
0. 강의 소개
이번 강의에서는 여러분들이 학습시킨 모델을 어떻게 프로덕트 단으로 서빙을 할 수 있는지에 대한 전반적인 내용을 다루고 있습니다. 실질적인 프로그래밍은 다음 파트에서 진행될 예정이지만, 미리 전체적인 큰 그림을 그릴 수 있도록 이번 강의를 집중해서 학습해주시길 바라겠습니다.
1. Model Serving
1.1 Serving Basic
- 정기 배송처럼 매 주기마다 받길 원하는 경우
- Batch serving
- 주문하자마자 만들어서 전달 하는 경우
- Online serving
- Serving?
- Production(real world)에서 모델을 사용할 수 있도록 배포
- 모델을 개발, 앱 또는 웹에서 사용할 수 있도록 만드는 것
- 서비스화
- 크게 2가지
- Online
- Batch
- 그외에 클라이언트(모바일 기기, IoT 장치 등)에서의 Edge serving도 존재
1.2 용어 정리!
- Serving : 모델을 웹/앱 서비스에 배포하는 과정, 모델을 활용하는 방식, 모델을 서비스화 하는 관점
- Inference : 모델에 데이터가 제공되어 예측하는 경우, 사용하는 관점
- Serving-Inference 용어가 혼재되어 사용되는 경우도 존재
- Online Serving / Online Inference
- Batch Serving / Batch Inference
2. Online Serving
2.1 Web Server Basic
- 웹 서버
- HTTP를 통해 웹 브라우저에서 요청하는 HTML 문서나 오브젝트를 전송해주는 서비스 프로그램
- 요청(request)을 받으면 요청한 내용을 보내주는(response) 프로그램
- 어렵다! 타코 가게로 돌아가자!
- 손님이 직원에게 메뉴판을 달라고 요청
- 손님: Client
- 직원: Server
- 메뉴판을 달라고 요청: Request
- 직원이 메뉴판을 찾아서 전달
- 메뉴판을 찾아서 전달: Response
- 손님이 직원에게 타코 주문 요청
- 타코 주문: Request
- 직원이 요리사에게 타코 주문이 왔음을 알림
- 요리사가 타코를 만들면, 직원이 손님에게 타코를 전달
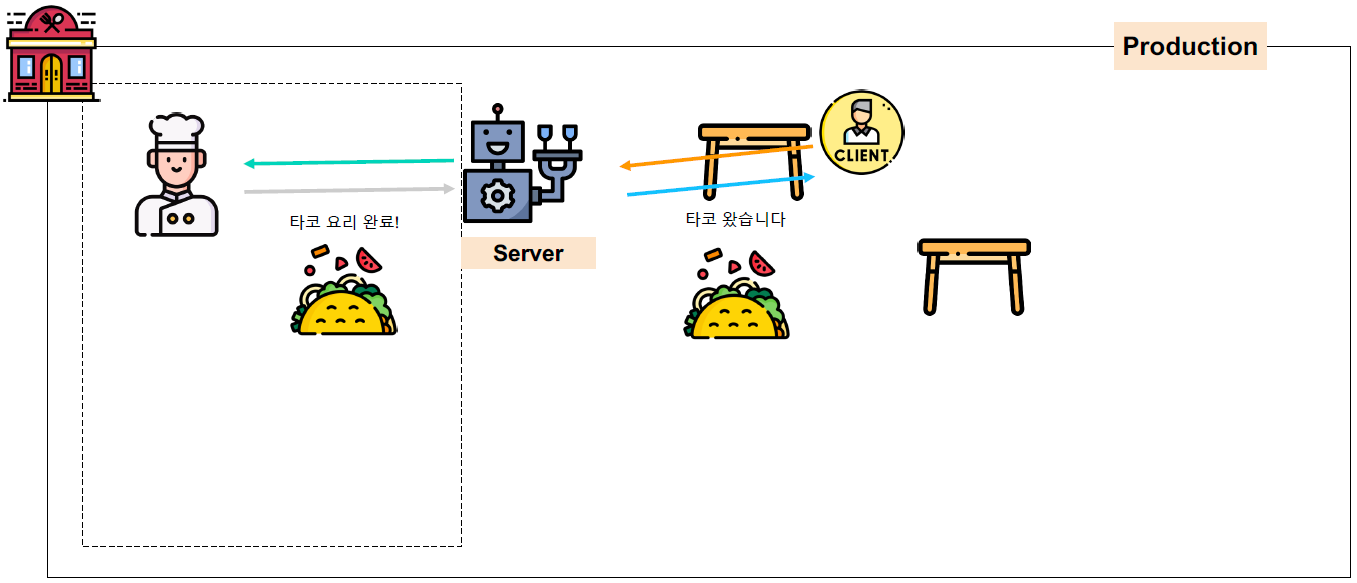
- 타코를 전달: Response
- 손님이 직원에게 메뉴판을 달라고 요청
- 다양한 Client의 요청을 처리해주는 것이 web server!
