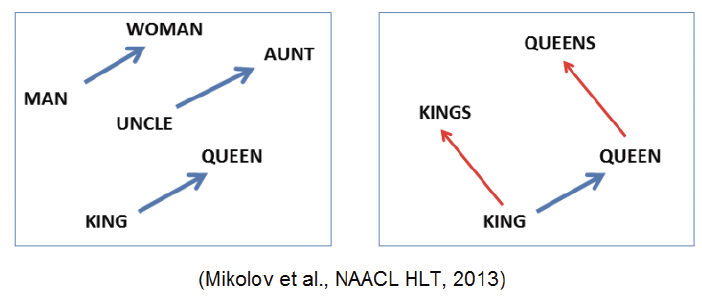
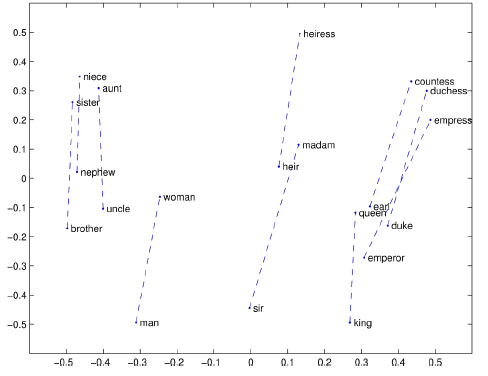
NLP word embedding
1. Word Embedding?
- word를 vector로 표현
- ‘cat’과 ‘kitty’를 유사한 벡터로 표현(short distance)
- ‘hamburger’와 ‘cat’은 먼 위치가 되도록 표현
2. Word2Vec
2.1 기본 원리
- 인접 단어(주변단어)를 활용해 벡터로 표현하는 것을 학습하기 위한 알고리즘
- => 주변단어의 확률 분포를 활용
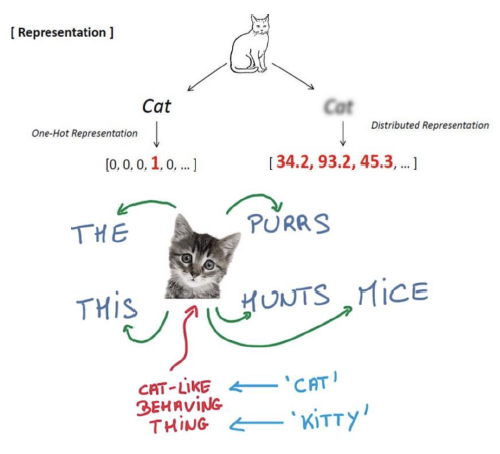
- Vector 학습과정
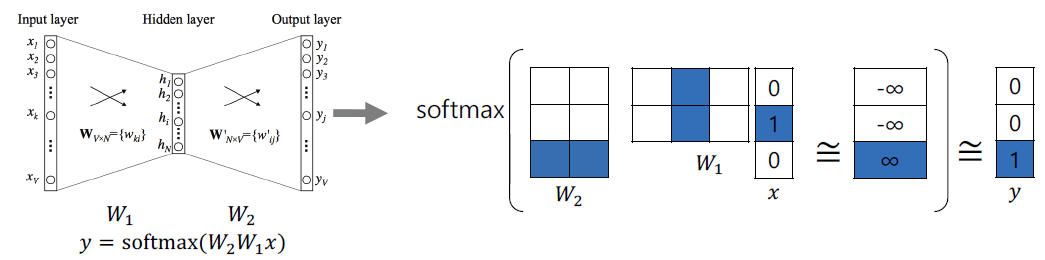
- step 1. W1 @ x => 2x1 차원 행렬
- step 2. W2 @ step 1 => 3x1 차원 행렬
- step 3. softmax(step2)
- step 4. target word가 1이(최대화) 되도록 W1, W2 학습
- step 5. 주변 단어와의 모든 pair에 대해서 step 1~4 진행
- E.g I study math
- 두 페어에 대해 학습 진행
- (x: study y: I)
- (x: study y: math)
- 학습후 활용시에는 W1 벡터를 곱해 embedding vector get
- 시각적으로 볼수 있는 사이트
2.2 Property of Word2Vec
- 단어의 의미를 포함한 벡터
- Application of Word2Vec
- Word similarity
- Machine translation
- Part-of-speech(Pos) tagging
- Named entitiy recognition(NER)
- Sentiment analysis
- Clustering
- Semantic lexicon building
- Image Captioning
3. GloVe
3.1 기본 원리
- Gloval Vectors for Word Representation
- $J(\theta) = {1 \over 2} \sum_{i,j=1}^W f(P_{i,j})(v_i^T v_j - log(P_{i,j}))^2$
- 특정 단어의 pair를 반복적으로 학습하는 것을 피하기 위해, 각 단어페어를 모두 학습하기 보다, 먼저 co-ocurrence matrix(동시에 등장하는 횟수)를 계산
- 동일한 단어가 여러번 나오면 Word2Vec에서는 그 단어는 여러번 학습된다
- Fast training
- 작은 corpus에 대해서도 잘 동작
- 학습하는 방법은 유사
3.2 Property of Glove