NLP: GPT-1, BERT
Self-Supervised Pre-Training Models
1. GPT-1
1.1 Intro
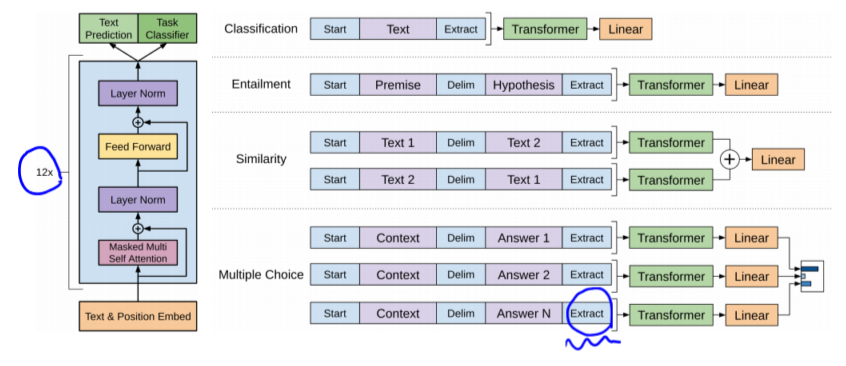
- Open-AI에서 만든 모델
- 다양한 special token들을 제안해, NLP 분야에 다양한 Task를 통합
- Self-attention 과정에서, Extract 토큰은 앞선 입력들의 관계 등 Task에 필요로 하는 정보를 적절하게 추출할 수 있는 Query를 생성해야함
1.2 Fine tunning
- Pretrain된 모델을 활용
- Transfer learning을 위해서 (새로운 Task를 학습하기 위해서)는 마지막 Linear layer만 수정해 학습
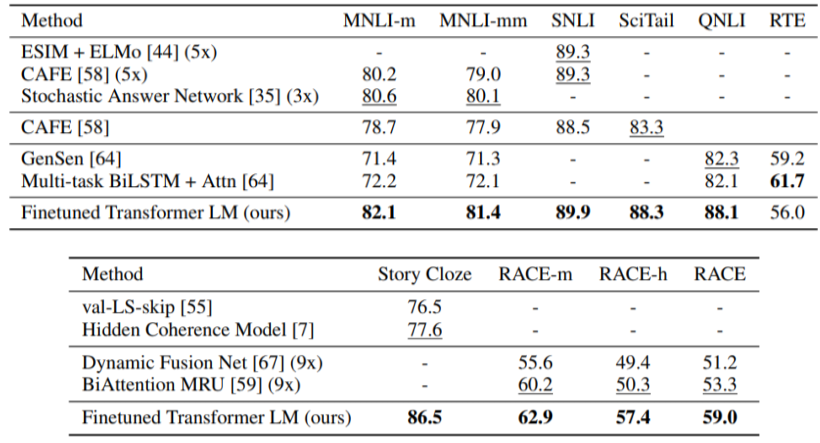
- Pretrain된 GPT-1 모델을 여러가지 Task로 Fine-tunning을 통해 학습한 결과가 그 Task만을 위한 데이터로 학습한 모델보다 성능이 좋음
2. BERT
2.1 Intro
- Motivation: GPT-1은 단어를 보고 다음 단어를 예측
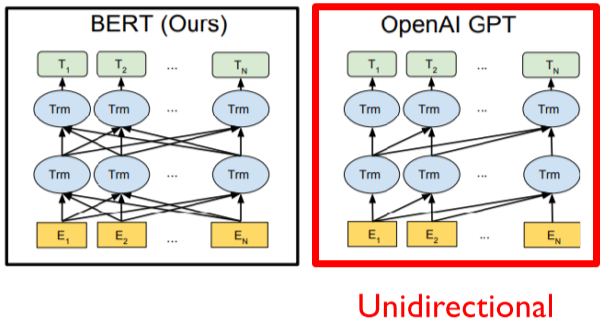
- E.g $ SOS \rightarrow I \rightarrow study \rightarrow math $
- But, 언어는 양바향으로 관계가 있음
2.2 Pre-training Tasks in BERT
- Masked Language Model (MLM)
- 일정 확률로 단어를 MASK로 치환한 후 맞추도록 하는 것
- 약 입력 문장의 15%에 MASK로 치환
- 너무 작은 비율로 마스킹을 하면, 훈련 효율이 떨어짐 (too expensive to train)
- 너무 많은 비율로 마스킹을 하면, 문맥을 이해하기에 충분하지 않음
- Problem
- MASK란 토큰은 실제 존재 하지 않는것, 노이즈가 될 수 있음
- Solution
- 15%의 단어들 중,
- 80%는 MASK 토큰으로 치환
- 10%는 random word로 치환
- 10%는 원래 단어로 가만히 둠
- Next Sentence Prediction

- 문장의 관계가 다음에 나올 수 있는 것인지 아닌지 학습
- BERT Summary
- Model Architecture
- L: Self-attention block 수, H: 임베딩 벡터 크기, A: Attention head 수
- BASE: L=12, H=768, A=12
- LARGE: L=24, H=1024, A=16
