NLP: GPT-2/3, ALBERT, ELECTRA
1. GPT-2
1.1 GPT-2: Language Models are Unsupervised Multi-task Learners
- 정말 큰 transformer LM
- 40GB 분량의 text 훈련
- 데이터셋의 퀄리티를 높이기 위해 노력을 많이 들임
- reddit link들로 부터 webpage들 취합
- Language model은 zero-shot setting에서 down-stream task(생성 관련)들을 수행할 수 있음
- 파라미터 수정이나, 구조의 변경 없이
- 기본적으로 첫 문장을 이어받아 다음 단어들을 출력하도록 학습된 모델
1.2 GPT-2: Motivation (decaNLP)
- NLP Decathlon: Multitask Learning as Question Answering
- 모든 NLP 테스크들이 QA 형식으로 바뀔 수 있다
- E.g. “I love this movie” 라는 문장이 주어지면, 긍정인지 부정인지 분류하고자 할때, 중간에 “What do you think about this document in terms of positive or negative sentiment?” 문장을 만들어 넣어 주면, 질문에 대한 답을 생성하는 형태로 변형할 수 있다.
1.3 GPT-2: Dataset
- promising source, diverse and nearly unlimited text
- Reddit에서 외부 링크로 포함된 것중 호평을 많이 받은 것을 scrapped 해, 외부링크 까지 데이터로 가져옴
- 8M removed Wikipedia documents
- Use dragnet and newspaper to extract content from links
- Preprocess
- Modification
- Layer normalization이 각 sub-block의 입력으로 이동
- pre-activation residual network
- 마지막 self-attention block 이후 추가적인 layer normalization 사용
- Scaled the weights of residual layer at initialization by a factor of ${1 \over \sqrt n}$ , n: # of residual layer

- layer가 위쪽으로 가면 갈수록, 해당하는 선형변환들이 0에 가까워 지도록. 즉, 위쪽으로 갈수록 layer의 영향력이 줄어들도록 구성 (?)
- GPT-2 활용 실험
- QA test
- Conversation question answering dataset(CoQA)
- zero-shot learning setting (학습데이터 사용 X)
- 바로 예측 시켰을 때, f1-score: 55
- Fine-tuned BERT: 89
- Summarization
- 마지막에 TL;DR 을 붙이는 것으로 요약한 문장이 나오도록 문장 생성
- TL;DR: Too long, didn’t read
- 학습에 사용하지 않고도 요약 수행이 가능했음

- Translation
- 마지막에 they say in French: 이런식으로 붙여주면 어느정도 번역된 문장을 생성

2. GPT-3
2.1 GPT-3: Language Models are Few-Shot Learners
- 모델의 확장
- Scaling up이 task-agnostic, few-shot performance를 많이 향상시킬 수 있음
- few-shot stteing으로 175M parameter 크기의 Autoregressive LM 사용
- 96 Attention layers, Batch size: 3.2M0
- Few-Shot Learners

