
0. 강의 소개
Logging은 실제 모델 혹은 서비스를 분석하고, 개선, 유지보수 하기 위해서 반드시 필요한 개념입니다. 이번 강의에서는 데이터, Python의 Logging module, Online Serving Logging 등을 통해 Logging을 다룰 예정입니다.
1. Logging Basics
1.1 로그란?
- 로그의 어원
- 통나무
- 과거 선박의 속도를 측정하기 위해 칩 로그라는 것을 사용
- 배의 앞에서 통나무를 띄워서 배의 선미까지 도달하는 시간을 재는 방식에 로그를 사용
- 요즘엔 컴퓨터에 접속한 기록, 특정 행동을 한 경우 남는 것을 로그라고 부름
- 데이터는 이제 우리의 삶 어디에서나 존재
- 앱을 사용할 때마다 우리가 어떤 행동을 하는지 데이터가 남음
- 이런 데이터를 사용자 로그 데이터, 이벤트 로그 데이터 등으로 부름
- 위처럼 머신러닝 인퍼런스 요청 로그, 인퍼런스 결과를 저장해야 함
- 데이터 종류
- 데이터베이스 데이터(서비스 로그, Database에 저장)
- 서비스가 운영되기 위해 필요한 데이터
- 예) 고객이 언제 가입했는지, 어떤 물건을 구입했는지 등
- 사용자 행동 데이터(유저 행동 로그, 주로 Object Storage, 데이터 웨어하우스에 저장)
- 유저 로그라고 지칭하면 사용자 행동 데이터를 의미
- 서비스에 반드시 필요한 내용은 아니고, 더 좋은 제품을 만들기 위해 또는 데이터 분석시 필요한 데이터
- 앱이나 웹에서 유저가 어떤 행동을 하는지를 나타내는 데이터
- UX와 관련해서 인터랙션이 이루어지는 관점에서 발생하는 데이터
- 예) Click, View, 스와이프 등
- 인프라 데이터(Metric) -> 값을 측정할 때 사용
- 백엔드 웹 서버가 제대로 동작하고 있는지 확인하는 데이터
- Request 수, Response 수
- DB 부하 등
- 데이터베이스 데이터(서비스 로그, Database에 저장)
1.2 데이터 적재 방식
- Database(RDB)에 저장하는 방식
- 다시 웹, 앱 서비스에서 사용되는 경우 활용
- 실제 서비스용 Database
- 관계형 데이터베이스(Relational Database)
- 행과 열로 구성
- 데이터의 관계를 정의하고, 데이터 모델링 진행
- 비즈니스와 연관된 중요한 정보
- 예) 고객 정보, 주문 요청
- 영구적으로 저장해야 하는 것은 데이터베이스에 저장
- 데이터 추출시 SQL 사용
- MySQL, PostgreSQL 등
- Database(NoSQL)에 저장하는 방식
- Elasticsearch, Logstash or Fluent, Kibana에서 활용하려는 경우
- 스키마가 Strict한 RDBMS와 다르게 스키마가 없거나 느슨한 스키마만 적용
- Not Only SQL
- 데이터가 많아지며 RDBMS로 트래픽을 감당하기 어려워서 개발됨
- 일반적으로 RDBMS에 비해 쓰기와 읽기 성능이 빠름
- Key Value Store, Document, Column Family, Graph 등
- JSON 형태와 비슷하며 XML 등도 활용됨
- Object Storage에 저장하는 방식
- S3, Cloud Storage에 파일 형태로 저장
- csv, parquet, json 등
- 별도로 Database나 Data Warehouse로 옮기는 작업이 필요
- 어떤 형태의 파일이여도 저장할 수 있는 저장소
- AWS S3, GCP Cloud Storage 등
- 특정 시스템에서 발생하는 로그를 xxx.log에 저장한 후, Object Storage에 저장하는 형태
- 비즈니스에서 사용되지 않는 분석을 위한 데이터
- 이미지, 음성 등을 저장
- Data Warehouse에 저장하는 방식
- 데이터 분석시 활용하는 데이터 웨어하우스로 바로 저장
- 여러 공간에 저장된 데이터를 한 곳으로 저장
- 데이터 창고
- RDBMS, NoSQL, Object Storage 등에 저장된 데이터를 한 곳으로 옮겨서 처리
- RDBMS와 같은 SQL을 사용하지만 성능이 더 좋은 편
- AWS Redshift, GCP BigQuery, Snowflake 등
1.3 저장된 데이터 활용 방식
- 예시 1.
