
1. 관계 추출
1.1 Task introduction
- text 속 entity pair들 사이의 sematic realation 판단
- 총 30개 class
1.2 Pretrained-model setting
- klue/roberta-base
- task: re
2. KLUE-RE with Huggingface
2.1 Code
-
라이브러리 불러오기
import numpy as np import pandas as pd from datasets import load_dataset, load_metric from transformers import AutoTokenizer, AutoModelForSequenceClassification, TrainingArguments, Trainer # 사용할 Pretrained 모델 model_checkpoint = "klue/roberta-base" batch_size = 32 # batch size task = "re" # 수행할 task -
데이터셋 준비
# KLUE에 RE task에 해당하는 데이터 불러오기 datasets = load_dataset("klue", task) # classification head 구조 설정을 위해 class의 수 계산 num_of_target = len(set(datasets['train']['label'])) -
Tokenizer, Model
# Hugging face 예제에서 사용하는 구조 차용 def preprocess_function(examples): # sentence에 tokenizer 적용해서 반환 return tokenizer( examples['sentence'], truncation=True, return_token_type_ids=False, ) # Pre-trained tokenizer 불러오기 tokenizer = AutoTokenizer.from_pretrained(model_checkpoint, use_fast=True) # tokenizer 적용해 dataset class 생성 encoded_datasets = datasets.map(preprocess_function, batched=True) # Pre-trained model 불러오기 model = AutoModelForSequenceClassification.from_pretrained(model_checkpoint, num_labels=num_of_target) -
metric 정의
# metric 정의 # glue의 qnli에 정의되어있는 accuracy 사용 metric = load_metric('glue', 'qnli') metric_name = "accuracy" -
Training
def compute_metrics(eval_pred): predictions, labels = eval_pred predictions = np.argmax(predictions, axis=1) return metric.compute(predictions=predictions, references=labels) # 훈련을 위한 args 정의 args = TrainingArguments( "test-re", # 폴더 이름 #save_strategy = "epoch", # 버전에 따라 필요한 경우가 있고 없는 경우가 있음 evaluation_strategy="epoch", # 에포크에 따라 평가 learning_rate=2e-5, # 학습률 per_device_train_batch_size=batch_size, # batch size per_device_eval_batch_size=batch_size, num_train_epochs=10, # 훈련 epoch weight_decay=0.01, # scheduler 적용 load_best_model_at_end=True, # 최적 모델 선택 metric_for_best_model=metric_name, # 설정한 metric 기준 ) # 훈련을 위한 class 생성 trainer = Trainer( model, # 훈련할 모델 args, # 훈련 args # dataset 적용 train_dataset=encoded_datasets["train"], eval_dataset=encoded_datasets["validation"], # tokenizer tokenizer=tokenizer, # 정의한 metric compute_metrics=compute_metrics, ) # 훈련 시작 # 10 epoch에 약 45분 걸리는 듯 (v-100) trainer.train()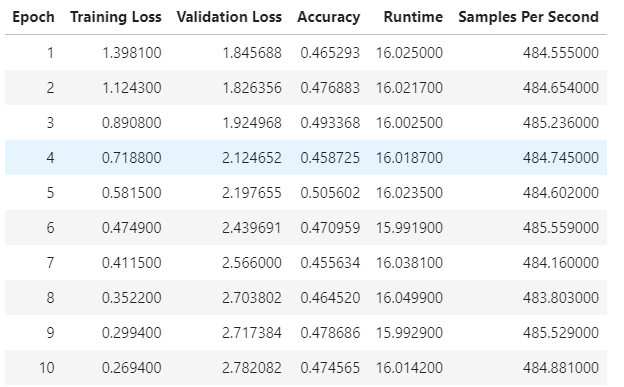
-
평가
trainer.evaluate()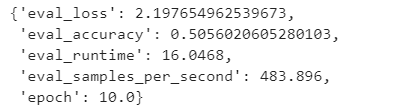
2.2 결과 정리
- ACC, 50%
- 제공되는 Pretrained 모델의 수정이 필요해 보임
- 학습 전략 변화 필요
- low level 코드 활용이 필요해 보임
-
top leader board model config file
// config.json { "architectures": ["RobertaForMaskedLM"], "attention_probs_dropout_prob": 0.1, "bos_token_id": 0, "eos_token_id": 2, "gradient_checkpointing": false, "hidden_act": "gelu", "hidden_dropout_prob": 0.1, "hidden_size": 1024, "initializer_range": 0.02, "intermediate_size": 4096, "layer_norm_eps": 1e-05, "max_position_embeddings": 514, "model_type": "roberta", "num_attention_heads": 16, "num_hidden_layers": 24, "pad_token_id": 1, "type_vocab_size": 1, "vocab_size": 32000, "tokenizer_class": "BertTokenizer" } // Tokenizer_config.json { "do_lower_case": false, "do_basic_tokenize": true, "never_split": null, "unk_token": "[UNK]", "sep_token": "[SEP]", "pad_token": "[PAD]", "cls_token": "[CLS]", "mask_token": "[MASK]", "bos_token": "[CLS]", "eos_token": "[SEP]", "tokenize_chinese_chars": true, "strip_accents": null, "model_max_length": 512 }