인공지능과 자연어처리
1. 인공지능의 탄생과 자연어 처리
1.1 자연어처리 소개
- 피그말리온과 갈리테이아 (B.C. 43 - A.D. 17)
- 피그말리온이 여성의 결점을 제거해서 만든 조각상
- 인간을 대체하는 인공물에 대한 최조의 기록
- 그리스 신화: 피그말리온은 여성들이 결점이 많다고 생각해 연애를 안했음, 그렇게 결점이 없는 여성을 만들고자 조각상을 만들었는데, 이와 사랑에 빠지게 됨. 아프로디테가 이에 능력을 발휘해 조각상을 실제 사람으로 만들어주고 피그말리온과 결혼함. 이것이 인간이 만든 최초의 인공물로서 기록됨.
- 콜로서스 컴퓨터 (1943)
- 이미테이션 게임 - 튜링 테스트 (1950)
- 기계에 지능이 있는지를 판별하고자 하는 실험
- 인간의 정의나 인간의 지능을 정의하긴 어려웠음
- 인간처럼 대화를 할 수 있다면 그 컴퓨터는 인간처럼 사고할 수 있다!
- AI의 황금기 (1956 - 1974)
- ELIZA (1966) 챗봇
- 최초의 대화형(chitchat) 챗봇
- 튜링 테스트를 적용할 수 있는 최초의 Human-Like AI
- ELIZA
- 정확한 답변을 주는 것은 아니지만, 대화를 유도할 수 있도록 설계되어있음
1.2 자연어처리의 응용분야
- 종류

- 자연어처리
- (인간) 대화의 단계
- 화자는 자연어 형태로 객체를 인코딩
- 메세지의 전송
- 청자는 자연어를 객체로 디코딩
- 즉, 화자는 청자가 이해할 수 있게 이쁘게 인코딩, 청자는 본인의 지식을 바탕으로 디코딩
- (컴퓨터) 대화의 단계
- Encoder는 벡터 형태로 자연어를 인코딩
- 메세지의 전송
- Decoder는 벡터를 자연어로 인코딩
- 즉, Encoder는 Decoder가 이해할 수 있게 이쁘게 인코딩, Decoder는 본인의 지식을 바탕으로 디코딩
1.3 자연어 단어 임베딩
