
1. 두 문장의 관계 분류 개요
1.1 Intro
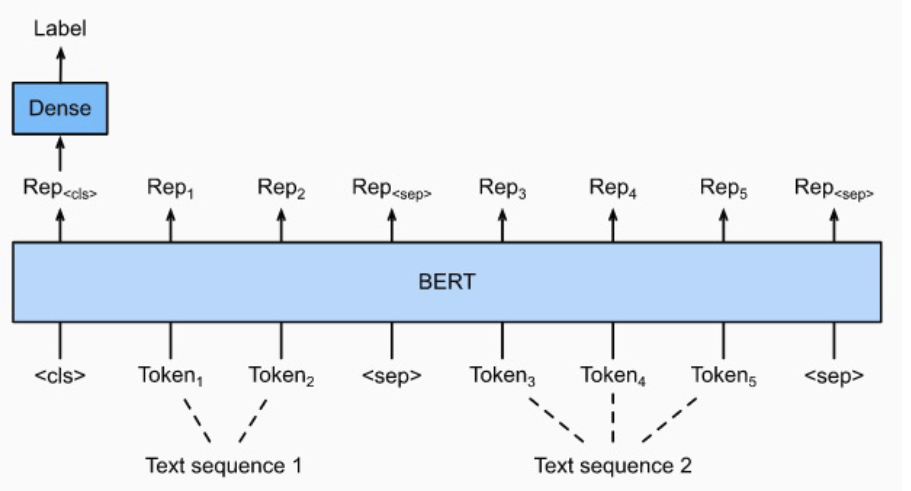
- Sequence1, Sequnce2가 [SEP] 토큰으로 연결되어 입력으로 들어간다.
- 두 문장의 의미나, 관계, 유사도 등의 정보를 추론
1.2 Task 종류
- Natural-Language-Inference-(NLI)
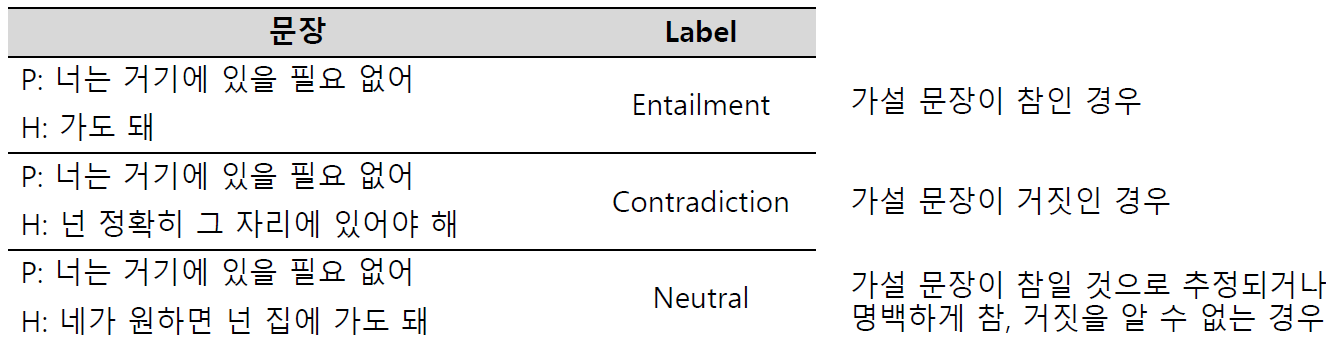
- 언어모델이 자연어의 맥락을 이해 할 수 있는지 검증
- 전체문장과 가설문장을 Entailment(함의), Contradiction(모순), Neutral(중립)으로 분류
- Semantic-text-pair

- 두 문장의 의미가 서로 같은지 검증
1.3 Information#Retrieval#Question#and#Answering#(IRQA)
- 시스템 구조도
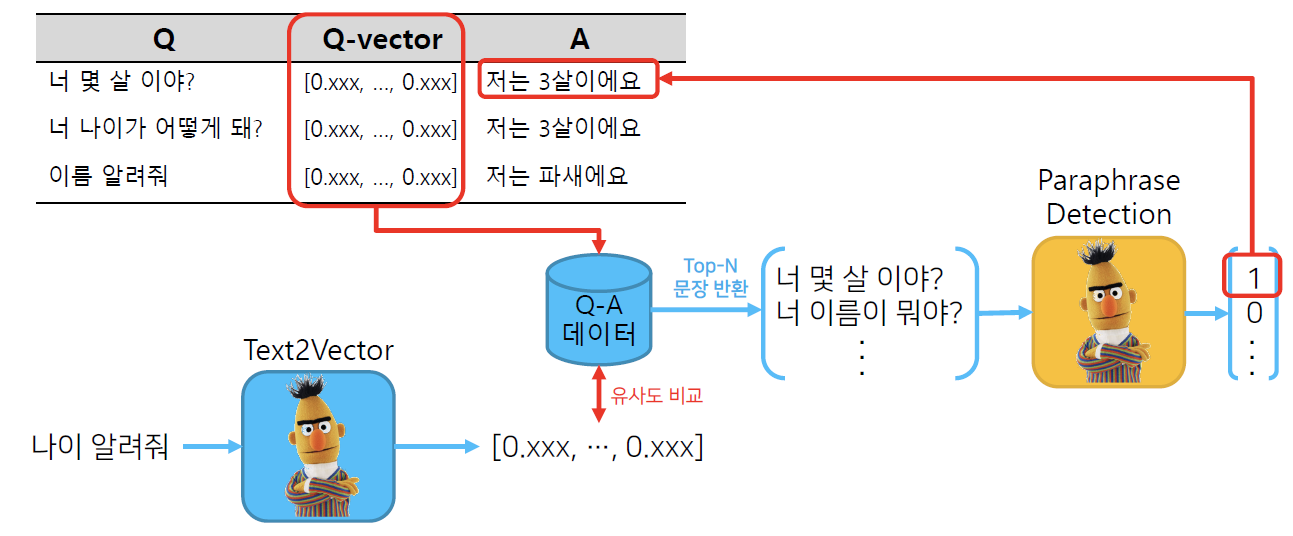
- 사전에 정의된 QA pair에서 적절한 답을 찾는 것
- 사전 QA pair embedding
- BERT를 이용해 사용자의 질문 embedding
- 두 embedding의 유사도를 비교해 적절한 답 선택
- Paraphrase Detection: 검증
- 유사하다고 판단된 질문이 실제로 유사한지 검증해 검증에 통과하면 답이 출력
- 사전에 정의된 QA pair에서 적절한 답을 찾는 것
2. 코드
- Task
- paraphrasing 된 문장이 서로 같은 의미를 가지고 있는지?
- 학습 데이터 구축
-
데이터 가져오기
#git clone https://github.com/warnikchow/paraKQC.git data = open('/content/paraKQC/data/paraKQC_v1.txt') lines = data.readlines() -
유사한 문장 집합 만들기
similar_sents = {} # 유사한 문장을 위한 dict similar_sent = [] # 유사한 문장저장 list total_sent = [] # 전체 문장 for line in lines: # 모든 문장들에 대해서 line = line.strip() # 공백제거 sent = line.split('\t')[2] # \t를 기준으로 split total_sent.append(sent) # 문장들 리스트에 저장 similar_sent.append(sent) # 유사 문장들 저장 if len(similar_sent) == 10: # 10개 씩 저장 similar_sents[similar_sent[0]] = similar_sent[1:] similar_sent = [] -
모든 문장 임베딩 후 저장
- 공개 불가…
