
1. Type of RNNs
1.1 One-to-one
- 기본 신경망
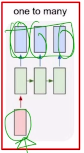
1.2 One-to-many
- E.g Image captioning
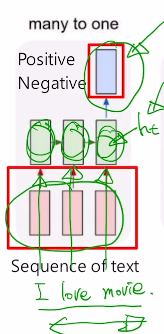
1.3 Many-to-one
- E.g 감정 분석
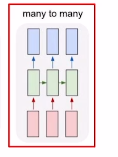
1.4 Many-to-many
-
E.g 번역
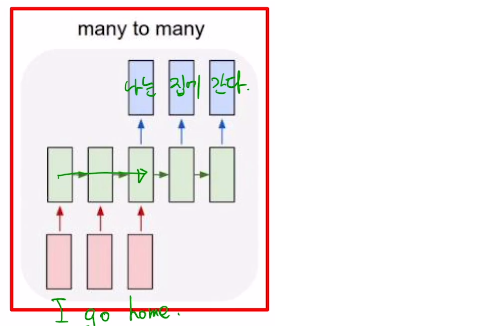
-
실시간성을 위한 구조
2. RNN for NLP
2.1 Character-level Language Model
- Many-to-many 구조
- E.g “hello”
- vocabulary: [h, e, l, o]
- training sequence: “hello”
- $h_t = f_W(h_{t-1}, x_t)$
- 처음부분 h0는 0으로 주거나 할수 있음
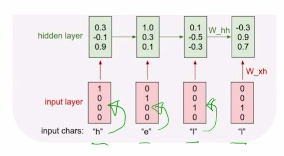
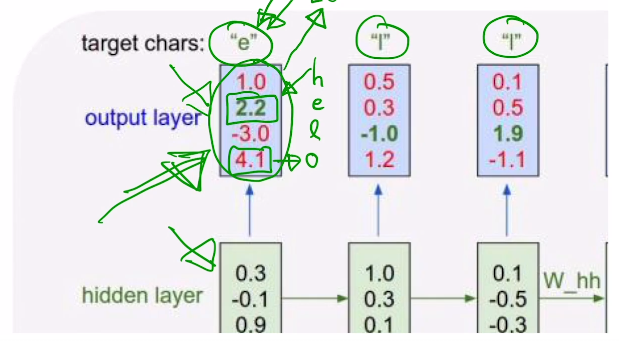
- 처음부분 h0는 0으로 주거나 할수 있음
- 현재 ‘o’가 4.1로 확률이 가장 높은데, target은 ‘e’이다. 따라서 학습 과정 중에 ‘e’의 확률이 가장 높아질 수 있도록 loss를 설정하여 학습하면, ‘h’다음에 ‘e’가 아온다고 예측하도록 훈련시킬 수 있다.
- 이러한 방식으로 이전 층의 출력을 다음 입력으로 넣어준다면, 무한히 생성되는 문장을 만들 수 있다.
- LSTM, GRU로 보완 가능
2.2 Backpropagation through time (BPTT)
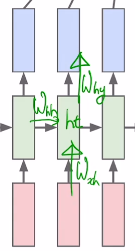
- 입력 벡터가 hidden state로 변환될 때 사용되는 $W_{xh}$ ,
전 time step의 hidden state 벡터가 현재 time step의 hidden state로 변환될 때 사용 되는 $W_{hh}$ ,
계산된 $h_t$ 가 output 벡터로 변환될 때 사용되는 $W_{hy}$
위 3가지가 backpropagation에 의해 학습 된다.
- 너무 길어지면 정보를 다 담기에 메모리에 무리가 가기 때문에 turncate를 한다.
- $W_{hh}$ 가 반복적으로 곱해지기 때문에, vanishing/exploding gradient 문제가 발생 할 수 있다.
2.3 Searching for interpretable Cells
- Hidden state에 정보가 담겨있다.
- Hidden state의 각각에 하나의 차원 값을 고정해두고 forward시 어떻게 변하는 지를 보고 분석을 할 수 있다.

3. LSTM, GRU for NLP
3.1 LSTM
- cell state 정보를 어떠한 변화 없이 바로 다음 cell로 통과시키는 구조가 존재
- $[c_t, h_t] = LSTM(x_t, c_{t-1}, h_{t-1})$
- $c_{t-1}$ : cell state 벡터
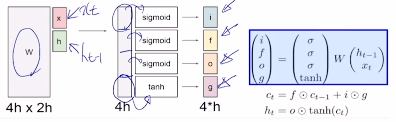
- $c_{t-1}$ : cell state 벡터
3.2 GRU
- LSTM 보다 적은 메모리로 빠르게 계산할 수 있도록 만든 모듈
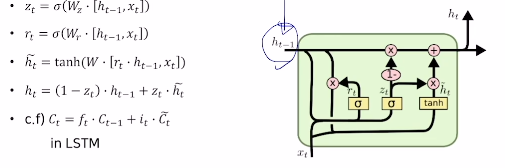
- $h_{t-1}$ 이 LSTM의 $C_t$ 와 유사한 역할을 담당한다. LSTM에서는 $C_t$ 를 구하기 위해 forget gate와 input gate를 이용해 정보를 합처주는 과정을 거쳤지만, GRU에서는 input gate의 정보만을 활용해 $z_t$ , $1-z_t$ 를 만들고, 이를 이용해 $h_{t}$ 를 계산한다.(가중 평균 형태)
즉, 2개의 gate를 이용해 계산하던 것을 1개의 gate로 계산하도록 바꾸어 주어 계산 속도 및 메모리 효율을 높였다.