BERT vs RoBERTa vs ELECTRA
1. BERT
1.1 Introduction
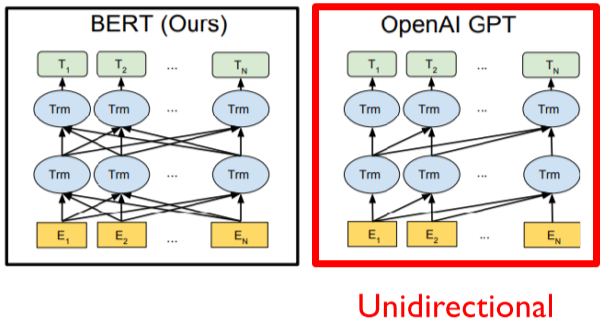
- Motivation: GPT-1이 단어를 보고 다음 단어를 예측(방향성이 없다!)
- 그래서 BERT는 양방향성을 추구!
1.2 Pre-training Tasks
- Masked Language Model (MLM)
- 15%의 단어를 [MASK]라는 Special token으로 치환
- 실제로는 15%중 80%는 [MASK]로, 10% 임의의 단어, 10% 그대로 두었음
- 이렇게 복잡하게 한번 나누고, 또 나눈이유는 검증과정의 객관화를 위해서인 것 같다. 전체에서 12%(15% * 80%)를 추출 할 경우, 매번 어떤 문장에서 어떤 단어들이 변경될지 모수가 커져서 변동이 심할 것이다. 따라서 실험을 할 때마다 그 객관성을 높이기 위해 복잡한 단계를 거친게 아닌가 싶다.
- Next Sentence Prediction
- 한 문장과 임의의 문장을 붙여, 문장의 관계가 다음에 나올 수 있는지 없는지에 대한 학습
- 사용되는 임베딩
- WordPiece embeddings: token embedding vector
- Learned positional embedding: 문장에서 token의 위치 정보
- Segment embedding: 두개 이상의 문장이 들어올 때, 문장의 순서 정보
2. RoBERTa
2.1 Introduction
- Motivation: BERT가 좋은 성능을 내지만 아직 Underfitting 된 상태이다!
- abstract에서 “We find that BERT was significantly undertrained” 라고 언급한다.
- 간단하게 요약하자면, BERT를 더 오래, 더 큰 배치로, 더 많은 데이터를 이용해!
- 목차가 introduction - background - experiments - analysis - roberta 순이다.
- 그래서인지 여긴 모델 architecture 그림이 없다. 그림 없이 논문을 쓰다니 대단한 사람들이다. 즉, 이 논문의 핵심은 BERT를 어떻게 학습해야 더 좋은가? 라고 볼 수 있다.
2.2 Pretraining Task
- 데이터를 10배나 불렸다
- Masked Language Model (MLM)
- masking 중복 방지를 위해, 10가지 방법으로 epoch 마다 각각 다른 masking 방식을 적용 - dynamic masking
- Model Input Format and Next Sentence Prediction
- SEGMENT-PAIR+NSP: BERT가 쓰던 방식
- SENTENCE-PAIR+NSP: contains a pair of natural sentences
- FULL-SENTENCES: Each input is packed with full sentences sampled
- DOC-SENTENCES: Inputs sampled near the end of a document may be shorter than 512 tokens
- Training with large batches
- Text Encoding
3. ELECTRA
3.1 Introduction
- Efficiently learning an Encoder that Classifies Token Replacements Accurately
- 논문의 제목처럼 효율적인 학습을 위해 Adversarial 한 방식을 도입한다.
- Motivation: BERT와 유사한 Language 모델들은 보통 MLM task를 사용해 pretraining을 진행하는데, 이때 상당한 계산량이 필요하다. 이걸 효율적이게 만들고 싶다!
3.2 Pretraining Task
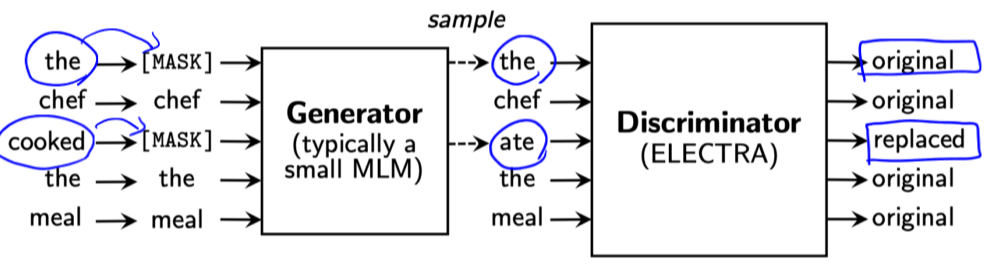
- Masked Language Model (MLM)
- Adversarial Learning
- GAN과 유사하게, Generator와 Discriminator를 두어 pretraining을 진행한다.
- Generator는 BERT의 MLM과 동일하다. Masking된 문장을 입력받아, 토큰을 예측한다.
- Discriminator는 입력 시퀀스에 대해 각 토큰이 original인지 replaced인지를 학습한다.
- 두 모듈은 동일한 BERT 구조를 사용하고, 가중치를 공유할 때 좋은 성능이 나왔다고 한다.
4. Compare
- RoBERTa, ELECTRA는 BERT를 기반으로 하고 있고, 여러가지 문제점들을 개선한 논문이기 때문에, 당연히 논문의 결과를 보면 BERT에 비해 성능이 좋다.
- ELECTRA 또한 RoBERTa 이후에 나온 논문이기 때문에 실험결과는 ELECTRA의 승이다.
4.2 작성중
