
1. Sequential Models
1.0 Sequential data
- 입력의 크기가 가변적이다
- 데이터가 언제 끝날지 알 수 없음
- 음성, 영상 등 많은 실제 데이터
1.1 Naive Sequnece Model
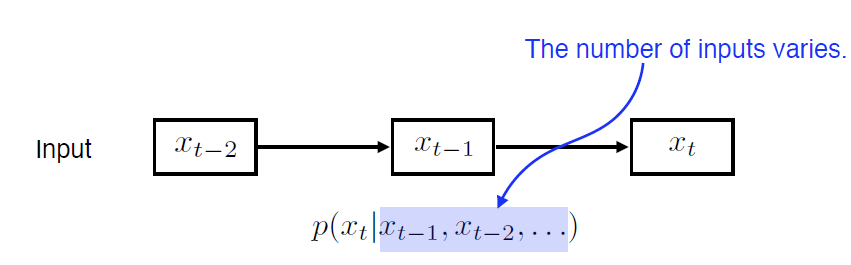
- 시간이 지날 수록 고려할 과거 데이터가 늘어남
1.2 Autoregressive Model
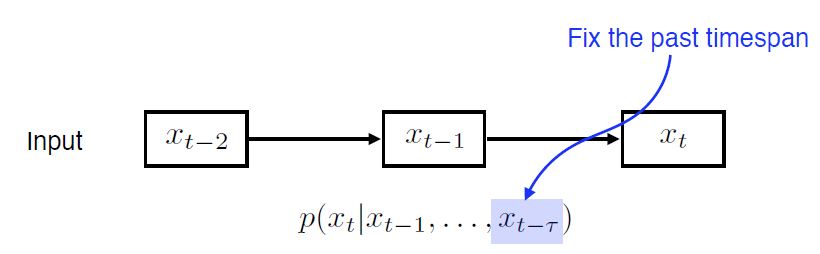
- $\rightarrow \tau$ 고정적인 크기로 설정. 항상 과거 몇 단계만 보겠다.
- 과거의 전체 데이터를 보는것 보다 계산이 용이해짐
1.3 Markov Model
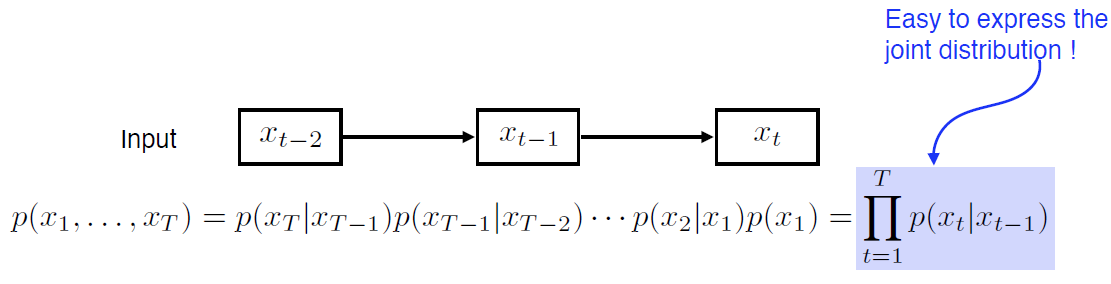
- first-order autoregressive model
- 과거의 한스텝만 보고 결정
- Markov
- 바로 전 과거에만 영향을 받는 다는 가정
- 현실과는 맞지 않는 가정
- But, joint distribution을 표현하기 용이
1.4 Latent Autoregressive Model
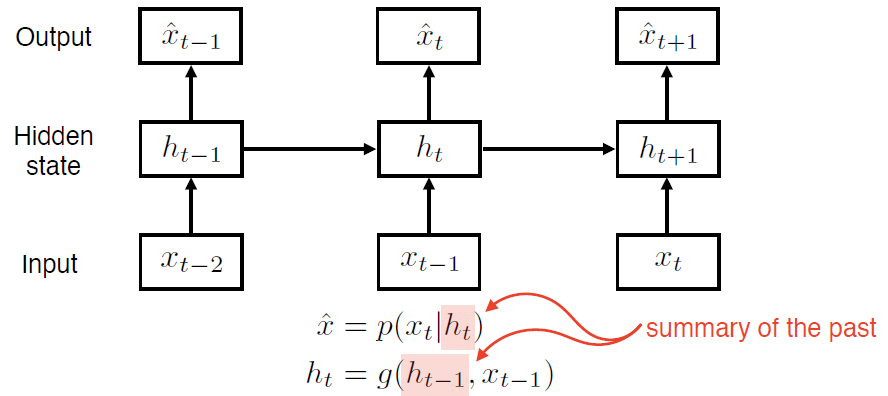
- Hidden state: 과거의 정보 summary
1.5 Recurrent Neural Network
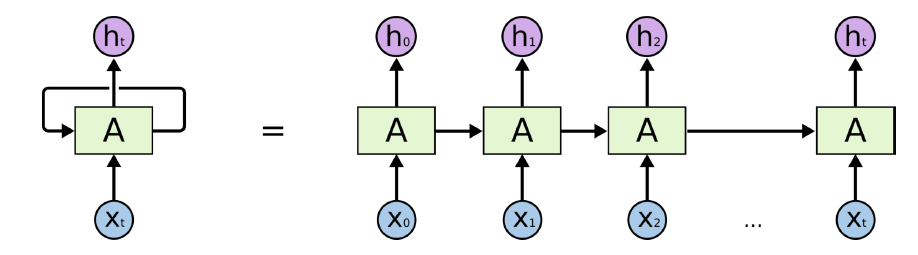
- 현재 입력과 이전 입력을 활용해 $h_t$ 가 계산된다.