- Input Representaion
- WordPiece embeddings (30,000개)
- Learned positional embedding
- positional 벡터를 학습을 통해 최적화
- Segment Embedding
- 문장 레벨의 임베딩 벡터
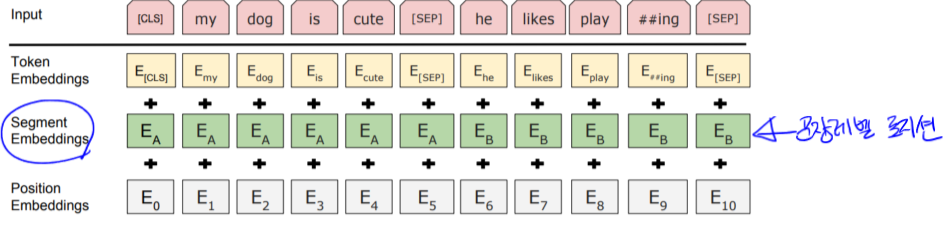
- [CLS] - Classification embedding
- Packed sentence embedding
- Pre-training Tasks
- Masked LM
- Next Sentence Prediction
2.3 Fine-tuning process
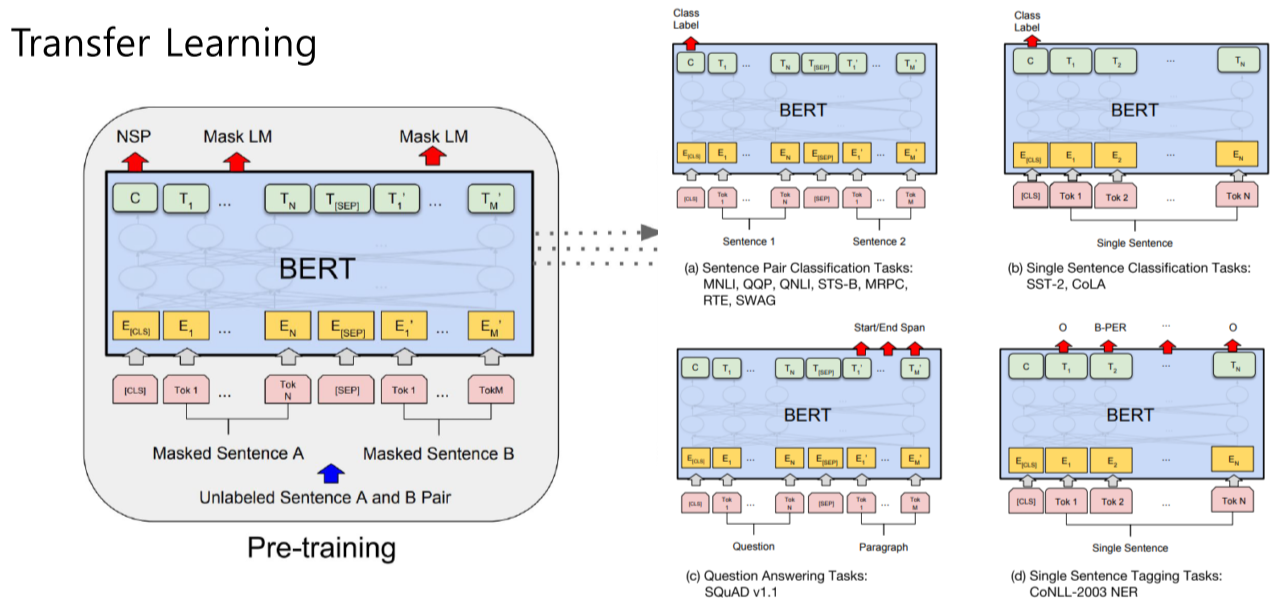
- (a) 두개의 문장을 [SEP]로 구분해 입력으로 주고, [CLS] token을 output layer의 입력으로 제공해, 분류 task 수행
- (b) 하나의 문장을 입력으로 주고, [CLS] token을 output layer의 입력으로 제공해, 분류 task 수행
- (c) QA task, Question에서 정답이 되는 Paragraph의 substring을 찾는것, [SEP] token 이후에서 start, end 찾는 task
- (d) NER이나 형태소 분석 같이 single sentence에서 각 토큰이 어떤 클래스를 갖는지 분류하는 task
3. Machine Reading Comprehension (MRC), QA
3.1 Intro

3.2 SQuAD
- 1.1
- QA 데이터 셋
- 링크
- BERT를 변형한 모델들이 순위권 차지 중
- 질문과 내용을 연결해 인코딩해, 어떤 위치에 정답이 있는지로 학습 (?)
- 2.0
- 질문에 대한 답이 없는 문제까지 추가
- 없는 경우[CLS] token을 활용해, no answer의 경우 binary classification 문제로 변경
3.3 On SWAG
- 주어진 문장이 있을 때, 다음에 나타날 적절한 문장을 고르는 Task
- 주어진 문장과 후보 문장을 concat해 BERT를 통해 임베딩 벡터를 얻는다. 그리고, FC 넣어 예측 한 스칼라 값을 출력. 그 값들을 soft-max를 통과시켜 원하는 답의 확률을 가장 높게 가져가도록 학습시킴
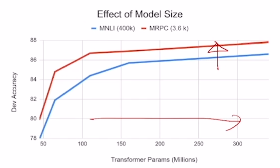
3.4 Ablation Study
- Big models help a lot
- 모델의 크기를 키울수록 성능이 좋아짐
4. 참고하면 좋은 사이트