- 대부분의 자연어처리는 ‘분류’의 문제 $\rigtharrow$ 분류를 위해 자연어를 벡터화
- 과거에는 사람이 직접 특징(Feature)를 파악해서 분류를 했음, 하지만 실제 복잡한 문제들에서는 사람이 분류를 위한 특징을 파악하기 어려움. 따라서 기계학습의 핵심은 컴퓨터가 스스로 Feature를 찾고, 스스로 기준에 맞추어 분류를 하는 것이다.
- 자연어를 좌표 위에 표현하는 방법?
- One-hot-encoding: 굉장히 sparse 해짐
- Word2Vec: 한 단어의 주변 단어들을 통해, 그 단어의 의미를 파악
- 학습 과정
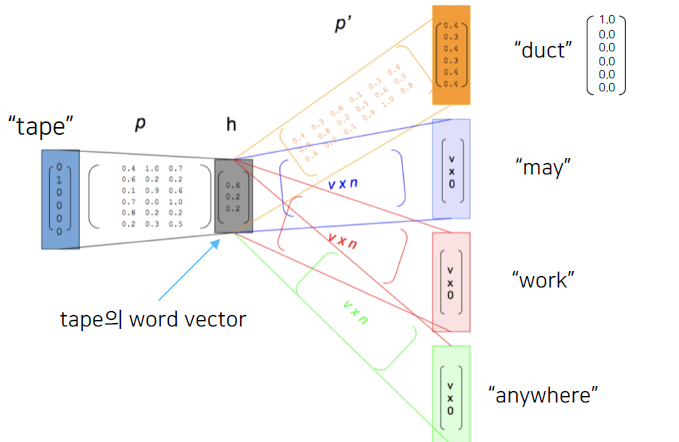
- Word2Vec 검증

- 단점
- Subword information을 무시 (E.g. 서울vs서울시vs고양시)
- Out of vocabulary (OOV)에서 적용 불가능
- FastText
- 학습방법은 Word2Vec과 유사하나, 단어를 n-gram으로 나누어 학습
- n-gram 단어는 사전에 들어가지는 않고, 별도의 n-gram vector를 형성
- n-gram vector를 합산한 후 평균을 통해 단어 벡터 획득
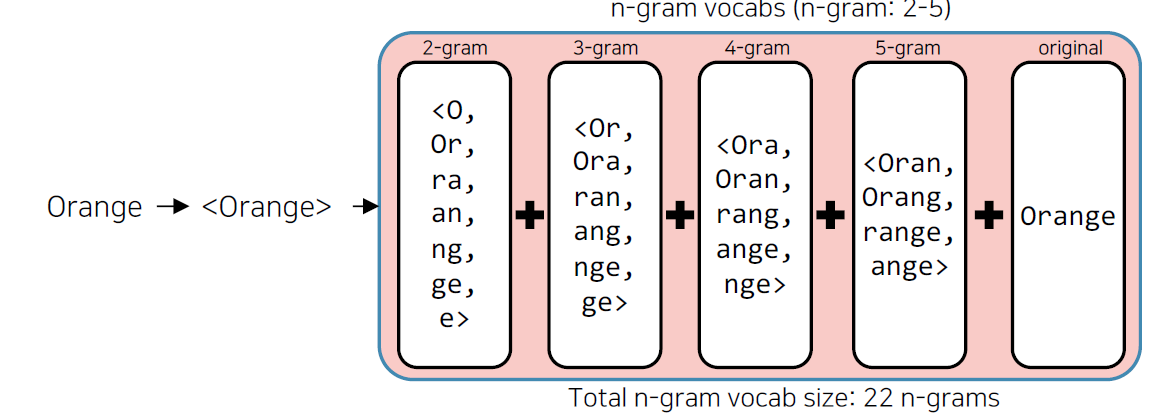
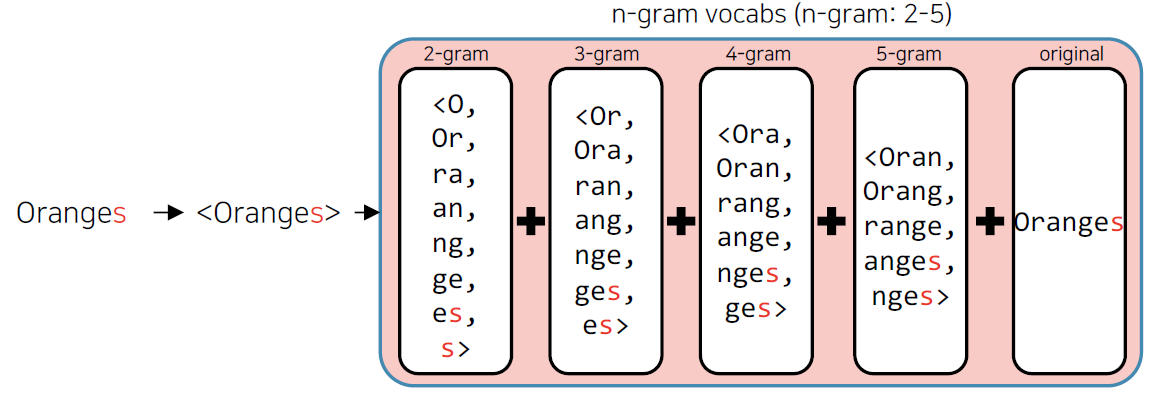
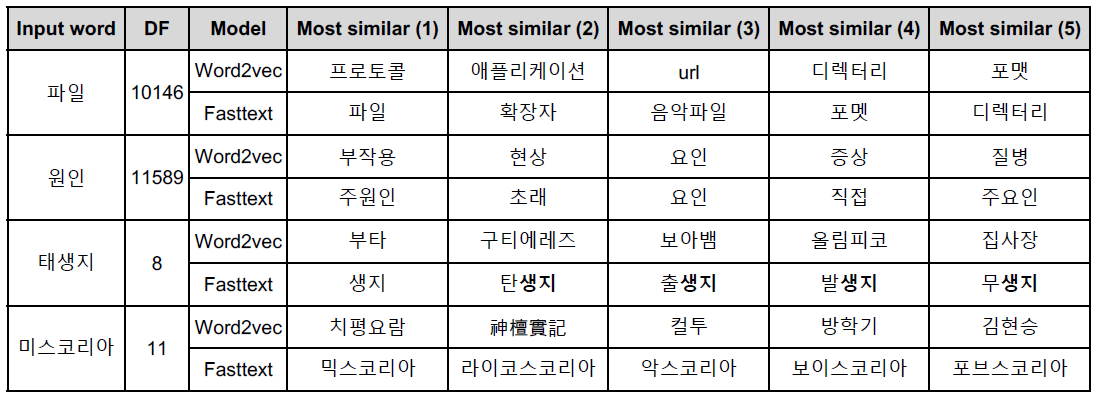
- Word embbeding 방식의 한계점
- 동형어, 다의어 등에 대해서 embedding 성능이 좋지 못함
- 주변단어만들 고려하기 때문에, 문맥을 고려할 수 없음
2. 딥러닝 기반의 자연어처리와 언어모델
2.1 언어모델
- 모델
- 정의
- 어떤 상황이나 물체 등 연구 대상 주제를 도면이나 사진 등 화상을 사용하거나 수식이나 악보와 같은 기호를 사용하여 표현한 것.