- $h_t = f_W(h_{t-1}, x_t)$
- $h_{t-1}$ = 이전 hidden state 벡터
- $x_t$ = 동실 시간 step의 input 벡터
- $h_t$ = 새로운 hidden state 벡터
- $f_W$ = RNN function with parameters W
- E.g $tanh(W_{hh} h_{t-1} + W_{xh} x_t)$

- E.g $tanh(W_{hh} h_{t-1} + W_{xh} x_t)$
- $y_t$ = 시간 step t의 output 벡터
- Short-term dependencies / Long-term dependecies
몇 스텝 이전의 정보는 잘 고려할 수 있지만, 스텝이 길어 질 수록 정보가 희미해진다. 예를 들어, 음성인식을 진행하는 경우, 16KHz로 샘플링된 음성 신호의 경우 1초가 약 16,384 개의 원소를 가진 벡터가 된다(mono면 1차원, stereo면 2차원) 2초만 되도 약 3만 개가 되는 벡터가 되기 때문에, RNN을 사용하면 입력이 길어 질 수록 성능이 떨어지는 경향이 있다.
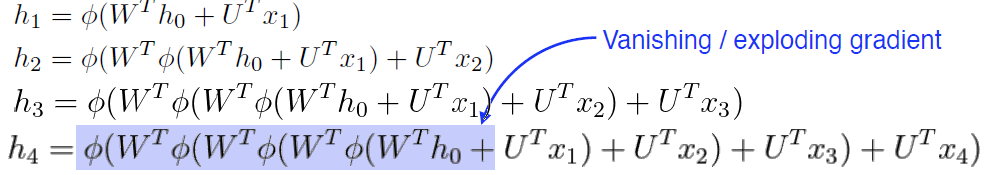
위 그림처럼 이전 hidden step의 결과가 계속 곱해지기 때문에 너무 커지거나 0이되어 제대로 정보정달이 되지 않기 때문이다.
2. RNN의 보완한 모델
2.1 Long Short Term Memory(LSTM)
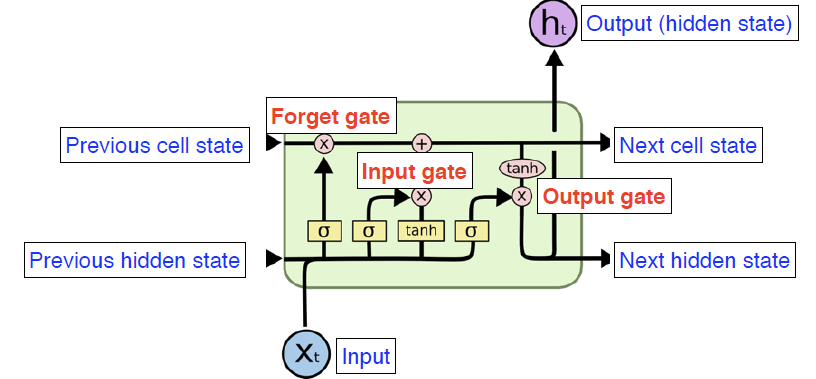
- Core idea 컨베이어 벨트위에 계속 데이터가 올라오는데, 어떤 부분이 필요하고 필요없는 지를 Gate들을 이용해 걸러낸다.
- Previous cell state: 0 ~ t 까지 Summaries 한 값
- Previous hidden state: 이전 스탭의 출력
- Gates
- Forget gate
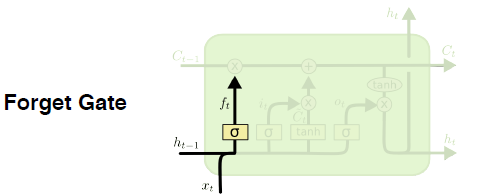
- $\sigma (W_f [h_{t-1}, x_t] + b_f)$
이전 스탭의 결과( $h_{t-1}$ )와 현재의 입력 $x_t$ 가 입력으로 사용된다. 결과로 $f_t$ 라는 값을 얻는데, sigmoid를 통과하기 때문에 항상 0 ~ 1 사이 값을 가진다. 즉, 입력인 두 값과 weight, 활성화 함수를 이용해 어떤 정보를 버리고 갈지 결정한다.
