
1. Introduction to MRC
1.1 Machine Reading Comprehension의 개념
- 기계 독해
- 주어진 지문(context)를 이해하고, 주어진 질문(Query/Question)의 답변을 추론하는 Task
1.2 MRC의 종류
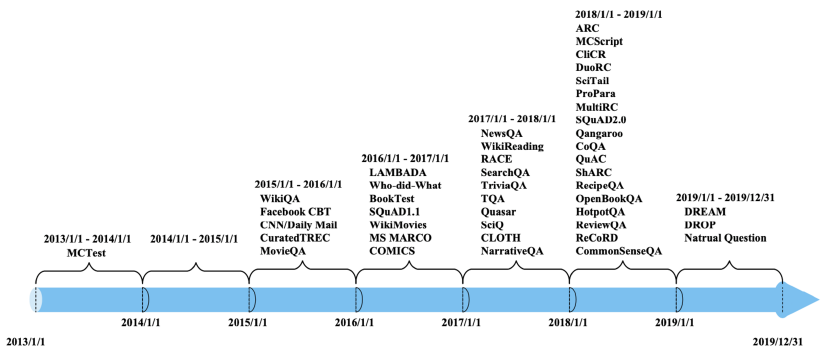
- Extractive Answer Datasets
- 질의에 대한 답이 항상 주어진 지문의 segment로 존재
- SQuAD, KorQuAD, NewsQA, Natural Questions, 등의 데이터 셋 존재
- Decriptive/Narrative Answer Datasets
- 답을 질의를 보고 생성 (free-form)
- MS MARCO, Narrative QA
- Multiple-choice Datasets
- 질의에 대한 답을 여러개의 후보중 고르는 형태
- MCTest, RACE, ARC 등
1.3 Challenges in MRC
- 단어들의 구성이 유사하지는 않지만 동일한 의미의 문장을 이해

- Paraphrasing 예제에서는 P1은 직접적인 언급이 있었지만, P2에서는 간접적으로 Cole이 임무를 수행했다는 것을 언급하고 있다.
- Coreference Resolution 예제에서는 it이 tzykanion을 의미한다는 것을 모델이 이해해야만 정확한 답을 낼 수 있다.
- Unanswerable questions
- 답이 없는 질문을 하는것 (E.g. 주어지는 context에서는 찾을 수 없는 경우)
- SQuAD 2.0에는 No Answer 데이터 셋이 추가됨
- Multi-hop reasoning

- 여러개의 documen에서 질의에 대한 supporting face를 찾아야하는 경우
- HotpotQA, QAngaroo
1.4 MRC의 평가 방법
- Exact Match: 예측한 답과 ground-truth가 정확히 일치하는 샘플 비율
- F1 Score: 예측한 답과 ground-truth 사이의 token overlap을 F1으로 계산
- ROUGE-L: 예측 답과 ground-truth 사이의 overlap recall
- BLEU-N: 예측 답과 ground-truth 사이의 precision (N-gram)
2. Unicode & Tokenization
2.1 Unicode
- 전세계의 모든 문자를 일관되게 표현하고 다룰 수 있도록 만들어진 문자셋
- 각 문자마다 숫자하나에 매칭

- 각 문자마다 숫자하나에 매칭
- 인코딩 & UTF-8
- 인코딩: 문자를 컴퓨터에서 처리할 수 있도록 이진수로 바꾸는 것
- UTF-8 (Unicode Transformation Format)
- 현재 가장 많이 사용
- 문자 타입에 따라 다른 길이의 바이트 할당
- 1 byte: Standard ASCII
- 2 bytes: Arabic, Hebrew, most European scripts
- 3 bytes: Basic Multilingual Plane - 대부분의 현대 글자
- 4 bytes: All Unicode characters - 이모지 등
2.2 python에서 unicode 다루기
-
Python3부터 string 타입은 유니코드 표준을 사용
ord('A') # 65 문자를 유니코드 point로 변환 chr(65) # A 유니코드 point를 문자로 변환
2.3 Unicode와 한국어
- 한국어는 한자 다음으로 유니코드에서 많은 코드 차지
- 완성형
- 자모 조합으로 만들 수 있는 모든 완성형 한글: 11,172자 (가~힣)
- U+AC00 ~ U+D7A3
- 조합형
- 조합하여 글자르 만들 수 있는 초-중-종성
- U+1100 ~ U+11FF, U+A960 ~ U+A97F, U+D780 ~ U+D7FF
chr(0x1100) # ㄱ chr(0x1161) # ㅏ chr(0x1100) + chr(0x1161) # 가 len('가') # 조합형 2 len('가') # 완성형 1
2.4 토크나이징
- 텍스트를 토큰 단위로 나누는 것
- 단어, 형태소, subword 등 여러 토큰 기준 사용
- Subword 토크나이징
- 자주 쓰이는 글자 조합은 한 단위로 취급, 자주 사용되지 않는 조합은 subword로 쪼갬
- ##은 디코딩을 할 때 해당 토큰을 앞 토큰에 띄어쓰기 없기 붙이는 것을 의미

2.5 Byte-pair Encoding
- 데이터 압축용으로 제안된 알고리즘
- NLP에서 토크나이징용으로 활발하게 사용중
- 가장 자주 나오는 글자 단위 Bigram(or Byte pair)를 다른 글자로 치환
- 치환된 글자 저장
- 1~2번 반복
3. Looking into the Dataset
3.1 KorQuAD 훓어보기
- LG CNS에서 AI 언어지능 연구를 위해 만든 질의응답/기계독해 한국어 데이터셋
- 1,550개의 위키피디아 문서, 10,649 건의 하위 문서를 이용해 크라우드 소싱을 통해 제작한 63,952개의 질의 응답 쌍으로 구성됨
- Train 60,407 / DEV 5,774 / TEST 3,898
- 누구나 데이터를 받아 공개된 리더보드에 평가를 받을 수 있음
- 1.0v, 2.0v -> 2.0에는 복잡한 HTML 형태로 포함되어있음
- 대상 문서 수집
- 위키 백과에서 수집한 글들을 문단 단위로 정제, 이미지/표/URL 제거
- 짧은 문단, 수식이 포함된 문단 등 제거
-
Hugging face를 이용해 간단하게 다운가능
from datasets import load_dataset dataset = load_dataset('squad_kor_v1', split='train')
3.2 예시

4. 참조
- Naver Ai bootcamp MRC 강의
- 문자열 type에 관련된 정리글
- KorQuAD 데이터 소개 슬라이드
- Naver Engineering: KorQuAD 소개 및 MRC 연구 사례 영상