- Prompt: 모델에게 prefix 제공
- Zero-shot: task의 자연어 설명만으로 정답 예측
- One-shot: 한쌍의 데이터만 제공, 모델의 변경은 없음
- Few-shot: 여러개의 데이터 제공
- Few > One > Zero
3. ALBERT
3.1 ALBERT: A Lite BERT for self-supervised Learning of Language Representations
3.2 Solutions
- Factorized Embedding Parameterization
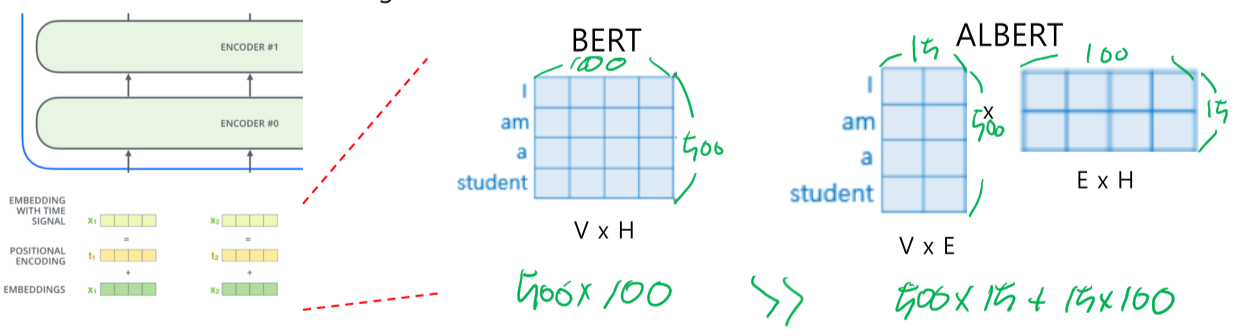
- V: Vocabulary size, H: Hidden-state dimension, E: Word embedding dimension
- 기존의 BERT에서는 입력되는 word embedding 벡터와 Attention의 output인 hidden state embedding 벡터의 길이(차원)이 동일 했어야 한다. 그렇기 때문에 그림에서와 같이 $V \times H$ 라는 큰 벡터를 가지게 된다. 하지만 word embedding 벡터는 hiddend state의 벡터에 비해 담고 있는 정보가 적다! 즉, 동일한 차원일 필요가 없다.
- ALBERT 에서는 word embedding 벡터의 차원을 줄이고, 새로운 Layer를 하나 추가해 원하는 차원의 크기로 변환해주는 $E \times H$ 를 넣어 경량화와 동시에 성능을 유지하려는 시도를 했다.
- Cross-layer Parameter Sharing
- Shared-FFN: feed-forward network 파라미터만 공유
- Shared-attention: attention에 관련된 파라미터만 공유 (Q, V, K)
- 모두 공유
- 경량화 대비 성능 차이가 그렇게 크지 않음
- Sentence Order Prediction
- 기존의 Pretrain 방법: 두개의 문장을 Concat해 사용 (Next Sentence Prediction 방법)
- 실효성이 별로 없음
- Mask 방법만 사용했을 때 성능이 떨어지지 않음
- 기존 방법의 Random 추출된 두 문장은 연관관계가 많이 적음
- 고차원적인 정보를 추출해 맞춰야 하는 어려운 문제
- 두개의 문장을 놓고, 순서가 바른지, 역순인지를 표현해 학습
- 두 연속된 segments에 대해 Negative samples
- 즉, 단순하게 순서가 맞는지 아닌지를 판단하는 문제가 된다.
- 유사한 내용이 얼마나 되는지, 아닌지로 간단하게 판별 가능
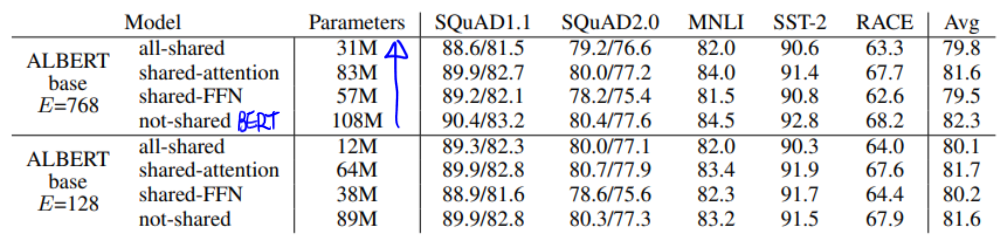
- 효과검증
- Next Sentence Prediction vs Sentence Order Prediction