- “image.jpg”로 마스크 분류 모델로 요청했다
- image.jpg를 중간에 Object Storage에 저장하면 실제로 우리가 볼 때의 실제 Label과 예측 Label을 파악할 수 있음
- “image.jpg” 같은 이름의 이미지로 10번 요청했다
- 같은 이미지로 예측한다고 하면 중간에 저장해서 기존에 예측한 결과를 바로 Return할 수 있겠다(Redis 등을 사용해 캐싱)
- Feature = [[2, 5, 10, 4]] 으로 수요 예측 모델로 요청했다
- 어떤 Feature가 들어오는지 알 수 있고, Feature를 사용할 때 모델이 어떻게 예측하는지 알 수 있음
- 현재 시스템이 잘 동작하는지 알 수 있음
- “image.jpg”로 마스크 분류 모델로 요청했다
- 데이터가 저장되어 있지 않다면
- 과거에 어떤 예측을 했는지 알 수 없음
- print 문의 로그를 저장한 곳을 찾아서 확인해야 함(Linux 서버에 접속하거나)
- 모델이 더 발전하기 위한 개선점을 찾기 어려움
- 현재 시스템이 잘 동작하고 있는지 알기 어려움
2. Logging in Python
2.1 Python Logging Module
- 파이썬의 기본 모듈, logging
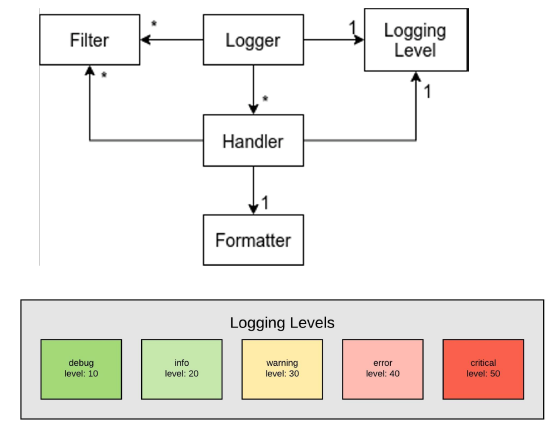
- 심각도에 따라
- info, debug, error, warning 등 다양한 카테고리로 데이터 저장 가능
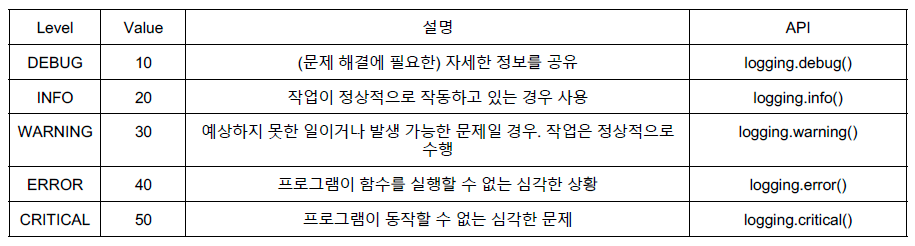
- info, debug, error, warning 등 다양한 카테고리로 데이터 저장 가능
- Logging level을 WARNING으로 설정하면,
- 그 상위 WARNING, ERROR, CRITICAL 만 보여줌
- 심각도에 따라
- logging vs print