- 주문 받기, 신규 고객 응대, 계산 등
- Machine learning sever는 client의 다양한 요청을 처리!
- 데이터 전처리, 모델을 기반으로 예측 등

- 데이터 전처리, 모델을 기반으로 예측 등
2.2 API(Application Programming Interface)
- 정의
- 운영체제나 프로그래밍 언어가 제공하는 기증을 제어할 수 있게 만든 인터페이스
- 예시
- 특정 서비스에서 해당 기능을 사용할 수 있도록 외부에 노출: 기상청 API, 지도 API
- 카카오, 구글, 네이버, …
- 라이브러리의 함수: Pandas, Tensorflow, PyTorch
- 특정 서비스에서 해당 기능을 사용할 수 있도록 외부에 노출: 기상청 API, 지도 API
- 자세한 내용은 다음 포스팅에서
- !!포스팅시 링크 달기!!
2.3 Online Serving Basic
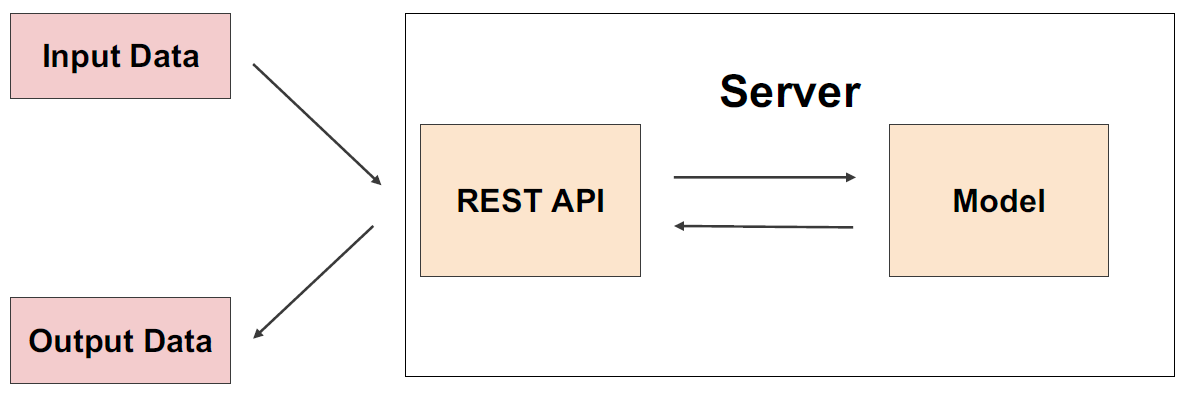
- 요청을 실시간으로 예측
- 클라이언트(애플리케이션)에서 ML 모델 서버에 HTTP 요청, 서버작업 후, 예측값 반환
- 단일 데이터를 받아 실시간으로 예측하는 예제
- 기계 고장 예측 모델
- 센서의 실시간 데이터를 활용, 특정 기계 부품이 앞으로 얼마 뒤에 고장날지 아닐지 예측
- 음식 배달 소요 시간 예측
- 해당 지역의 과거 평균 배달 시간, 실시간 교통 정보, 음식 데이터 등을 기반으로 시간 예측
- 기계 고장 예측 모델
- 서버 사용 방식
- ML 모델 서버에 요청할 때, 필요시 ML 모델 서버에서 데이터 전처리를 해야할 수 있음
- 전처리 / 모델 서버를 따로 둘 수도 있음
- 서비스의 서버에 ML 서버를 포함하는 경우도 있고, 따로 두는 경우도 존재
- 회사에서 개발 조직과 데이터 조직의 협업하는 방식에 따라 다르게 개발 가능
- ML 모델 서버에 요청할 때, 필요시 ML 모델 서버에서 데이터 전처리를 해야할 수 있음
- Online serving 구현 방식
- 직접 API 웹 서버 개발
- Flask, FastAPI 등을 사용해 서버 구축

- Flask, FastAPI 등을 사용해 서버 구축
- 클라우드 서비스 활용
- AWS의 SageMaker, GCP의 Vertext AI 등
- 하지만 서비스에 익숙해져야하고, 비용이 나간다.
