있다.
- channel-wise dimenstion reduction
2.4 ResNet
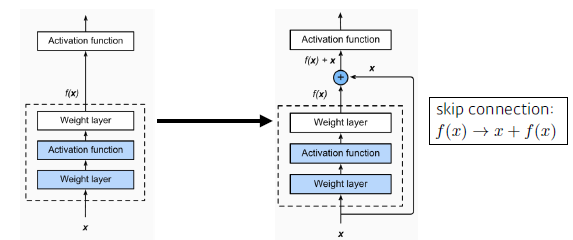
- 일반화 성능: training - test 성능 차이가 큼
- Skip connection
- 정보의 전달
- Deep 하게 쌓아도 성능 향상 가능하게 해줌
- Bottleneck architecture
- 1x1 conv를 활용해 입력차원을 줄였다 늘림
- receptive filed를 키우는 효과
2.5 Densnet

- Dense Block
- 각 layer concat
- chnnel의 수 증가, geometrically
- Transition Block
- BatchNorm -> 1x1 Conv -> 2x2 AvgPooling
- 차원 감소 효과
3. Computer Vision Applications
- 자율주행에 활용
- 앞에 있는 것이 자동차인지 사람인지 뭔지 판단
- How? convolutionalize
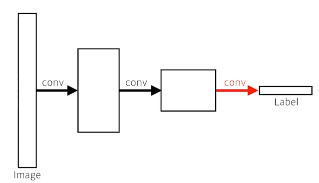
- Dense layer를 없애자
- heat map으로 ouput을 출력!
- Reolution이 떨어진 output을 늘리기 위한 방법이 필요
- Deconvolution (conv transpose)
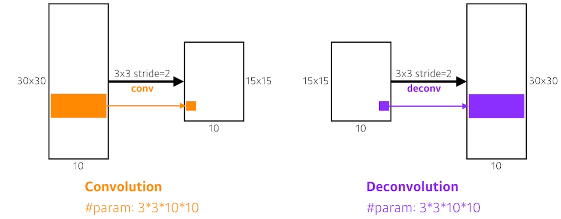
- 정확하게 역은 아니지만, 의미는 conv의 연산의 역
- unpooling
3.2 Detection
- R-CNN
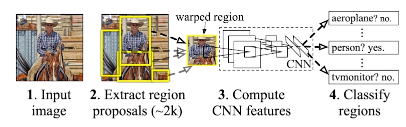
- 어느 위치에 어느 것이 있는지!
- 2000개의 이미지를 나누어 처리해야하는 문제 -> 너무 오래걸린다.
- SPPNet
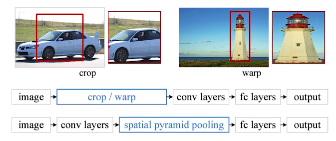
- 이미지에서 미리 bounding box 추출
- image 전체에 대해 feature map을 만들고,
- bounding box영역의 tensor를 가져와 사용
- R-CNN에 비해 빨라짐: CNN을 한번만 사용
- Fast R-CNN
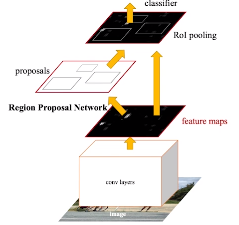
- SPPNet과 유사한 컨셉: 1개의 feature map
- Region Proposal Network
- bounding box안에 물체가 있을거 같은지 아닌지 판단
- YOLO(v1)
- Fast R-CNN 보다 빠름
- Region Proposal Network를 한번에 처리
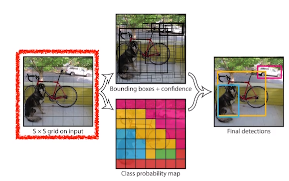
- SxS grid로 분할
- B개 바운딩 박스 예측 (x, y, w, h) + 쓸모있는 박스인지 예측
- 각 Cell을 C개 class 확률들 예측
