1. Introduction to Open-domain Question Answering (ODQA)
1.1 Linking MRC and Retrieval
- MRC: 지문이 주어진 상황에서 답을 찾는 것
- Open-domain Question Answering (ODQA)
- 지문이 주어지지 않고, 방대한 World knowledge에 기반해서 질의 응답
- E.g. Modern search engines: 검색뿐 아니라 답까지 제공
1.2 History of ODQA
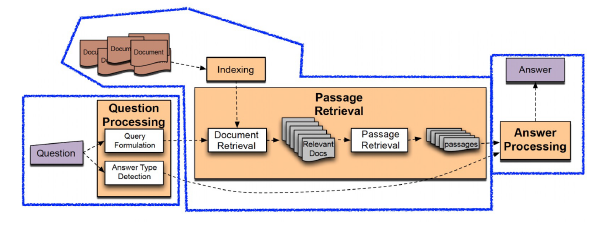
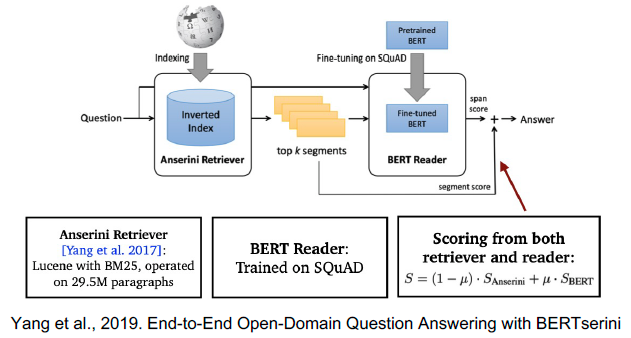
- Text retrieval conference (TREC) - QA Tracks (1999-2007): 연관문서만 반환하는 information retrieval (IR)에서 더 나아가, short answer with support 형태가 목표
- Question processing
- 질문으로 부터 키워드를 선택 / Answer type selection
- Passage retrieval
- 기존의 IR 방법을 활용해 연관된 document를 뽑고, passage 단위로 자른 후에 선별
- Named entity / Passage 내 question 단어의 개수 등과 같은 hand-craft features 활용
- Answer processing
- Hand-craft features와 heuristic을 활용한 classifier
- 주어진 question과 선별된 passage들 내에서 답을 선택
- Question processing
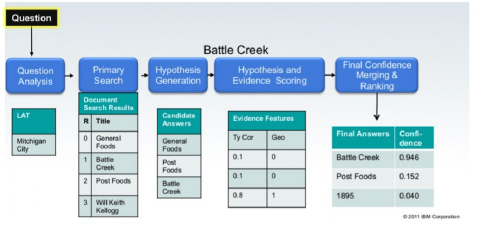
- IBM Watson (2011)
- The DeepQA Project
- Jeopardy! (TV quiz show) 우승
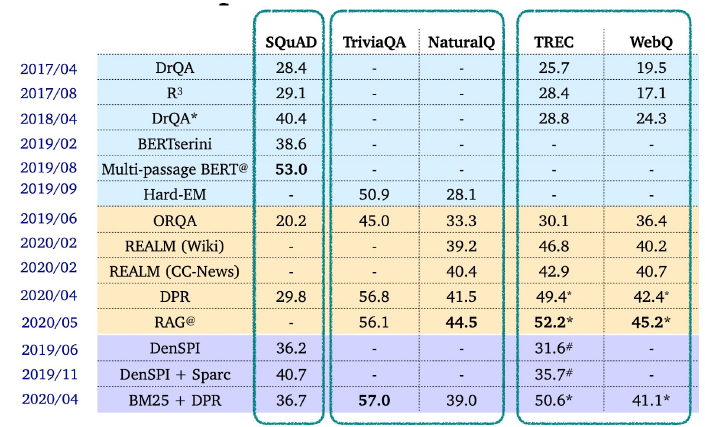
1.3 Recent ODQA Researches
2. Retriever-Reader Approach
2.1 Intro
- Retriever: 데이터베이스에서 관련있는 문서를 검색(search) 함
- 입력 - 문서셋, 질문
- 출력 - 관련성 높은 문서
- 학습 단계
- TF-IDF, BM25 -> 학습 없음
- Dense -> 학습 있음
- Reader: 검색된 문서에서 질문에 해당하는 답을 찾아냄
- 입력 - retrieved된 문서
- 출력 - 답변
- 학습 단계
- SQuAD와 같은 MRC 데이터셋으로 학습
- 학습 데이터를 추가하기 위해서 Distant supervision 활용
2.2 Distant supervision
- 질문 - 답변만 있는 데이터셋에서 MRC 학습 데이터 만들기
- Supporting document가 필요
- 관련성 높은 문서를 검색
- 너무 짧거나 긴 문서, 질문의 고유명사를 포함하지 않는 등 부적합한 문서 제거
- answer가 EM로 들어있지 않은 문서 제거
- 남은 문서 중 질문과 연관성이 가장 높은 단락을 supporting evidence로 사용
- Supporting document가 필요
2.3 Inference
* Retrieval가 질문과 가장 관련성 높은 5개 문서 출력
* Reader는 5개 문서를 읽고 답변 예측
* Reader가 예측한 답변 중 가장 score가 높은 것을 최종 답으로 사용함
3. Issues and Recent Approach
3.1 Different granularities of text at indexing time
- 위키피디아에서 각 Passage의 단위를 문서, 단락, 또는 문장으로 정의할지 정해야함
- Retriever 단계에서 몇개(top-k)의 문서를 넘길지?
- Granularity에 따라 k가 다를 수 밖에 없음

3.2 Single-passage training vs Multi-passage training
- Single-passage
- k개의 passages 확인하고, 특정 answer span에 대한 예측 점수 중 가장 높은 점수를 가진 것을 선택
- 이 경우 각 retrieved passages들에 대한 직접적인 비교라고 볼 수 없음
- 따로 reader 모델이 보는 게 아니라 전체를 한번에 보면 어떨까?
- Multi-passage
- retrievec passages 전체를 하나의 passage로 취급하고, reader 모델이 그안에서 answer span 하나 찾도록 학습
- 문서가 너무 길어지므로 GPU에 더 많은 메모리를 할당해야함, 연산량 상승
3.3 Importance of each passage
- Retriever 모델에서 추출된 top-k passage들의 retrieval score를 reader 모델에 전달