
1. Introduction to Dense Embedding
1.1 Passage Embedding
- Passage를 벡터로 변환 하는 것
- Sparse embedding
- 한계
- 차원의 수가 매우 큼
- 유사성을 고려하지 못함
- 한계
- Dense embedding
- 더 작은 차원의 고밀도 벡터
- 대부분의 알고리즘에서 활용 가능
- 각 차원이 특정 term에 대응되는 것이 아님
- 단어의 유사성 또는 맥락을 파악하는 성능이 뛰어남
- 학습을 통해 임베딩을 만들며, 추가적 학습이 가능
- 사전학습 모델의 등장으로, Dense embedding이 더 많이 사용됨
- 대부분의 요소가 non-zero 값

- 더 작은 차원의 고밀도 벡터
1.2 Overview
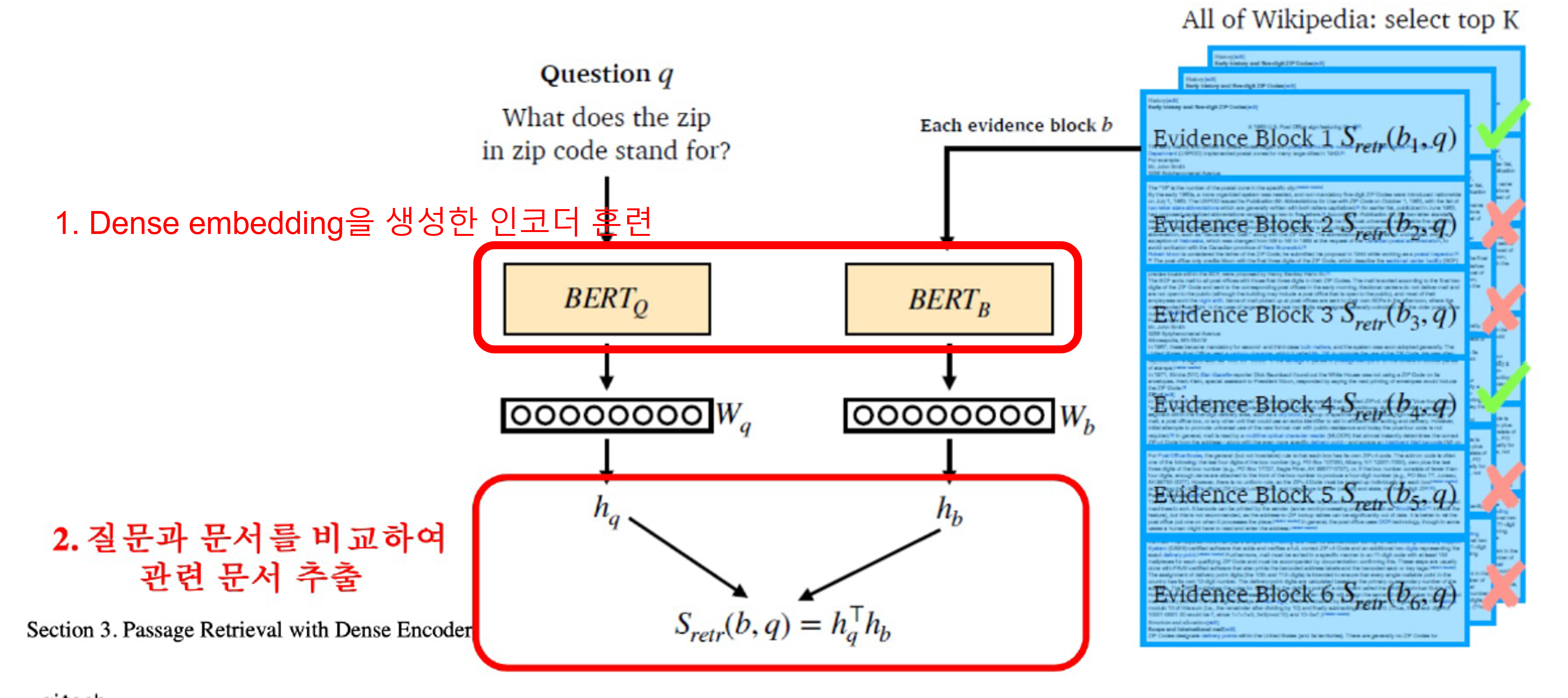
- 주의점: question과 passage 임베딩 벡터의 차원이 동일해야한다.
