
1. Sequential modeiling 문제
Sequential하게 입력이 사용되면, 중간에 데이터가 없거나, 잘 못된 경우 모델링이 매우 난해해진다.
2. Transformer
2.1 구조
![]()
- Transformer는 전체가 attention으로 이루어진 첫번째 sequence transduction 모델이다.
- 인코더와 디코더
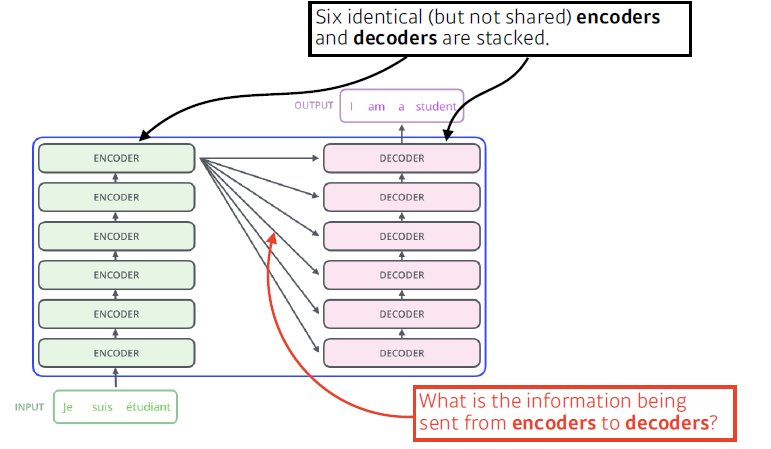
- Recursive 구조가 없음
- Self attention: N개의 단어를 한번에 처리 가능
- Why working?
하나의 입력이 고정되어 있다고 하더라도, 인코딩하려는 입력의 인코딩 벡터가 주변에 어떤 입력들에 따라 값이 달라지기 때문에 더 풍부한 정보를 표현할 수 있다. - 단점
1000개의 단어가 있으면 RNN은 1000번을 돌리면 오래걸리지만 언젠간 무언가를 얻을 수 있고, Transformer는 1000 x 1000 matrix가 필요하기 때문에 메모리를 많이 잡아먹는 다는 단점과 한계가 있다.
2.2 Encoder
2.2.1 Self-Attention
![]()
- 기본
- 인코더와 디코더의 Cornerstone
- 입력의 각 단어에 해당하는 feature vector를 찾아준다.
n개 단어가 주어지고 n개의 벡터를 찾아야 할때, r번째 벡터를 결정할 때 나머지 n-1개의 단어(벡터)를 모두 고려한다.
- Query, key, value
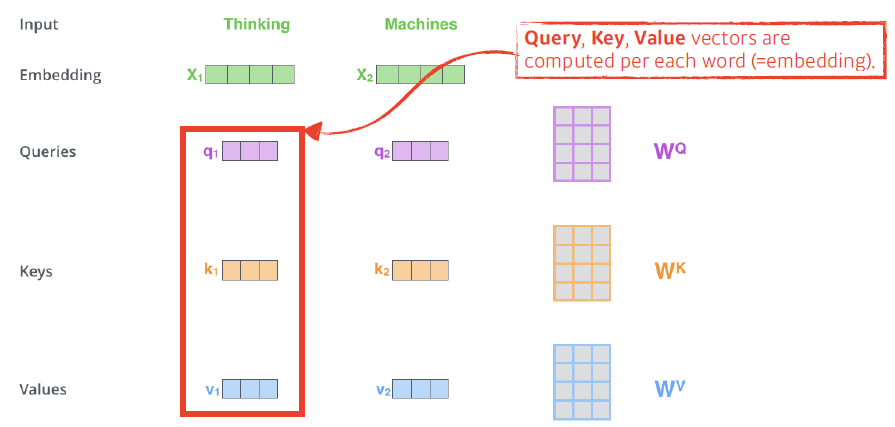
- E.g. Thingking(i 번째)과 Machines 라는 단어가 있을때,
- 단어마다 4개의 vector가 생성된다.
