
1. 정보
- 논문명: Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks
- 학회: Advances in Neural Information Processing Systems
- 저자 소속:
- Facebook AI Research
- University College London
- New York University
2. 논문 분석
2.1 Limitation of previous research
- Large pre-trained LM (parametric methods)
- Factual knowledge를 parameter안에 저장
- Fine-tuning을 통해 downstream NLP task들에서 SOTA 성능 달성
- Limitation
- 지식에 접근하고 다루는 능력은 여전히 부족
- 결과에 대한 근거와 새로운 지식을 update하는 것 또한 아직 challengeable
- 변화하는 지식을 쉽게 확장, 수정하기가 어려움
- Retrieval + Reader (Non-parametric methods + parametric methods)
- 활발히 연구되고 있는 방법론
- Query에 해당하는 최신 문서를 탐색해(retrieval), task 수행
- 대표적인 연구들: REALM, ORQA
- Limitation
- extractive downstream task에 대해서만 연구되고 있음
2.2 Propesed method overview
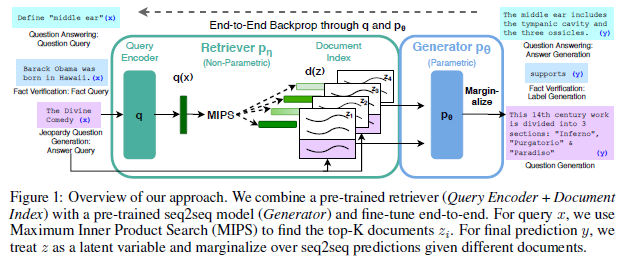
- Retrieval-augmented generation (RAG)
- Generative model with non-parametric memory
- Models
- Parametric model: pre-trained Seq2seq transformer (Reader) * BART
- Non-parametric model: dense vector index of Wikipedia (Retrieval)
- Train
- End-to-end 학습
- Retrieval: 쿼리에 맞는 tok-k latent documents (백터내적 유도사도 기반)
- Reader: input과 retrieval의 결과를 합쳐 output 생성
- Two approach
- 같은 문서를 활용해 모든 토큰을 생성 (RAG-Sequence)
- 각 토큰마다 다른 문서를 활용해 생성 (RAG-Token)
- 아무 seq2seq task에 대해 fine-tuning 가능
2.3 Notations
- 𝑥: input sequence
- 𝑧: retrieve text documents
- 𝑦: target sequence
- $P_\eta (𝑧 \vert 𝑥)$ : retriever, query x가 주어진 텍스트 구절에 대한 (상위 K개) distributions를 반환
- $𝑃_\theta (𝑦_𝑖 \vert 𝑥,𝑧,𝑦_{1:𝑖−1})$ : generator, 이전 i-1개의 토큰과 입력 x, 검색된 문서 z를 이용해 현재 토큰을 생성
2.4 Models
- RAG-Sequence Model
- 완전한 문장을 생성하는데 동일한 retrieved document 사용
- retrieved document를 단일 latent variable로 취급
- Retrieval: top K documents를 결정
- Generator: 각각 문서에서 output sequence probability 생성 후, 최종 sequence 결정 (marginalize)
\(P(y \vert x) = \sum_{z \in top-k(p(\cdot \vert x))} p_\eta (z \vert x) \prod_i^N 𝑃_\theta (𝑦_𝑖 |𝑥,𝑧,𝑦_(1:𝑖−1))\)
- RAG-Token Model
- 각 target token을 생성하는데, 다른 latent document를 사용
- Generator가 답을 생성할 때, 여러 문서를 참조할 수 있음
- Retrieval: top K documents를 결정
- Generator: 각각 document를 활용해 다음 토큰에 대한 distribution 생성 (최종 sequence 를 결정하기 전에)
\(P(y \vert x) = \prod_i^N \sum_{z \in top-k(p(\cdot \vert x))} p_\eta (z \vert x) 𝑃_\theta (𝑦_𝑖 |𝑥,𝑧,𝑦_(1:𝑖−1))\)
2.5 Retriever: DPR
- $𝑃_\eta (𝑧│𝑥)$ is based on Dense passage retrieval for ODQA
\(𝑃_\eta (𝑧│𝑥)∝exp(𝑑(𝑧)^𝑇 𝑞(𝑥))\)
\(𝑤ℎ𝑒𝑟𝑒 𝑑(𝑧)=𝐵𝐸𝑅𝑇_𝑑 (𝑧), 𝑞(𝑥)=𝐵𝐸𝑅𝑇_𝑞 (𝑥)\)
- 두 모델 모두 BERT-base 사용
- Maximum inner product search (MIPS)를 활용해 top-k 문서 검색
- 위에 식과 같이 document와 query 임베딩 벡터의 내적 값 활용
- Sub-linear time에 해결 가능한 problem
