
1. Encoder-decoder architecture
-
Many to many 형태
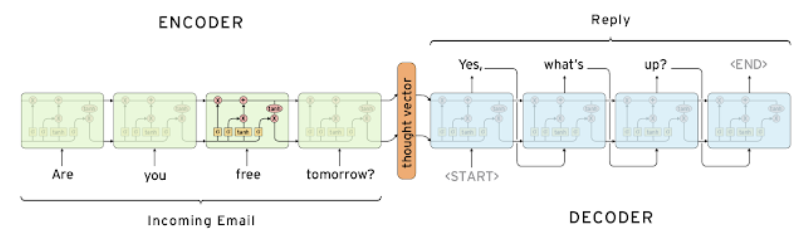
- Encoder
- 입력에 대한 정보를 담은 벡터 생성
- 입력 시퀀스가 길어지면, 처음 입력의 정보가 희미해 질 수 있음
- Attention을 사용하면, 각 셀의 출력 $h_0, \ h_1, \ h_2, \ h_4$ 가 전체적으로 디코더로 보내짐
- Decoder
- Encoder의 마지막 time step을 $h_0$ 로 입력 받음
- < SoS > < Eos > 특수 문자를 활용해 문장의 시작과 끝을 나타냄
- Attention을 사용하면, 인코더로 부터 받은 각 셀의 $h_i$ 를 선별적으로 사용해 출력을 결정함
2. Seq2Seq with Attention
- Forward 과정
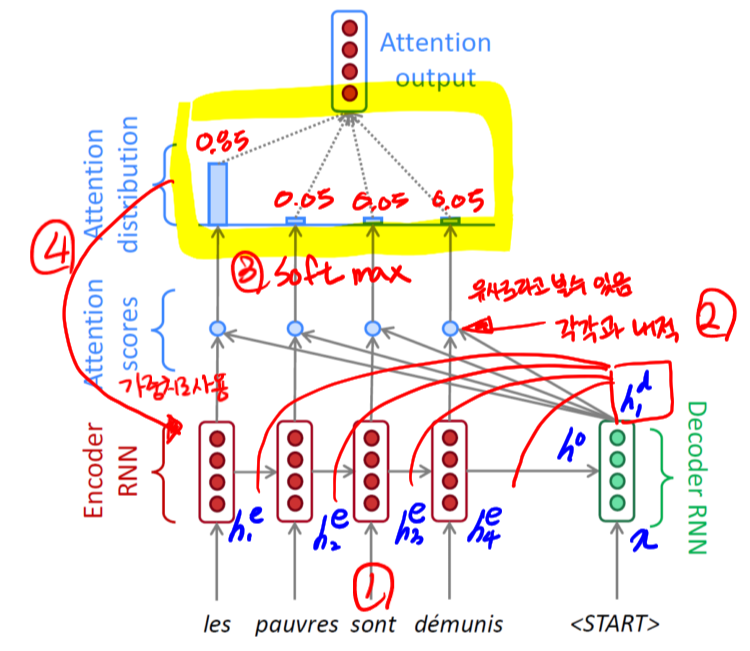
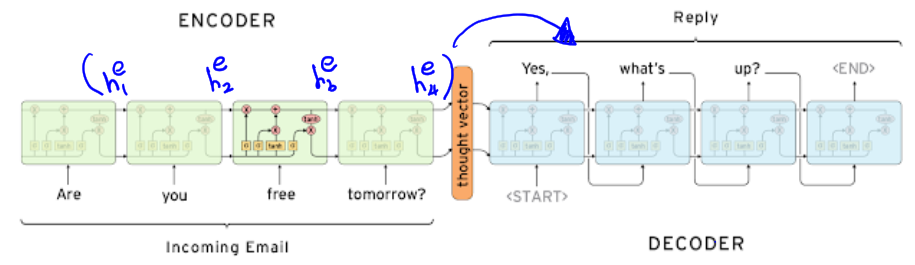
- 인코더에서 $h_i^e$ 들이 계산되고, 마지막 hidden state 벡터는 디코더의 입력으로 들어간다.
- 디코더는 x와 인코더로부터 $h_0$ 를 입력받아 $h_1^d$ 를 계산한다.
- $h_1^d$ 와 $h_i^e$ 들을 각각 내적해 Attention score(유사도라고 볼수 있는)를 계산한다. 그리고 얻은 값들을 softmax를 취해 확률값을 구한다.
- 3번에서 얻은 확률값을 각각의 $h_i^e$ 에 가중치로서 사용한다.
- 4번에서 가중치와 $h_i^e$ 들을 활용해 하나의 Attention output 벡터를 만든다.
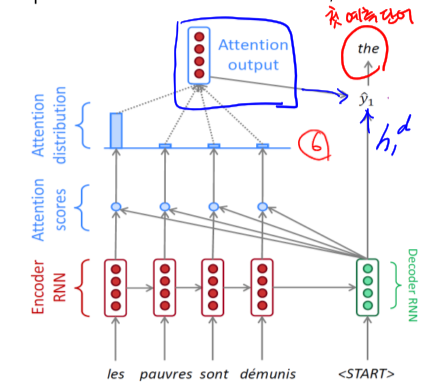
- 5번의 Attention output 벡터와 $h_1^d$ 를 활용해 첫번째 예측 단어를 결정한다.