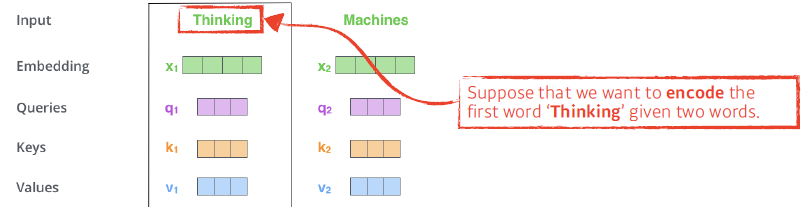 Embedding, Query, keys, Value 벡터 생성
Embedding, Query, keys, Value 벡터 생성 - Score vector 생성
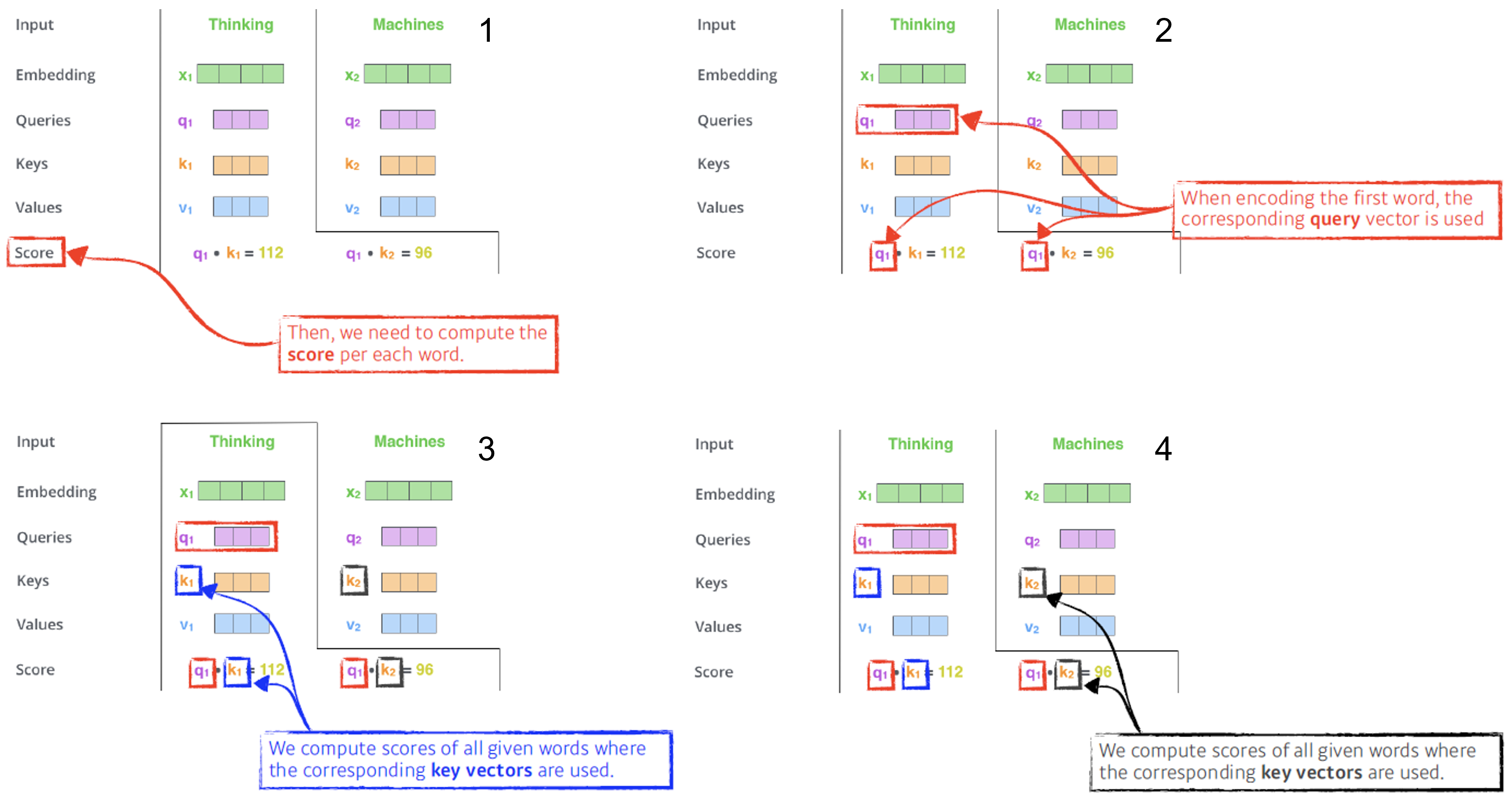
i번째 단어의 query vector와 나머지 모든 N개의 key 벡터를 내적. i번째 단어가 나머지 N개의 벡터와 얼마나 관계가 있는지를 학습하게 만들어 준다. 즉, 어떤 입력을 더 주의 깊게 볼지(어떤 단어를) 학습한다. - Score vector nomalize
값이 너무 커지지 않도록 - Softmax
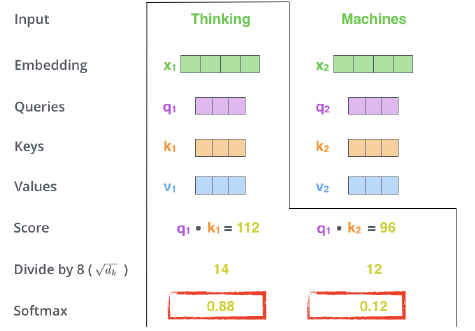
결과 Thinking과 Thingking의 관계는 0.88, Thinking과 Machines의 관계는 0.12가 된다. => Attention weight(Score) - value 벡터와 Attention weight의 weighted sum
최종적으로 i번째 단어의 인코딩된 벡터. 크기는 value 벡터와 동일(여기 에서만, multi head attention으로 가면 달라짐)
- 단어마다 4개의 vector가 생성된다.
