Reducing Training Bias
1. Definition of Bias
1.1 Bias 종류
- Bias in learning
- 학습할 때 과적합을 막거나 사전 지식을 주입하기 위해 특정 형태의 함수를 선호 하는 것 (inductive bias)
- A Biased World
- 현실 세계가 편향되어 있어 원치않는 속성이 학습 되는 것 (historical bias)
- 성별과 직업 간 관계 등 표면적인 상관관계 때문에 원치 않는 속성이 학습 되는 것 (co-occurrence bias)
- Bias in Data Generation
- 입력과 출력을 정의한 방식 때문에 생기는 편향 (specification bias)
- 데이터를 샘플링한 방식 때문에 생기는 편향 (sampling bias)
- 어노테이터의 특성 때문에 생기는 편향 (annotator bias)
1.2 Examples
- Gender bias: 특정 성별과 행동을 연계
- Cooking에 대해 여자와 관련된 데이터 가 더 많이 때문에, 남자가 cooking하는 데이터를 주어도 여자로 예측하는 문제
- Sampling bias: 리터러시 다이제스트 여론조사
- 표본 크기: 240만명
- 예측: 루즈벨트 43%, 알프레드 57% -> 실제: 루즈벨트 62%, 알프레드 38%
- 설문 대상: 중산층 이상으로, 표본이 왜곡됨
- 결과: 설문 조사 결과와 다르게 나옴
2. Bias in Open-domain Question Answering
2.1 Retriever-Reader Pipeline
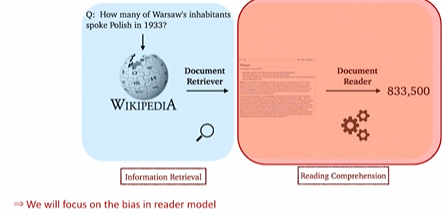
2.2 Training bias in reader model
- 만약 reader 모델이 한정된 데이터셋에서만 학습이 된다면!
- reader는 항상 정답이 문서 내에 포함된 데이터쌍만을 보게 된다.
- 특히 positive가 완전히 고정되어 있는 데이터 셋을 많이 사용 (SQuAD)
- inference시 만약 데이터 내에서 찾아볼 수 없었던 새로운 문서를 준다면?
- Reader 모델은 문서에 대한 독해 능력이 매우 떨어질 것이다. 또한 정답도 찾지 못할 가능 성이 높다.
2.3 How to mitigate training bais?
- Train negative examples
- 훈련시 잘못된 예제를 보며주는 것으로, retriever가 negative한 내용(주어진 쿼리와 상관 없는 내용들을)을 벡터 공간상에서 멀어지게 배치할 수 있음
- 더 세세하게, negative한 정도에 따라서 거리를 조절하기 위한 방법 또 고려해야함
- 방법
- Corpus내에서 랜덤하게 뽑기
- 좀더 헷갈리는 negetive 샘플들 뽑기
- Add no answer bias
- 입력 시퀀스의 길이가 N일때, 시퀀스의 길이 외 1개의 토큰이 더 있다고 생각
- 훈련 모델의 마지막 레이어 weight에 훈련가능한 bias를 하나더 추가
- softmax로 answer prediction을 최정적으로 수행할때, start end 확률이 추가한 bias 위치에 있을 경우의 가장 확률이 높으면 no answer라고 취급
3. Annotation Bias from Datasets
3.1 What is annotation bias?
- ODQA 학습 시 기존의 MRC 데이터셋 활용
- ODQA 세팅에는 적합하지 않은 bias가 데이터 제작 단계에서 발생 할 수 있음
- 질문 하는 사람이 답을 알고 있는 상태로 데이터가 제작되기 때문
- 문서내에 답과 단어가 겹치는 bias가 발생할 가능성이 높음
- 단어의 Over lab으로 인해, SQuAD에서만 다른 형상
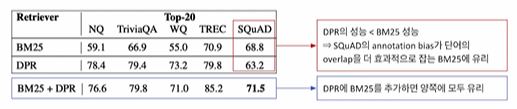
- DPR이 더 성능이 좋다고 알려져 있는데 SQuAD 데이터 셋에서만 그렇지 않은 것을 볼 수 있다. annotation bias가 단어의 overlab을 유도하게 되고, 단어의 overlab은 BM25 알고리즘에게 굉장히 유리한 조건이 된다. 왜냐하면, BM25는 Sparse한 단어 기반의 embedding이기 때문에, 단어가 동일하면 더 쉽게 가져 올 수 있다. DPR+BM25를 사용하면 양쪽에 모두 좋다.
3.2 Another bias in MRC dataset
- ODQA에 적합하지 않은 질문들이 존재
- 시기적으로 답이 달라 질 수 있는 질문
- 대통령의 이름은? -> passage가 주어진다면 안에서 답을 찾으면 되지만, ODQA인 경우 그 시기에 따라 답이 달라 질 수 있다.
4. 참조