- print는 콘솔에만 저장됨
- logging은 file 등의 output으로 저장할 수 있어, 언제 어디서든 확인 가능
-
logging config
logger_config = { "version": 1, # required "disable_existing_loggers": True, # 다른 Logger를 overriding 합니다 "formatters": { "simple": {"format": "%(asctime)s | %(levelname)s - %(message)s"}, }, "handlers": { "console": { "level": "DEBUG", "class": "logging.StreamHandler", "formatter": "simple", } }, "loggers": {"example": {"level": "INFO", "handlers": ["console"]}}, }
2.2 Logger
- log를 생성하는 Method 제공
- logger.info() 등
- 사용법
- name이 주어지면 해당 name의 logger 사용하고, name이 없으면 root logger 사용
- 마침표로 구분되는 계층 구조
logging.getLogger('foo.bar') # foo의 자식 logger bar 반환
2.3 Handler
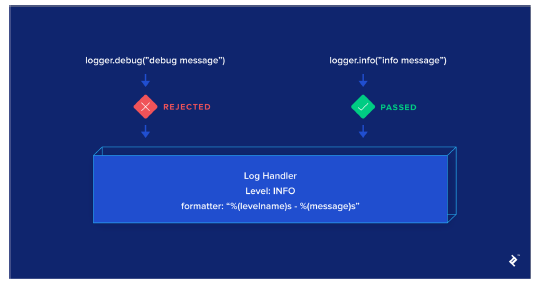
- Logger에서 만들어진 Log를 적절한 위치로 전송
- 파일 or 콘솔
- Level과 Formatter를 각각 설정해서 필터링 할 수 있음
-
StreamHandler, FileHandler, HTTPHandler 등
