Closed-book QA with T5
1. Closed-book Question Answering
1.1 Current approach of building QA system
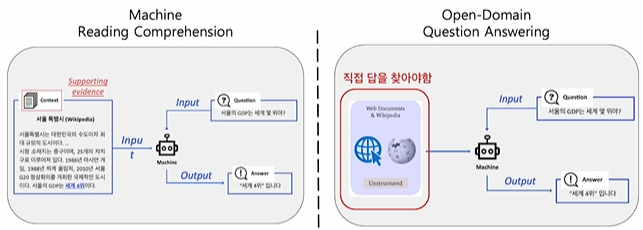
- 지금까지는 문서가 주어지거나, 주어지지 않은 경우 문서를 검색해서 답을 찾는 방식을 사용해 왔음 (~2018)
1.2 Idea of Closed-book QA
- 모델이 이미 사전학습으로 대량의 지식을 학습했다면, 사전 학습 언어 모델 자체가 이미 하나의 knowlege storage라고 볼 수 있지 않을까?
- 굳이 다른 곳에서 지식을 가져와야 할 필요가 있나?
- Zero-shot QA performance of GPT-2

- 전혀 본 적없는 Natural Questions 데이터 셋에도 어느 정도 대답이 가능 했음
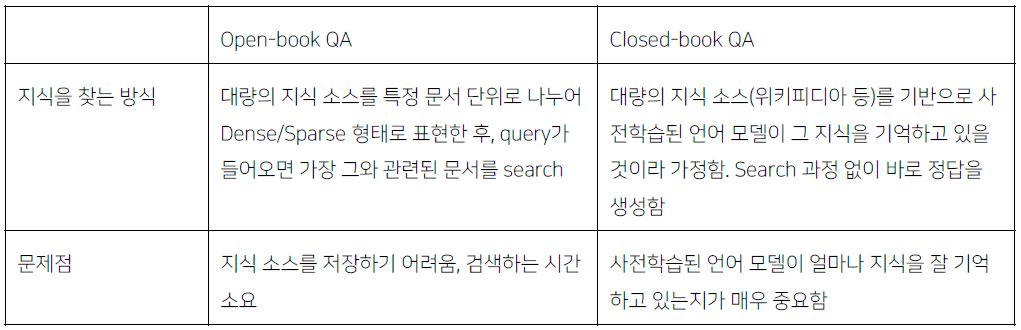
- Open-book QA vs Closed-book QA
2. Text-to-Text Format
2.1 Closed-book QA as Text-to-Text Format
- Generation-based MRC와 유사함
- 단, 입력에 지문이 없이 질문만 들어감
- 사전 학습된 언어모델은 Seq-to-seq 형태 transformer 모델 사용
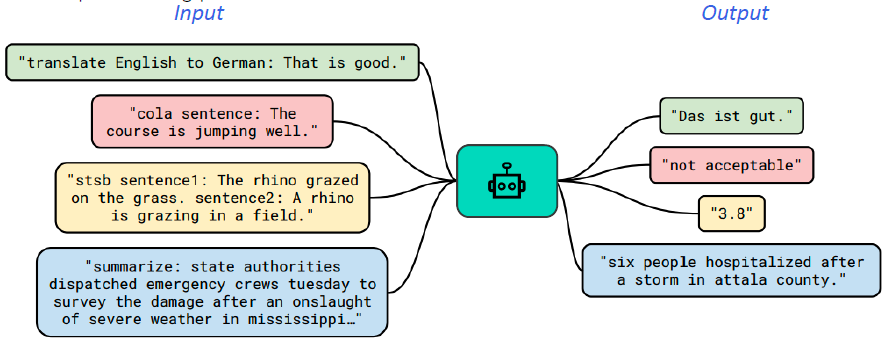
- Text-to-Text format에서는 각 입력값과 출력값에 대한 설명을 맨앞에 추가
- text를 받아 text를 생성하는 문제!
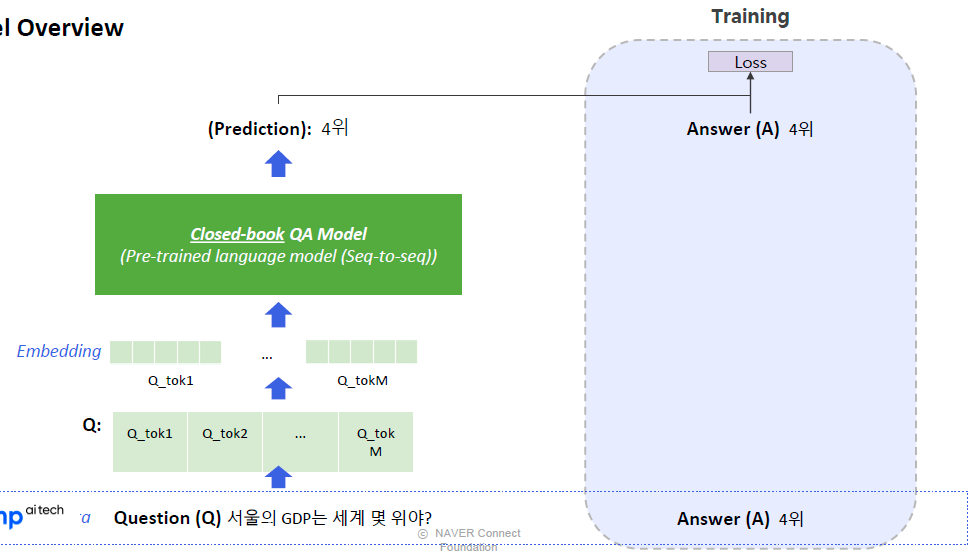
2.2 Model Overview
- Text-to -Text format 이라는 형태로 데이터의 입출력을 만들어 거의 모든 자연어처리 문제를 해결하도 록 학습된 seq -to -seq 형태의 Transformer 모델
- pre-training