- $\sigma (W_f [h_{t-1}, x_t] + b_f)$
- Input gate
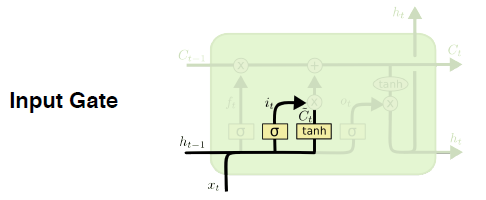
- $i_t = \sigma(W_i \cdot [h_{t_i}, x_t] + b_i)$
- $\bar C_t = tanh(W_c \cdot [h_{t_i}, x_t] + b_c$
어떤 정보를 Cell state에 올릴지 말지를 결정한다. $i_t$ 가 어떤 정보를 올릴지 결정 한다. $\bar C_t$ 가 이전 출력 값들을 활용해 만들어진 Cell state 예비후보이라고 할 수 있다. 이 예비후보들과 결정자 $i_t$ 를 잘 섞어 최종 결정을 해 Cell state에 정보를 더한다.
- Update Cell
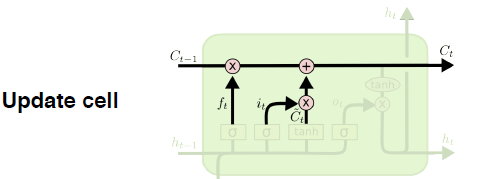
- $i_t = \sigma(W_i \cdot [h_{t_i}, x_t] + b_i)$
- $C_t = f_t * C_{t-1} + i_t * \bar C_t $
$f_t$ 만큼 이전 Cell state에서 버릴건 버리고, $i_t$ 만큼 $\bar C_t$ 에서 어느 값을 올릴지를 정한 값을 더해 현재의 Cell state로 업데이트
- Ouput gate
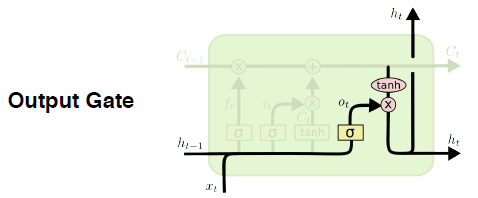
- $o_t = \sigma(W_o \cdot [h_{t_i}, x_t] + b_o)$
- $h_t = o_t * tanh(C_t)$
한번더 output을 가공해서 내보낸다.
- Forget gate
2.2 Gated Recurrent Unit
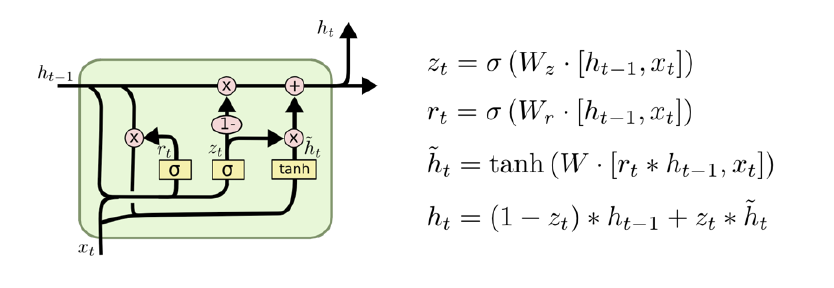
- reset gate와 update gate만 존재
- cell stat와 hidden state가 없음
- Tip
- Network parameter가 LSTM에 비해 적어, GRU가 종종 성능이 더 좋은 경향을 보인다. 하지만 요즘은 둘다 잘 안쓴다. Transformer…
3. Futher Question
- LSTM에서는 Modern CNN 내용에서 배웠던 중요한 개념이 적용되어 있습니다. 무엇일까요?
Modern CNN은 1x1 conv연산 등을 활용해 deep하게 쌓으면서도 파라미터를 줄이는 방향으로 발전해 왔습니다. 이와 유사하게 LSTM은 Gate들을 활용해 모든 파라미터를 다음 셀에 넘기는 것이 아니라 필요한 부분만 넘기도록 학습해 파라미터 수와 크기를 제어하려는 것이 특징입니다. 이러한 부분이 유사하게 적용된 부분이 아닐까 생각합니다. - Pytorch LSTM 클래스에서 3dim 데이터(batch_size, sequence length, num feature), batch_first 관련 argument는 중요한 역할을 합니다. batch_first=True인 경우는 어떻게 작동이 하게되는걸까요?
pytorch document에 다음과 같이 설명되어 있다. If True, then the input and output tensors are provided as (batch, seq, feature) instead of (seq, batch, feature). Note that this does not apply to hidden or cell states. - RNN NLP