import logging dynamic_logger = logging.getLogger() log_handler = logging.StreamHandler() formatter = logging.Formatter("%(asctime)s | %(name) | %(levelname)s - %(message)s") log_handler.setFormatter(formatter) dynamic_logger.addHandler(log_handler) dynamic_logger.info("hello world")
2.4 Formatter
- 최종적으로 Log에 출력될 Formatting 설정
- 시간, Logger 이름, 심각도, Output, 함수 이름, Line 정보, 메시지 등 다양한 정보 제공
2.5 Logging Flow
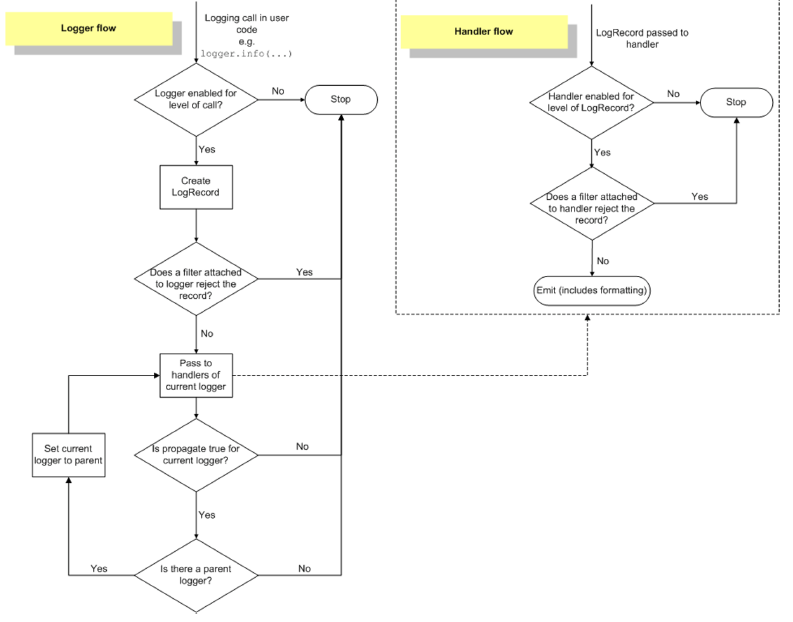
3. Online Serving Logging(BigQuery)
3.1 BigQuery 데이터 구조
- BigQuery에 Online Serving Input과 Output 로그 적재
- 빅쿼리 테이블을 세팅합니다
- 빅쿼리에 적재하기 쉽게 JSON 형태로 로그를 정제 -> pythonjsonlogger를 사용
- python logging 모듈을 사용해서 빅쿼리에(실시간) 로그 적재(file과 console에도 남을 수 있도록 handler를 지정)
#### JSON Logging import logging from pythonjsonlogger import jsonlogger logger = logging.getLogger() logHandler = logging.StreamHandler() formatter = jsonlogger.JsonFormatter() logHandler.setFormatter(formatter) logger.addHandler(logHandler) logger.info("hello world") - BigQuery
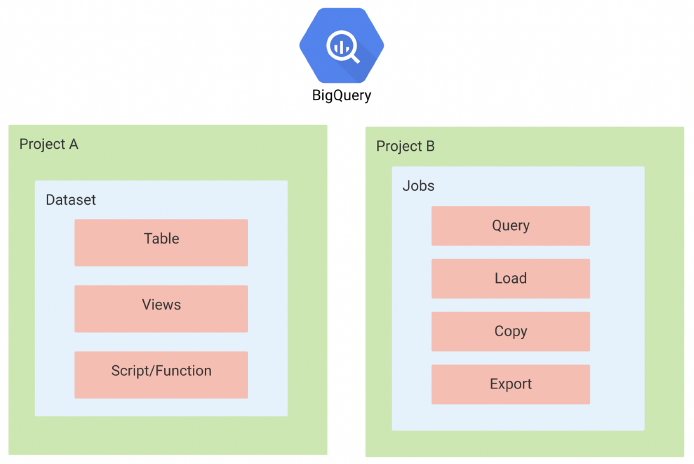
