Passage Retrieval - Sparse Embedding
1. Introduction to Passage Retrieval
1.1 Passage Retrieval
- 질의에 맞는 문서를 찾는것
- Open-domain QA를 가능하게 하기 위해서 사용
1.2 Overview
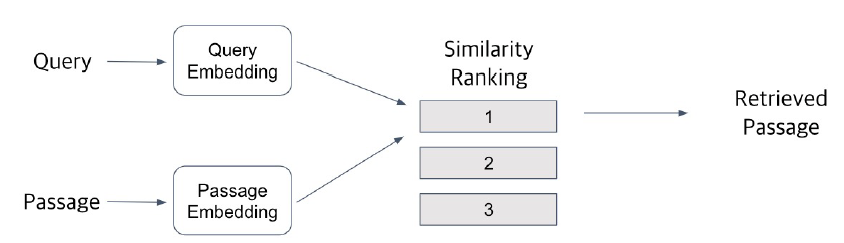
- 유사도 판단 기준
- 고차원 공간에서 임베딩 벡터 간의 거리
- dot product로 가장 높은 score 계산
2. Passage Embedding and Sparse Embedding
2.1 Passage Embedding Space
- Passage embedding 벡터 들의 공간
- 이 공간상에서 거리등 을 활용해 유사도를 계산할 수 있음
2.2 Sparse Embedding
- Sparse: 0이 아닌 값이 굉장히 많이 있는 것을 의미 #############
- Bag of words
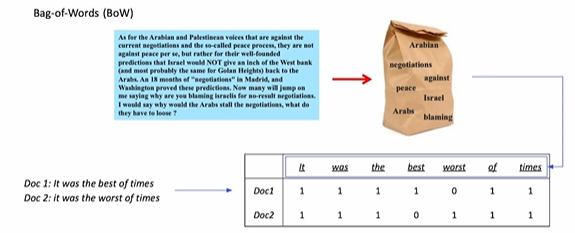
- 단어가 있으면 1, 없으면 0으로 표시
- Voca가 많으면 엄청 큰 차원의 벡터가 됨
- 구성하는 방법
- n-gram (unigram / bigram) => n이 늘어날수록 기하 급수적으로 voca 크기가 증가
- Term value를 결정하는 방법
- Term이 document에 등장하는지 (binary)
- Term이 몇 번 등장하는지 (E.g TF-IDF)
- 특징
- Dimesion of embedding vector = number of terms
- Term overlap을 정확하게 잡아 내야 할 때 유용
- 반면, 의미가 비슷하지만 다른 단어인 경우 비교가 불가
3. TF-IDF
3.1 Intro
- Term Frequency (TF): 단어의 등장 빈도
- Inverse Document Frequency (IDF): 단어가 제공하는 정보의 양
- 문서 내에 자주 등장했지만, 전체 문서에서는 별로 등장하지 않았으면, 중요한 단어이다.
- 예를 들어 it, was, the, of 같은 것은 자주 등장하지만 정보가 적음
3.2 Term Frequency
- TF를 구하는 방법
- Raw count
- Adjust for doc length: raw count / num words
- Other variants: binary, log normalization, etc
- 등장하는 단어의 빈도 수를 전체 단어의 수로 나누어준다.
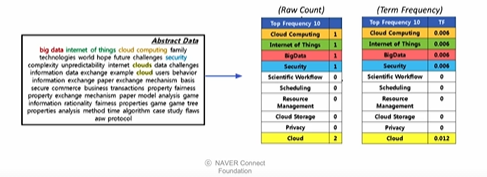
3.3 Inverse Document Frequency
- IDF를 구하는 방법
- $IDF(t) = log {N \over DF(t)}$
- $DF(t)$ : Term t가 등장한 document의 개수, N: 총 document 수
- 모든 문서에 등장하는 단어는 $DF(t)$ 값이 1이되고 이를 log 취했을 때 0이된다.
3.4 TF-IDF
- TF와 IDF를 결합
- $TF-IDF(t, d)=TF(t,d) \times IDF(t)$
- a, the 등의 관사는 TF-IDF score가 낮음
- 자주 등장하지 않는 고유 명사는 score가 높음
- IDF가 커지면서 전체적인 TF-IDF값이 증가
3.5 BM25
- TF-IDF의 변형, 문서의 길이 까지 고려하여 점수 부여
- TF 값에 한계 지정 (일정 범위 값 유지)
- 평균적인 문서의 길이 보다 더 작은 문서에서 단어가 매칭된 경우 그 문서에 가중치를 부여
- 실제 검색엔진이나 추천 시스템 등에서 아직까지 많이 사용중인 알고리즘
- 계산 방법
- $Score(D,Q)=\sum_{term \in Q} IDF(term) \cdot {TF(term, D) \cdot (k_1 + 1) \over TF(term, D) + k_1 \cdot (1-b +b \cdot {\vert D \vert \over avgdl})}$
- $k_1$ : 하이퍼 파라미터, 보통 1.2 or 2.0 사용
- $b$ : 보통 0.75
- $avgdl$ : 평균 문서의 길이
- $D$ : 검색된 문서의 길이
- $Score=IDF \cdot tfNorm$ 형태
- 참고
4. 예시
4.1 데이터
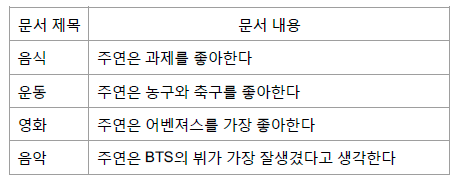
4.2 토큰화

- 주연은 $\rightarrow$ 모든 문서에 등장하기 때문에 IDF 값이 낮음
- 문장의 핵심인 과자, 농구, 축구, 어벤져스 등의 정보가 많이 담긴 토큰은 TF는 낮을 수 있지만, IDF 값이 높은 것을 볼 수 있다.
5. 참조