- 모델의 특징
- 자연 법칙을 컴퓨터로 모사
- 이전 state를 기반으로 미래 state 예측 가능
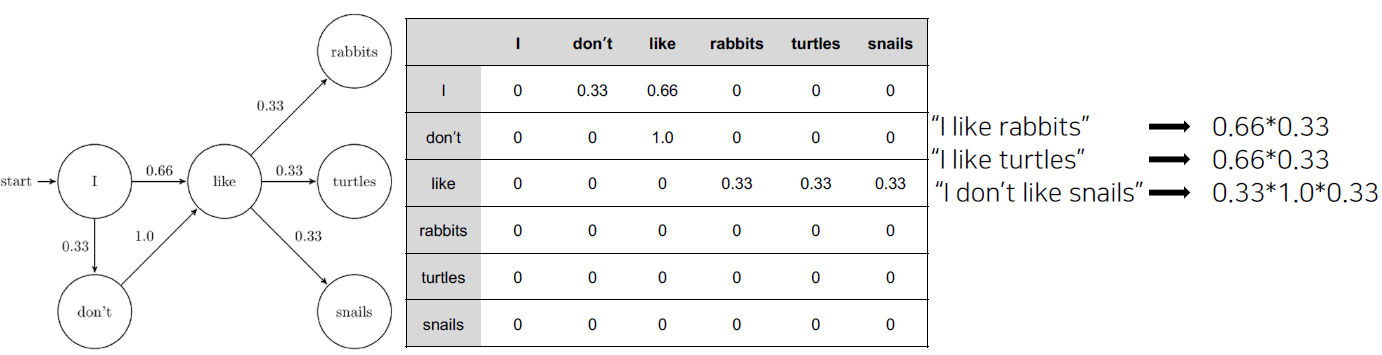
- Markov 기반의 언어모델
- Markov Chain Model
- 초기의 언어 모델은 다음의 단어나 문장이 나올 확률을 통계와 단어의 n-gram 기반으로 계산
- 딥러닝 기반의 언어모델은 해당 확률을 최대화 하도록 학습
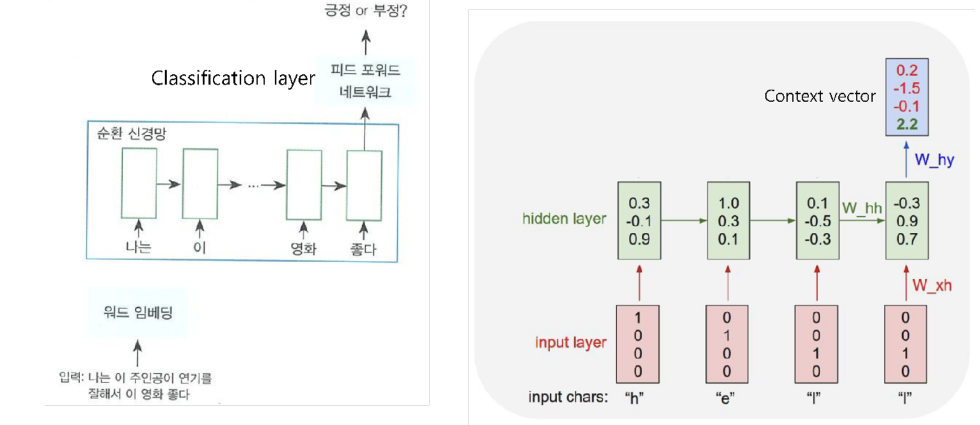
- Recurrent Neural Network 기반의 언어 모델
- 이전 state를 다음 state를 예측하는 데 사용, 시계열 데이터 처리에 특화
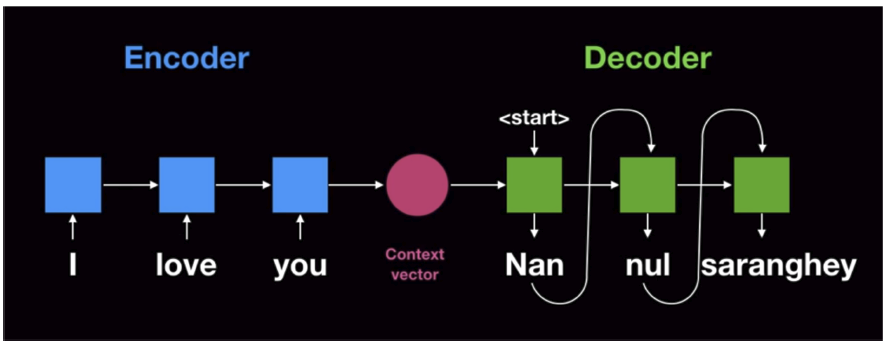
2.2 Recurrent Neural Network 기반의 Seq2Seq
- Encoder layer: RNN구조를 활용해 Context vector 획득
- Decoder layer: 획득한 Context vector를 입력으로 출력을 예측
2.3 Attention
- 문맥에 따라 동적으로 할당되는 Encode의 Attention weight로 인해 Dynamic context vector 획득
- 기존의 Seq2Seq의 성능을 비약적으로 향상시킴
- 하지만, 여전히 RNN이 순차적으로 연산이 이루어져야 하기 때문에 연산 속도가 느리다는 문제가 존재
- Self-attention 모델이 탄생 -> Transformer
3. Futher Questions
- Embedding이 잘 되었는지, 안되었는지를 평가할 수 있는 방법은 무엇이 있을까요?
- WordSim353
- Spearman’s correlation
- Analogy test
- Vanilar Transformer는 어떤 문제가 있고, 이걸 어떻게 극복할 수 있을까요?
- Longformer
- Linformer
- Reformer