- Google Cloud Platform의 데이터 웨어하우스
- 데이터 분석을 위한 도구로 Apache Spark의 대용으로 활용 가능
- Firebase, Google Analytics 4와 연동되어 많은 회사에서 사용 중
- Dataset, Table, View 등
3.2 BigQuery 데이터세트 만들기
- GCP Console에서 BigQuery 접근 - API 사용 - 데이터 세트 만들기 클릭
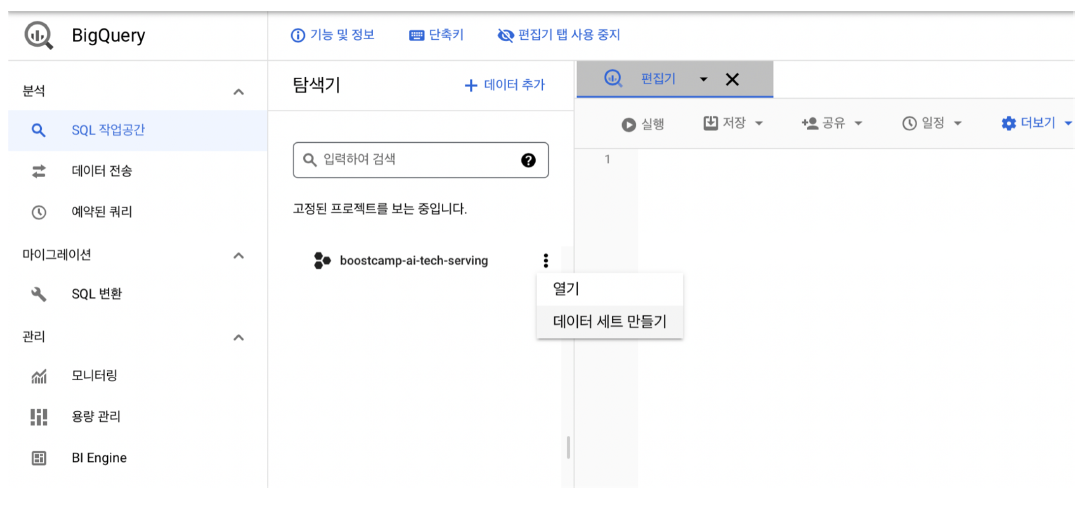
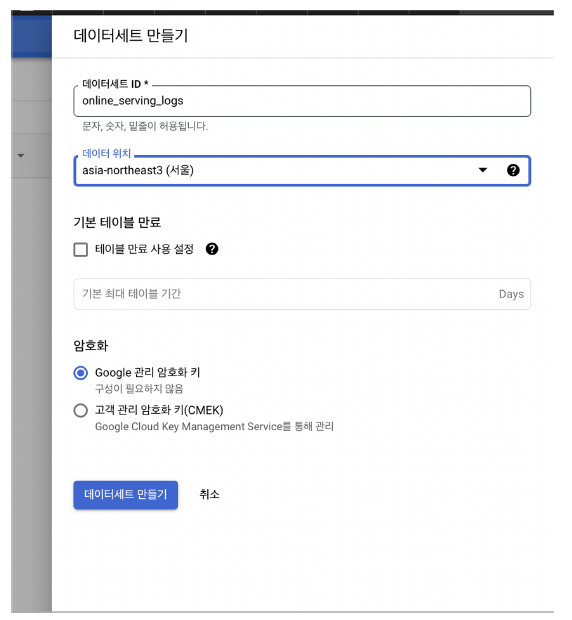
- 적절한 이름의 데이터세트 생성
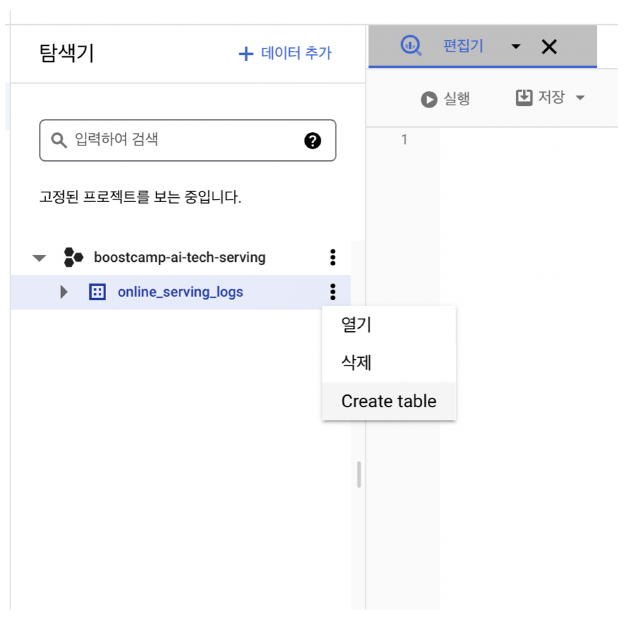
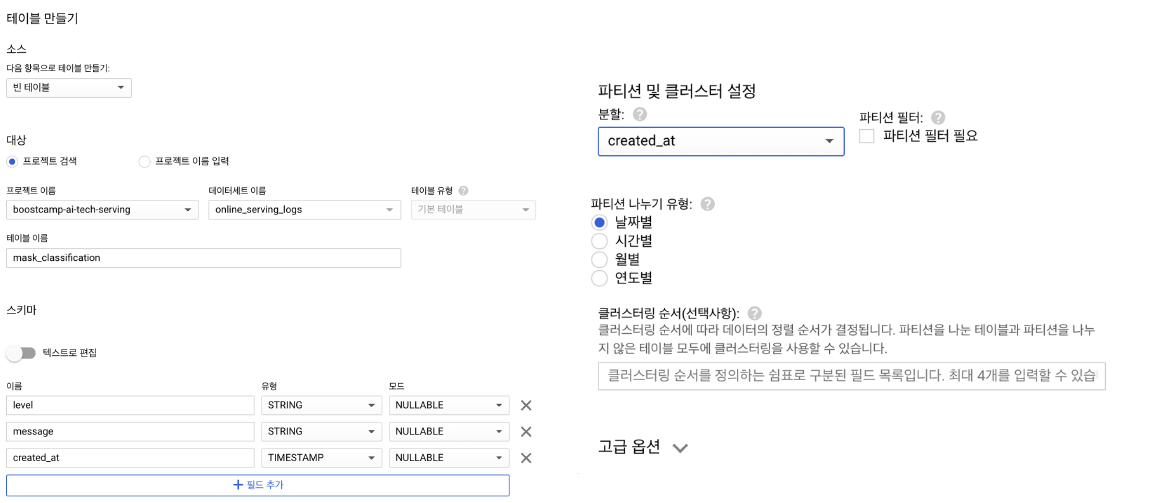
- 방금 생성한 online_serving_logs 데이터셋에서 Create Table 클릭
- 파티션 설정 : 빅쿼리는 데이터를 조회할 때 모든 데이터를 조회하지 않고 일부를 조회하기 때문에 비용을 줄이기 위한 방법
3.3 BigQuery로 실시간 로그 데이터 수집하기
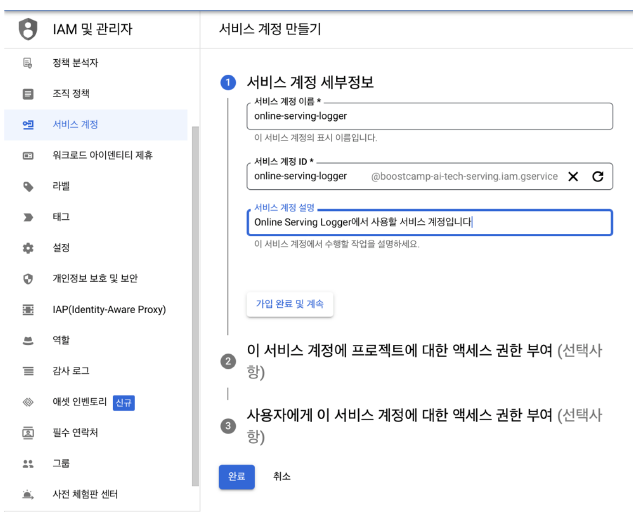
- 빅쿼리 데이터 로깅을 위해 서비스 계정 생성 (다른 강의에서 만든 서비스 계정에 BigQuery 권한을 주는 것도 괜찮음)
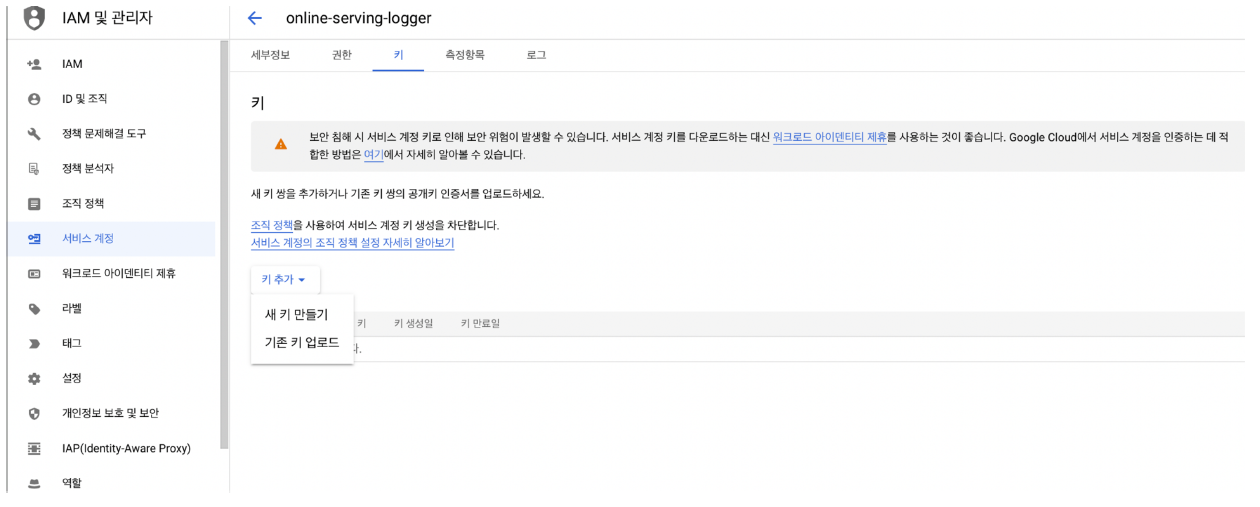
- 새 키 만들기 - JSON Key 다운
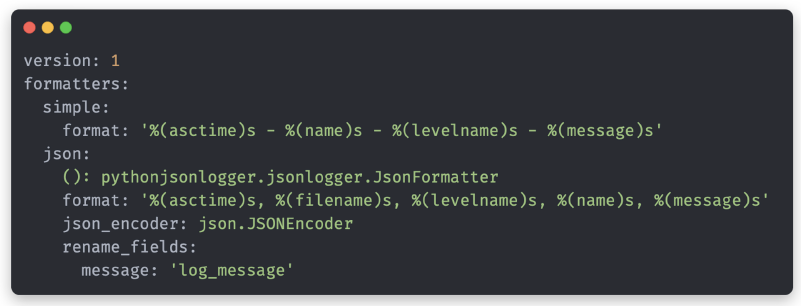
- config.yaml 파일에 formatter에 대한 구성 설정
- simple : 일반 포맷팅
- json : json으로 로그를 변환