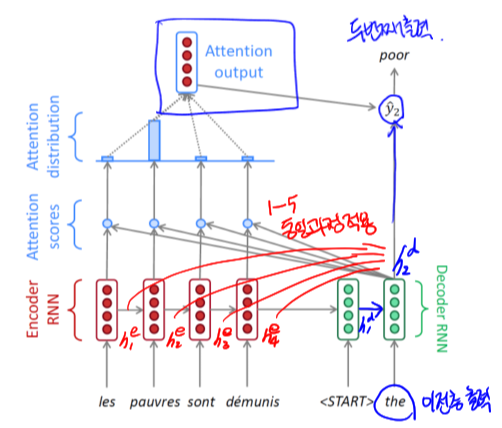
- 디코더의 이전층 출력(the, $h_1^d$ )을 입력으로 받고, 1-5의 동일한 과정을 적용해, Attention output 벡터를 구한후 $h_2^d$ 와 같이 활용해 두번째 출력을 구한다.
- < Eos >가 나올때 까지 반복한다.
- Backward
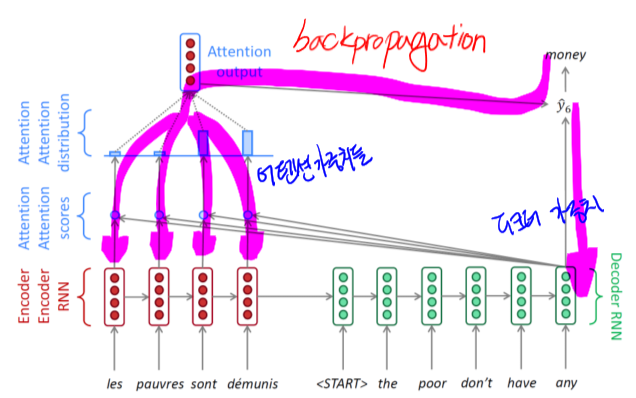
- 디코더의 가중치 뿐만 아니라, Attention 가중치까지 역전파 학습
- Teacher forcing
- 디코더의 입력으로 이전층의 출력이 아니라, 직접 ground truth를 넣어 주는것
- 학습이 빠르고 용이하지만, Test-실제 사용환경과는 다르다는 괴리가 존재
- 두 방식을 적절히 섞어, 후반부에는 실제 사용환경과 유사하게 학습 하는 방법도 존재
- Attention score(유사도)를 구하기 위한 다양한 방법들
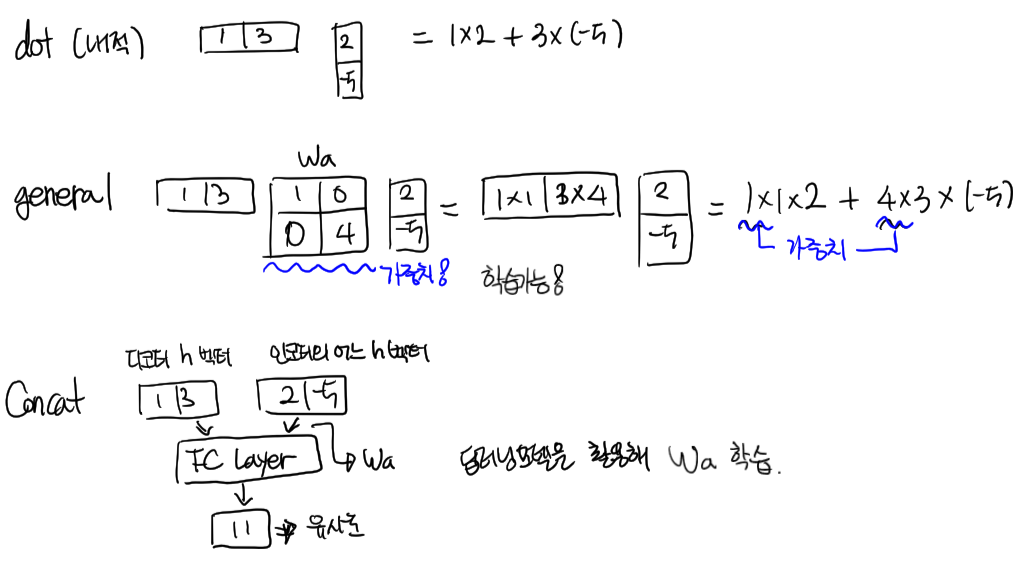
- dot: 단순한 내적연산으로 학습이 불가능
- general: 중간의 $W_a$ 행렬에 가중치를 부여할 수 있어, $W_a$ 가중치 값을 학습 할 수 있음
- Concat: 딥러닝 모델을 활용해 Attention score 연산, 당연하게 학습이 가능
- Attention의 장점
- Information bottleneck 해결
- 인코더의 마지막 hidden state 벡터만에 의존해 번역 결과를 생성해야 했던 문제를 해결
- Long tern dependency를 보완하고, 일종의 지름길을 만듦
- Interoretability 어떤 단어에 집중했는지 분석/시각화 가능
- Information bottleneck 해결