2. Training Dense Encoder
2.1 What can be Dense Encoder
- BERT와 같은 PLM (Pre-trained launguage model)이 자주 사용됨
- [CLS] 토큰을 활용해 passage 임베딩
- 그 외 다양한 신경망 구조도 가능
2.2 학습 목표 및 학습 데이터
- 연관된 question과 passage dense embedding 간의 거리를 좁히는 것
- 즉, 유사성을 높이는 것
- 연관된 question과 passage를 어떻게 찾을 것인가?
- 기존 MRC 데이터셋을 활용해서 학습
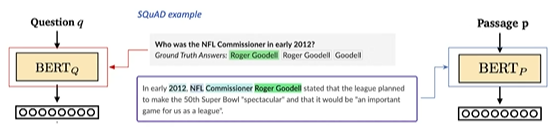
- 기존 MRC 데이터셋을 활용해서 학습
2.3 Negative Sampling
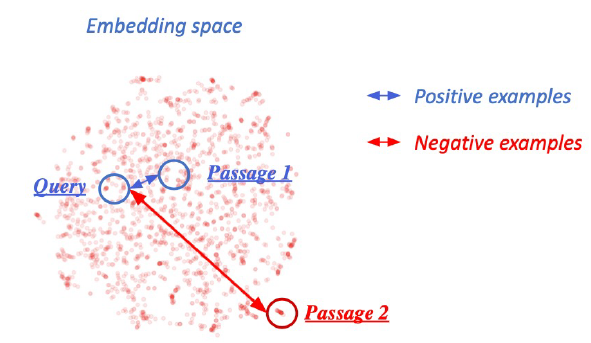
- 연관된 question과 passage 사이는 거리를 좁히고
- 연관되지 않은 question과 passage 사이는 거리를 멀리하는 것
- 효과
- 보통 유사한 샘플들만 모아 가까워 지게 학습하는 것 보다는 연관 되지 않는 샘플까지 넣어서 같이 학습하면 학습 효율이 더 좋다고 한다.
- Word2Vec 계열 에서도 사용된다.
- Negative sample을 뽑는법
- 랜덤하게 뽑기
- 좀더 헷갈리는 샘플들 뽑기
- 목적함수
- negative log likelihood (NLL) loss 사용
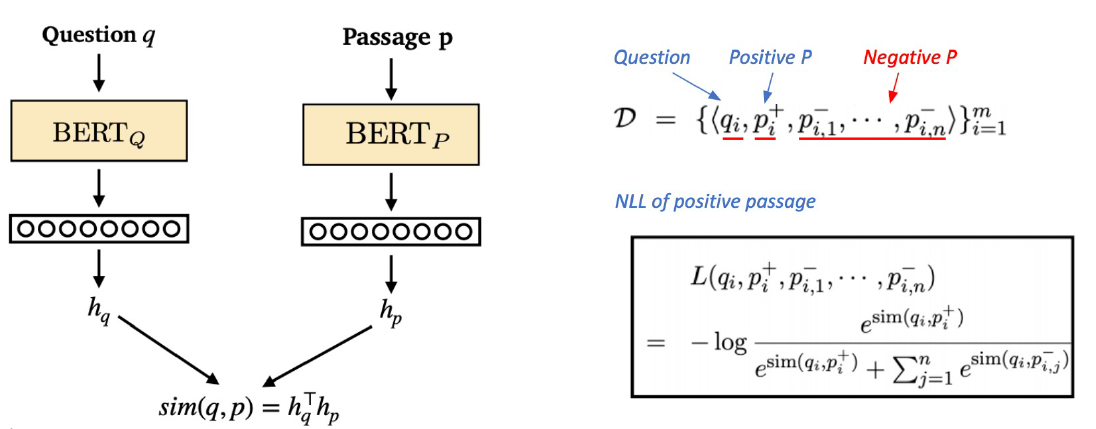
- negative log likelihood (NLL) loss 사용
3. Passage Retieval with Dense Encoder
3.1 Inference
- question과 passage를 각각 임베딩 하고, question과 유사한 순으로 passage의 순위를 매김
- 순위를 매긴 passage를 활용, MRC 모델로 답을 찾음
3.2 Dense encoding을 더 잘하게 만드는 방법
- 학습 방법 개선 (E.g DPR-Dense Passage Retrieval)
- 인코더 모델 개선 (BERT보다 큰, 정확한 Pretrained 모델 사용)
- 데이터 개선 (더 많은 데이터, 전처리, 등)
4. 참조
- Naver Ai bootcamp MRC 강의
- Dense Passage Retrieval for Open-Domain Question Answering
- Open domain QA tutorial: Dense retrieval