
1. Extraction-based MRC
1.1 Extraction-based MRC
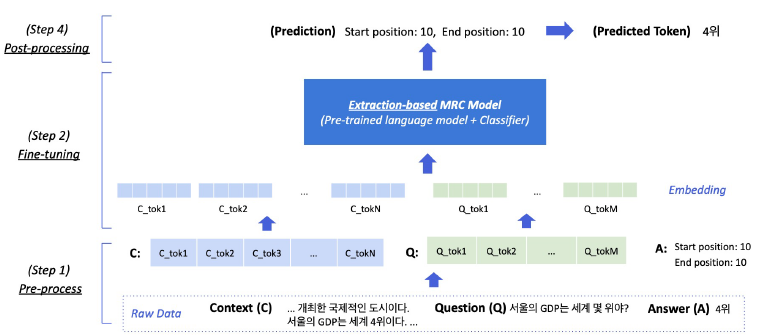
- 질문에 대한 답변이 항상 지문 내에 존재
- 답변을 생성하는 것이 아니라 찾는 것이기 때문에 약간 편한 느낌
- 평가방법
- EM, F1-score
2. Pre-processing
2.1 Tokenization
- 최근에는 Byte Pair Encoding을 주로 사용함 상세!
- BPE 중 WordPiece Tokenizer
- E.g. “미국 군대 내 두번째로 높은 직위는 무엇인가?”
- 미국 / 군대 / 내 / 두번째 / ##로 / 높은 / 직 / ##위는 / 무엇인가 / ?
2.2 Special Tokens
- 문장 시작: [CLS] 토큰
- 알수 없는 토큰: [UNK] 토큰
- Padding 토큰 : [PAD]
2.3 Attention Mask
- 입력 시퀀스 중에서 attention 연산시 무시할 토큰 표시
- 0: 무시, 1: 연산 포함
- 보통 [PAD] 토큰을 무시하기 위해 사용
2.4 Token Type IDs
- 입력이 2개 이상의 시퀀스일때, 각 문장에 ID 부여
- [PAD] 토큰과 질문 부분을 0으로 해서 정답 범위에서 제외
3. Fine-tuning
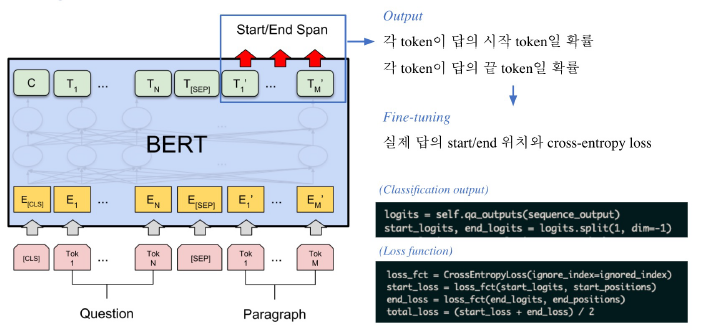
- Base 모델의 임베딩 벡터들을 이용
- 각 토큰들이 답의 시작일 확률과 끝일 확률을 계산해, 실제 답의 위치와 Crossentropy loss로 학습
4. Post-processing
- 불가능한 답 제거하기
- End position이 start position 보다 앞에 있는 경우
- 예측한 위치가 context를 벗어난 경우 (E.g 질문 쪽에서 답이 나온 경우)
- 미리 설정한 max_answer_length 보다 길이가 더 긴 경우
- 최적의 답안 찾기
- Start/end position logits가 가장 높은 N개를 각각 찾는다.
- 불가능한 start/end 조합 제거
- 가능한 조합을 score의 합이 큰 순서대로 정렬
- score가 가장 큰 조합을 최종 예측으로 선정
- Top-k가 필요한 경우 차례대로 내보냄
5. Hugging face로 활용해보기
-
필요한 라이브러리 설치
pip install datasets==1.4.1 pip install transformers==4.4.1 git clone https://github.com/huggingface/transformers.git -
Dataset 다운로드
from datasets import load_dataset datasets = load_dataset("squad_kor_v1") -
Pretrained 모델 불러오기
from transformers import AutoConfig, AutoModelForQuestionAnswering, AutoTokenizer model_name = "bert-base-multilingual-cased" config = AutoConfig.from_pretrained( model_name ) tokenizer = AutoTokenizer.from_pretrained( model_name, use_fast=True ) model = AutoModelForQuestionAnswering.from_pretrained( model_name, config=config ) -
Hyper paremters 셋팅하기
max_seq_length = 384 # 질문과 컨텍스트, special token을 합한 문자열의 최대 길이 pad_to_max_length = True doc_stride = 128 # 컨텍스트가 너무 길어서 나눴을 때 오버랩되는 시퀀스 길이 max_train_samples = 16 max_val_samples = 16 preprocessing_num_workers = 4 batch_size = 4 num_train_epochs = 2 n_best_size = 20 max_answer_length = 30 -
Fine-tunning 하기
training_args = TrainingArguments( output_dir="outputs", do_train=True, do_eval=True, learning_rate=3e-5, per_device_train_batch_size=batch_size, per_device_eval_batch_size=batch_size, num_train_epochs=num_train_epochs, weight_decay=0.01, ) trainer = QuestionAnsweringTrainer( model=model, args=training_args, train_dataset=train_dataset, eval_dataset=eval_dataset, eval_examples=datasets["validation"], tokenizer=tokenizer, data_collator=default_data_collator, post_process_function=post_processing_function, compute_metrics=compute_metrics, ) train_result = trainer.train() -
평가하기
metrics = trainer.evaluate()
6. 참조
- Naver Ai bootcamp MRC 강의
- SQuAD 데이터셋
- How NLP Cracked Transfer Learning
- Huggingface datasets