- Serving 라이브러리 활용
- Tensorflow Serving, Troch Serve, MLFlow, BentoML 등
- 추상화된 패턴을 잘 제공하는 오픈소스를 활용하는 방식
- BentoML 예시

- 직접 API 웹 서버 개발
- Online serving에서 고려할 부분
- Python 버전, 패키지 버전 등 dependency가 굉장히 중요
- 재현 가능하지 않으면 Risk가 크다
- Virtualenv, Poetry, Docker를 활용
- 실시간 예측 -> Latency 최소화
- Input 데이터를 기반으로 Database에 있는 데이터를 추출해서 모델 예측해야 하는 경우
- 데이터를 추출하기 위해 쿼리를 실행하고, 결과를 받는 시간이 소요
- 모델이 수행하는 연산
- 경량화하는 작업이 필요, 간단한 모델 사용
- 결과 값에 대한 보정이 필요한 경우
- 유효하지 않은 예측값이 반환될 경우 따로 처리가 필요
- Input 데이터를 기반으로 Database에 있는 데이터를 추출해서 모델 예측해야 하는 경우
3. Batch Serving
3.1 Batch Serving Basic
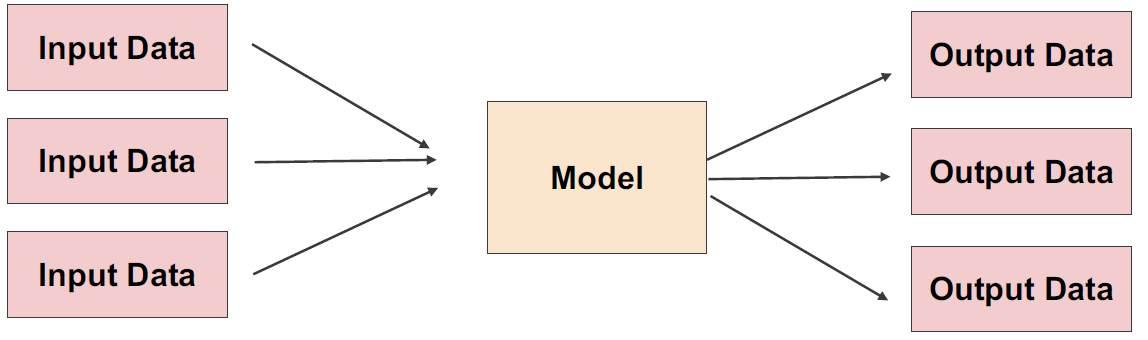
- 주기적으로 학습을 하거나 예측을 하는 경우
- Batch 묶음(30분의 데이터)를 한번에 예측
- 모델의 활용방식에 따라 주기는 달라진다.
- Airflow, Cron Job 등으로 스케쥴링 작업(Workflow Scheduler)
- Batch Serving Basic - 예시
- 추천 시스템 : 1일 전에 생성된 컨텐츠에 대한 추천 리스트 예측
- 1시간 뒤 수요 예측
- 실시간이 필요 없는 대부분의 방식에서 활용 가능
- 스포티파이의 예측 알고리즘 - Discover Weekly
- Batch Serving Basic - 장점
- Online Serving보다 구현이 수월하며, 간단함
- Latency가 문제되지 않음
- Batch Serving Basic - 단점
- 실시간 활용 불가능
- Cold Start 문제 : 오늘 새로 생긴 컨텐츠는 추천할 수 없음
- 활용가능한 라이브러리
- 데이터 엔지니어링에서 자주 활용되는 Airflow
- Linux의 Cron Job
- Awesome Workflow Engines Github
3.2 Online Serving vs Batch Serving
- Online vs Batch를 선택하는 기준 - Input 관점
- 데이터 하나씩 요청하는 경우 : Online
- 여라가지 데이터가 한꺼번에 처리되는 경우 : Batch
- Online vs Batch를 선택하는 기준 - Output 관점
- API 형태로 바로 결과를 반환해야 하는 경우 : Online
- 서버와 통신이 필요한 경우 : Online
- 1시간에 1번씩 예측해도 괜찮은 경우 : Batch
4. 더 읽어보면 좋은 문서
- https://developers.google.com/machine-learning/guides/rules-of-ml
- Online Serving / Batch Serving 기업들의 Use Case 찾아서 정리해보기
5. Special Mission
- Rules of Machine Learning: Best Practices for ML Engineering 문서 읽고 정리하기!
- Online Serving / Batch Serving 기업들의 Use Case 찾아서 정리하기 (어떤 방식으로 되어 있는지 지금은 이해가 되지 않아도 문서를 천천히 읽고 정리하기)
Reference
- AI boot camp 2기 서빙 강의