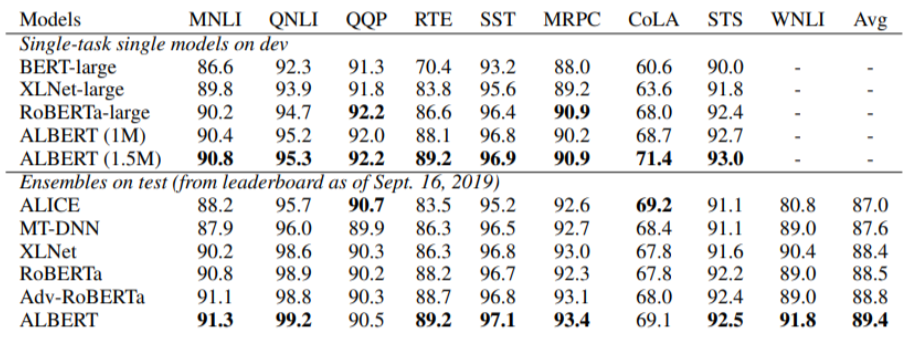
- GLUE Results
4. ELECTRA
4.1 ELECTRA: Efficiently learning an Encoder that Classifies Token Replacements Accurately
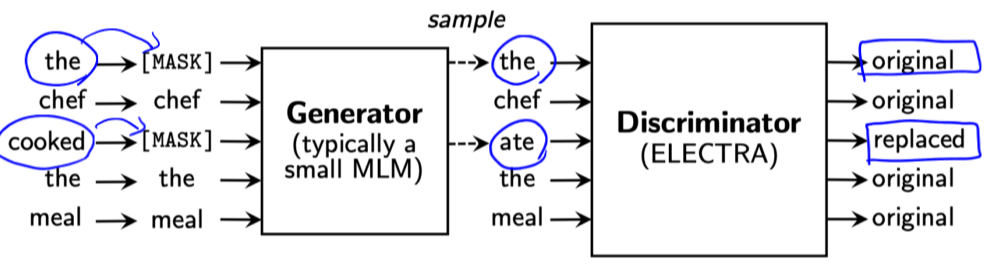
- 모델 구조
- Generator: BERT
- Discriminator: Transformer 구조
- Adversarial 하게 학습
- Generator로 mask된 부분의 단어를 예측하게 하고, Discriminator가 판단해 피드백을 부여하는 방식으로 Pretraining하는 방식
- 즉, Discriminater가 pre-training을 위한 main network
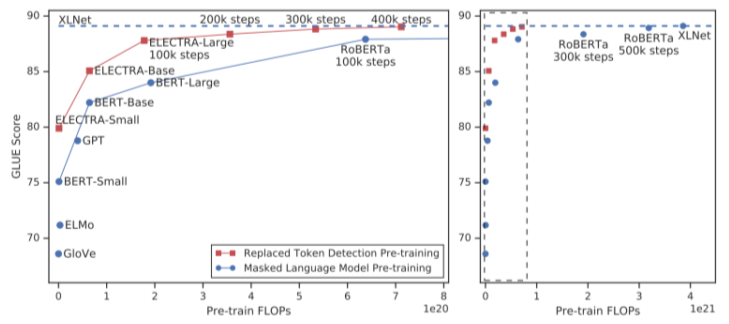
- 계산량 측면(왼쪽 그래프)에서 동일 계산량에 비해 더 좋은 성능
5. Others
5.1 Light-weight Models
- DistillBERT
- Hugging face에서 발표한 모델
- Teacher - student 구조를 활용, 작은 사이즈의 student 모델이 큰 사이즈의 Teacher 모델의 결과 확률 분포를 모방하도록 학습
- TinyBERT
- DIstillBERT와 유사
- 다만 결과 값 뿐만이 아니라, attention의 파라미터와 hidden state 벡터까지도 유사해 지도록 학습
- 하지만, student 모델은 teacher모델 보다 hidden state 벡터의 차원이 작기 때문에, 차원을 줄여주는 Layer를 하나더 두어 Loss를 계산
5.2 Fusing Knowledge Graph into Language Model
- Knowledge Graph: 외부 지식
- ERNIE: Enhanced Language Representation with Informative Entities
- KagNET: Knowledge-Aware Graph Networks for Conmmonsense Reasoning
6. Refference
