QA with Phrase Retrieval
1. Phrase Retrieval in Open-Domain Question Answering
1.1 Current limitation of Retriever-Reader approach
- Error Propagation: 5-10개의 문서만 reader에게 전달됨
- 항상 올바른 문서를 가져다 준다는 보장이 없음
- Query-dependent encoding: query에 따라 정답이 되는 answer span에 대한 encoding이 달라짐
- query가 달라지면 context 임베딩을 다시 전부 진행해야함
1.2 How does Document Search work?
- Retrieve-Reader 두 단 계 말고 정답을 바로 search 할 수는 없을까?
- Solution: Phrase Indexing
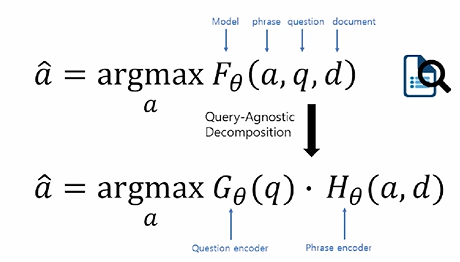
- 기존의 MRC 문제: F라는 scoreing function을 구하는 문제
- a와 d는 동일한데 새로운 질문이 들어올 때마다, F를 다시 계산해 주어야 한다.
- 모든 phrase의 key vector를 만들어 두고, query vector가 들어오면 유사도만 계산하는 방법
- G만 다시 계산하면 된다.
- 하지만, F가 G와 H로 나누어 질 수 있다는 강력한 가정이 들어가 있다는 한계가 있다.
2. Dense-sparse Representation for Pharase
2.1 Dense vectors vs Sparse vectors
- Dense: 통사적, 의미적 정보를 담는 데 효과적
- Sparse: 어휘적 정보를 담는 데 효과적
- E.g
- 아이슈타인과 테슬라를 비교한다면, 둘다 과학자라 유사한 그룹에 속할 수 있지만 둘은 완전히 다른사람이다. 둘을 완전히 구분하고 싶다면 sparse vector가 더 fit하다.
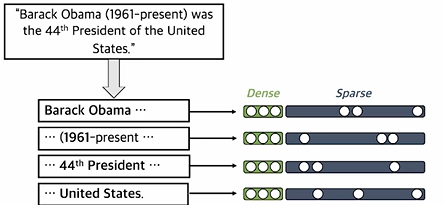
2.2 Phrase and Question Embedding
- Dense와 sparse를 모두 사용하여 임베딩
2.3 Dense representation
- Pre-trained LM을 이용
- Start vector와 end vector를 재사용해서 메모리 사용량을 줄임
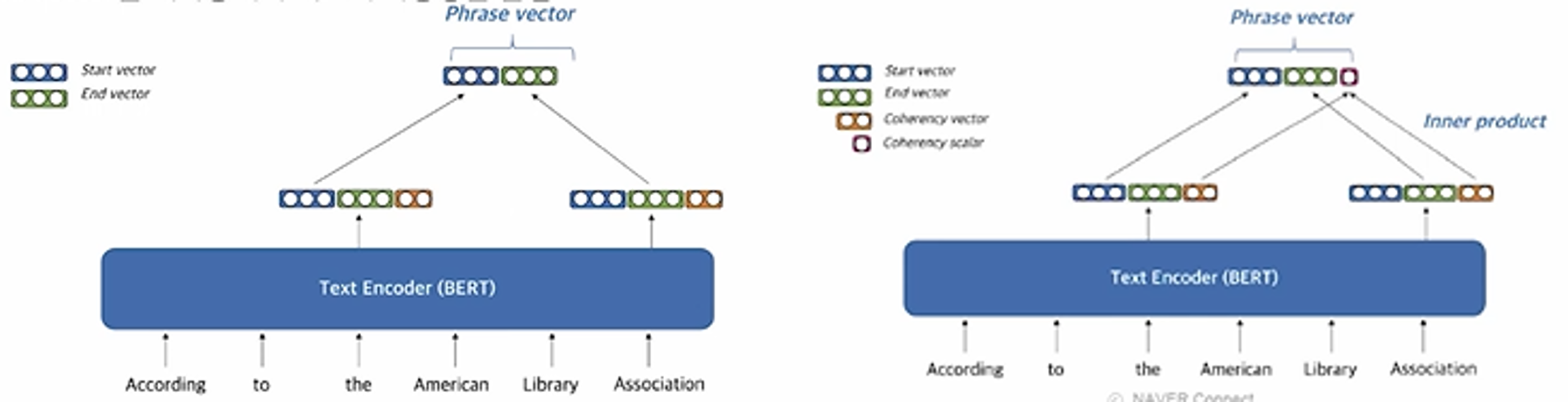
- “the American Library Association”에 대한 임베딩 벡터를 얻고자 한다면, 시작단어인 the와 마지막 단어인 Association의 벡터를 가져와 붙인다. 마지막에 하나의 숫자를 붙이면서, 정답이 될만한 phrase인지 아닌지 판단한다.
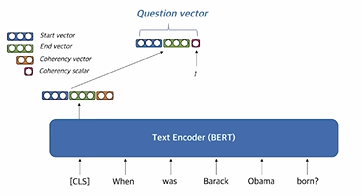
- Question embedding
- [CLS] token을 활용
2.4 Sparse representation
- Contextualized embedding을 활용하여 가장 관련성이 높은 n-gram으로 sparse vector 구성
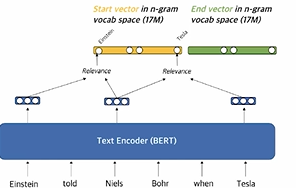
- 타겟으로 하고있는 phrase의 주변에 있는 단어들과 유사성을 계산에, 그 유사성을 각 단어에 해당하는 sparse dimension vector에 넣어줌으로써, 일종의 TF-IDF와 유사하지만, TF-IDF와 다르게 각 문장마다 phrase마다 weight가 변하게 dynamic한 형태로 만들어 줄 수 있다.
2.5 Scalability Challenge
- 위키피디아에는 60 bilion 개의 pharase가 존재
- Storage, indexing, search의 scalability가 고려되어야 한다.
- Storage
- Pointer, filter, scalar quantization 활용
- Search
- FAISS를 활용해 dense vector에 대한 search를 먼저 수행한 후, sparse vector로 reranking을 진행한다.
- FAISS는 dense vector에 대한 search만 지원!
3. Experiment Results & Analysis
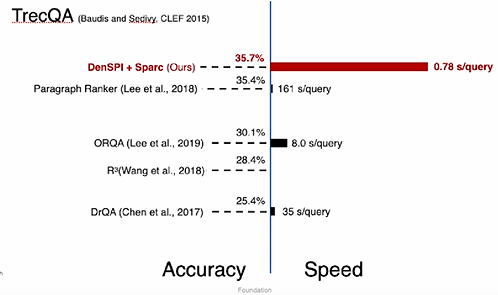
3.1 Experiment Results - SQuAD-open
3.2 Limitation
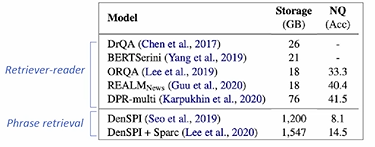
- 큰 저장공간이 필요: 2TB SSD for phrases
- 최신 Retriever-reader 모델들 대비 낮은 성능
4. 참조