- transformers 라이브러리를 활용해서 문장의 임베딩 벡터 생성 및 저장
- 유사도 평가
- 이를 dict로 저장
-
- Fine tunning
- 8:2로 train-test set 분류
- null 데이터 제거
- Pretrained 모델 불러오기 및 토크나이징
from transformers import AutoModel, AutoTokenizer, BertTokenizer MODEL_NAME = "bert-base-multilingual-cased" tokenizer = AutoTokenizer.from_pretrained(MODEL_NAME) tokenized_train_sentences = tokenizer( list(train_data['sent_a'][0:]), list(train_data['sent_b'][0:]), return_tensors="pt", padding=True, truncation=True, add_special_tokens=True, max_length=64 )- 학습 - Trainer, TrainingArguments 활용
from transformers import Trainer, TrainingArguments training_args = TrainingArguments( output_dir='./results', # output directory num_train_epochs=3, # total number of training epochs per_device_train_batch_size=64, # batch size per device during training per_device_eval_batch_size=64, # batch size for evaluation logging_dir='./logs', # directory for storing logs logging_steps=500, save_total_limit=2, )- 추론
ouput = model(inputs, attention_mask, token_type_ids) logits = output result = np.argmax(logits) # 결과 0: 유사하지 않음, 1: 유사
3. 추가참고 자료
- 개체명 인식
- Named Entity Recognition (NER) for Turkish with BERT
- QA
- lonformer_qa_training.ipynb
- [논문리뷰] Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks
- BERT seq2seq
- BERT2BERT_for_CNN_Dailymail.ipynb
- Bert2Bert Summarization