()는 logger config에서 사용할 클래스를 지정 - pythonjsonlogger의 JsonFormatter 클래스를 사용하면 일반 텍스트를 json으로 변환.
- logging.getLogger로 해당 config가 적용된 logger를 만들어 줄 수 있음
- 빅쿼리 핸들러 추가
- 빅쿼리 핸들러에는 BigqueryHandlerConfig라는 클래스로 관련 설정들을 만들고, 주입 윗 부분에서 만든 logger에 BigqueryHandler를 추가
- Pydantic 커스텀 클래스를 사용하기 위해 arbitrary_types_allowed True
-
예시
if __name__ == "__main__": from pathlib import Path here = Path(__file__) config_yaml_path = os.path.join(here.parent, "config.yaml") logger = get_ml_logger( config_path=config_yaml_path, credential_json_path="서비스 계정 JSON 파일 경로", # FIXME table_ref="빅쿼리 테이블 주소", # FIXME: e.g., boostcamp-ai-tech-serving.online_serving_logs.mask_classification ) for _ in range(10): logger.info("hello world")
3. Special Mission
- 앞서 만들었던 프로토타입에 실시간 데이터 적재 파이프라인 추가하기(Input 포함)
- 만약 이미지 데이터라면 이미지 데이터는 Cloud Stoage에 저장하는 과정 추가하기
- BigQuery 학습하기(참고 자료 : https://zzsza.github.io/bigquery/)
Reference
- AI boot camp 2기 서빙 강의