- 다양한 모델 구조, 사전학습 목표, 사전학습용 데이터, Fine Fine-tuning 방법 등을 체계적으로 실험함 가장 성능이 좋은 방식들을 선택하여 방대한 규모의 모델을 학습시킴
- fine-tuning
- pre-trained T5 활용
- MRC 데이터셋의 QA piar 활용 (TriviaQA, WebQuestions, Natural Questions)
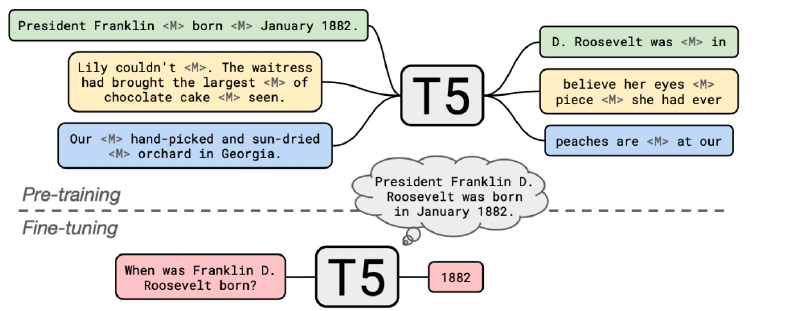
- input에 특정 task를 의미하는 prefix 추가
3. Experiment Results & Analysis
3.1 Experiment Setting
- Dataset
- Open-domain QA 데이터셋 또는 MRC 데이터셋에서 지문을 제거하고 질문과 답변만 남긴 데이터 활용
- Sailent Span Masking
- 고유 명사, 날짜 등 의미를 갖는 단위에 속하는 토큰 범위를 마스킹한 뒤 학습, pre-trained 체크포인트에서추가로 pre-training 함
- bert의 경우 랜덤으로 masking 하기 때문에, it, this와 같이 별 의미가 없는 단어가 masking 되기도 해서 비효율 적인 면이 있었음
- Fine-tuning
- Pre-tarined T5 체크포인트를 Open-domain QA 학습 데이터 셋으로 추가 학습
3.2 T5 를 이용한 Closed -book Question Answering 예시

3.3 False negaives

- Exact match 기준으로 오답으로 채점된 결과를 사람이 평가한 결과 오답이 아닌 경우
- Phrasing Mismatch: 정답에 대한 표현이 다른 경우
- Incomplete Annotation: 정답이 여러 개일 수 있으나 하나만 정답으로 처리 되는 경우
- Unanswerable: 질문을 한 시간이나 문맥에 따라서 정답이 달라지는 경우
3.4 Limitations
- 모델의 크기가 커서 계산 복잡도가 높음
- 모델이 어떤 데이터로 답을 내는지 알 수 없음 (해석 가능성이 없음)
- 모델이 참조하는 지식을 추가, 제거, 업데이트 하기 어려움
4. 참조