- 행렬 연산으로 보기
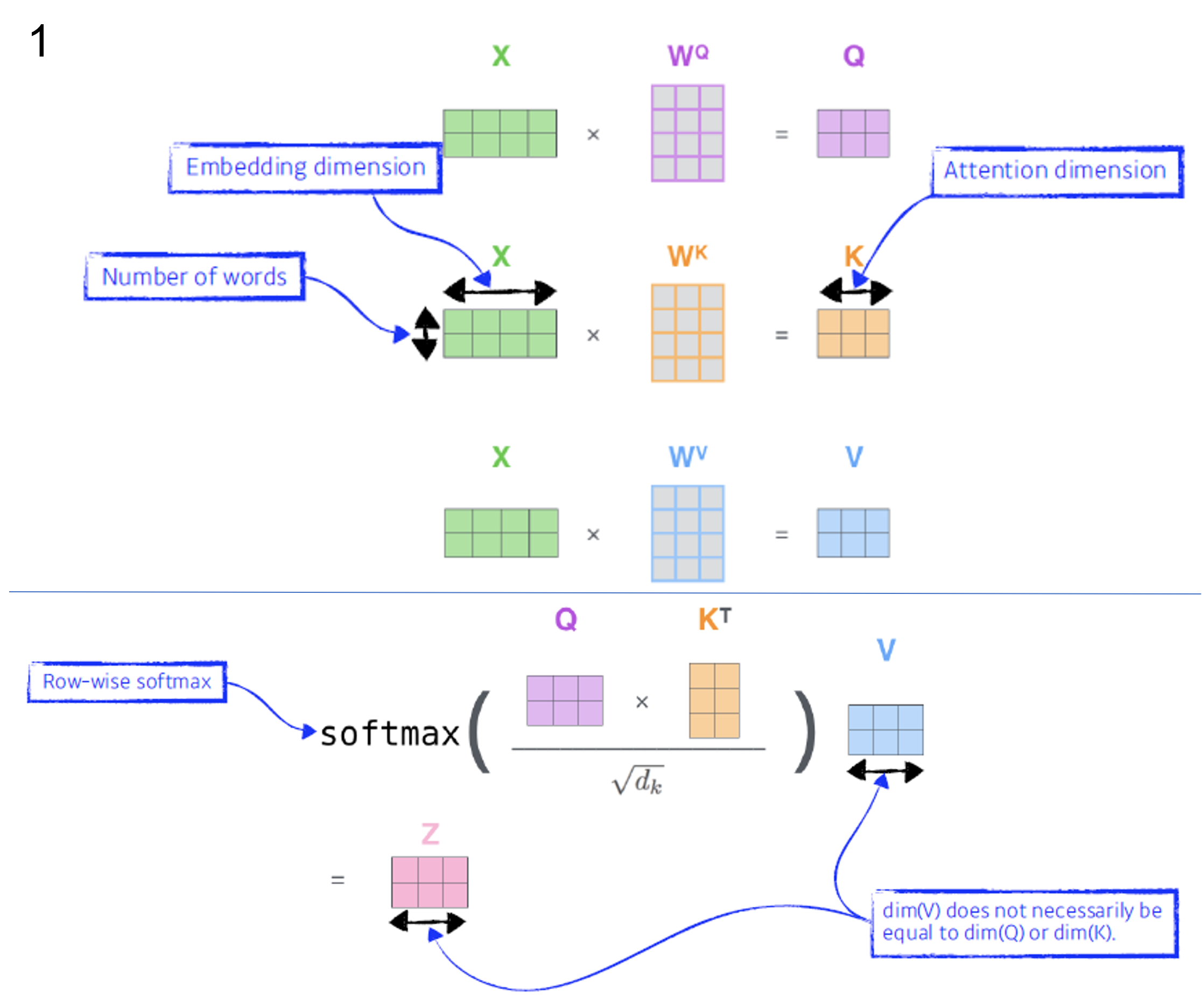
- E.g. Thingking(i 번째)과 Machines 라는 단어가 있을때,
2.2.2 Multihead-attention
- 기본 작동
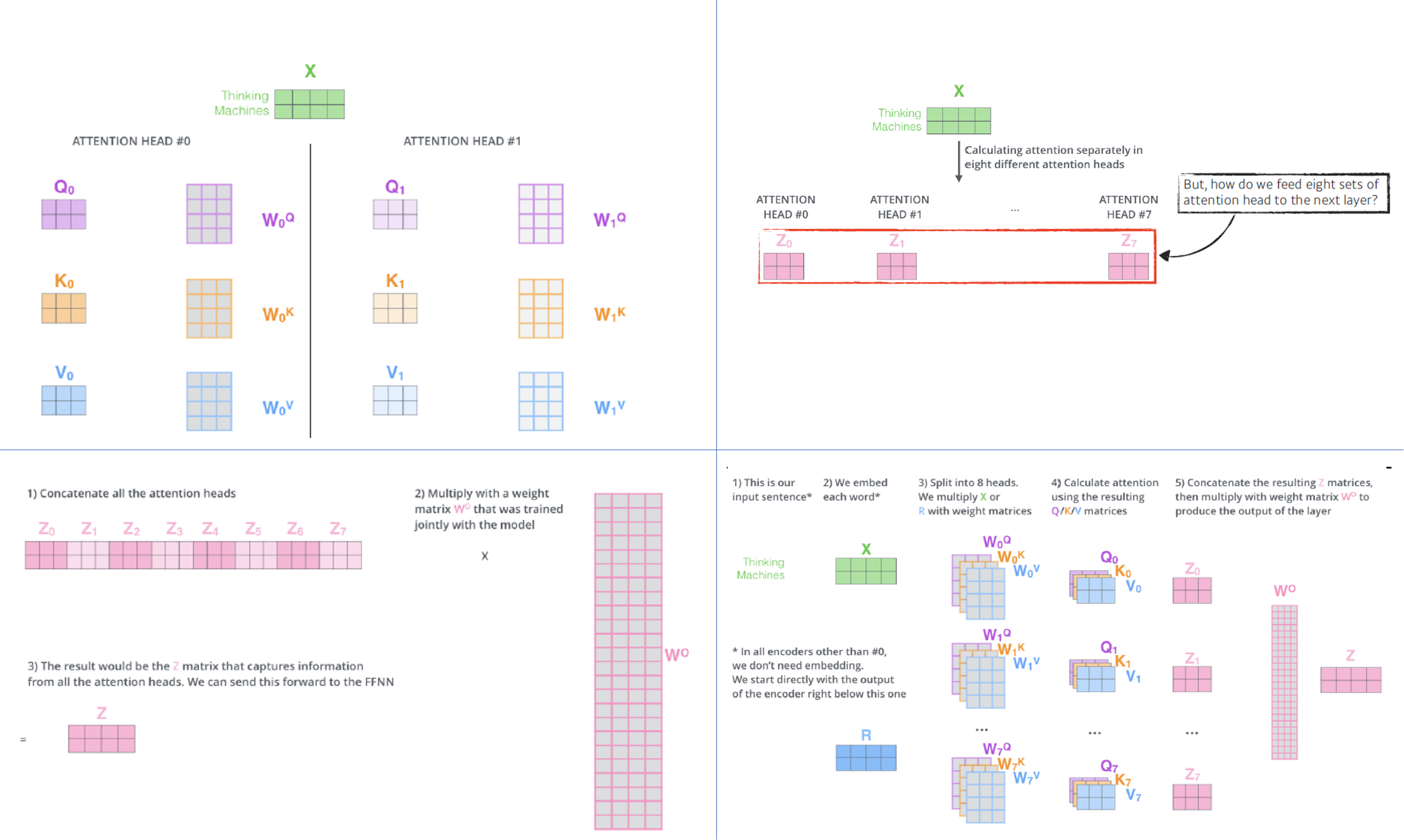
- Query, key, value를 N개 생성
- 즉, N번 attention을 반복 $\rightarrow$ N개의 인코딩 벡터
- 다음으로 넘어가기 위해 차원을 맞춰줄 필요가 있음
- $W_o$ 를 활용해 최종 $z$ 생성
- Position encoding
- Attention은 order에 independent한데, 실제로는 문장 내 단어의 순서가 중요하기 때문에 필요
- 위치에 따라 offset을 주어 특정 값을 더해줌
2.4 Decoder
![]()
- Encoder로 부터 어떤 정보를 받아야 하는가?
Input에 있는 단어들을 Decoder에 있는 출력하고자 하는 단어들에 대해, attention map을 만들기 위해서는 Input에 해당하는 key와 value 벡터가 필요하다. 디코더의 입력으로 들어가는 단어들의 query 벡터와 인코더로 부터 받은 key와 value 벡터를 활용해 최종 결과를 만든다. - 학습시에는 디코더에 입력으로 정답을 넣어준다
- 예를들어 번역 테스크의 경우, 디코더에서 정답에 대한 query 벡터들을 활용한다.
3. Vision Transformer
![]()
이미지 분류를 할때 인코더를 활용. 이미지를 분할해 sub 영역을 하나의 단어처럼 사용해서 Transformer 구조를 응용한것
DALL-E -> 대표적인 모델 중 하나