- TriviaQA & Natural Questions 데이터셋의 질문에 대한 답을 가진 retrieve documents로 학습됨
- Non-parametric memory – document index
2.6 Generator: BART
-
$𝑃_\theta (𝑦_𝑖 𝑥,𝑧,𝑦_{1:𝑖−1})$ is based on encoder-decoder architecture - Seq-to-seq구조를 가진 어떤 모델이라도 사용가능
- 논문에서는 BART-Large 사용 (400M parameters)
- Input x와 document z vector를 단순히 concat해서 generate 하는데 사용
- BART는 denoising objective와 여러 noising function을 활용해 pretraining
- 유사한 parameter 수의 T5에 비해, 여러 generation task에서 더 좋은 성능을 보임
- parametric memory – generator parameter 𝜃
2.7 Training
- Jointly train retriever + generator
- 어떤 문서를 retrieve 해야 하는지 제공하지 않음
- 주어진 pair $(𝑥_𝑖, 𝑦_𝑖)$ 에 대해 negative marginal log-likelihood를 최소화 하도록 학습 \(\sum_j -log p(y_j \vert x_j)\)
- Retriever는 𝐵𝐸𝑅𝑇_𝑞만 fine-tuning에 참여, 𝐵𝐸𝑅𝑇_𝑑는 freeze
- 훈련 중에, REALM 처럼 𝐵𝐸𝑅𝑇_𝑑도 업데이트 하는 것은 매우 비효율적
- Negative marginal log-likelihood
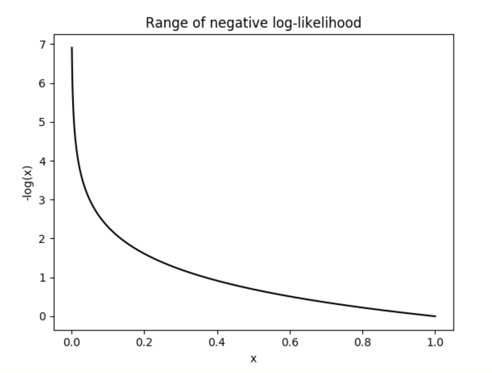
- 정답을 많이 맞추면 작은 값을 갖는 loss
- Optimizer: Adam
2.8 Decoding
- RAG-Token
\(𝑝_\theta (𝑦_𝑖 |𝑥,𝑧_𝑖,𝑦_(1:𝑖−1)) = \sum_{z \in top-k(p(\cdot \vert x))} p_\eta (z_i \vert x) p_\theta (𝑦_𝑖 |𝑥,𝑧_𝑖,𝑦_(1:𝑖−1))\)
- Transition probability
- the probability of moving from one state of a system into another state.
- $𝑦_(1:𝑖−1)$ 로 부터 $𝑦_𝑖$ 를 생성 하기 때문에?
-
Standard beam decode를 사용해서 $𝑃_\theta^′ (𝑦_𝑖 𝑥,𝑦_{1:𝑖−1} )$ 를 계산
- Transition probability
- RAG-Sequence
- Single beam search로 decoding 불가능
- 각 document z에 대해 beam search 적용
-
$𝑝_\theta (𝑦_𝑖 𝑥,𝑧_𝑖,𝑦_{1:𝑖−1} )$ 를 이용해 각 hypothesis scoring, hypothesizes set 𝑌 생성
- 각 y의 확률 추정을 위해, beam에 y가 나타나지 않은 모든 z 마다 추가적인 forward pass 실행 → “Thorough Decoding”
-
Beam search 결과, y가 생성되지 않은 𝑥, $𝑧_𝑖$ 에 대해 $𝑝_\theta (𝑦 𝑥,𝑧_𝑖 )$ 를 0에 가까운 값을 가지도록 설정해 추가적인 forward pass 회피 → “Fast Decoding”
- Single beam search로 decoding 불가능
2.9 Data and Experimets setting
- Data
- Non-parametric knowledge source: Wikipedia dump (December 2018)
- 각 article을 100-word chunks로 분할
- 총 21M documents 생성
- FAISS로 MIPS index 만들어 사용
- Top-k, (5 ≤𝑘 ≤ 10)
- Non-parametric knowledge source: Wikipedia dump (December 2018)
- Tasks
- Open-domain QA: Exact match score로 평가
- Abstractive QA: parametric knowledge 평가
- 다른 데이터 셋의 질문을 위키피디아만으로 답변 불가능
- Jeopardy Question Generation: RAG’s generation 능력 평가
- Fact Verification
- 주어진 문장을 3가지로 분류
- supports/refutes/not enough info
2.10 Open-domain QA & Abstractive QA
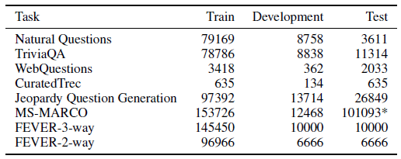
- 4개의 ODQA 데이터 셋에서 모두 RAG 가 새로운 SOTA 달성
- 특히 REALM/T5+SSM와 다르게 RAG는 salient span masking을 활용한 pre-training 같은 비용 높은 과정 없이 좋은 성능을 보임
- Re-ranker 나 extractive reader가 SOTA를 위해 필요한 것이 아님을 증명
- RAG는 gold passage들을 사용하지 않았음에도 불구하고, SOTA에 근접하는 성능을 보여 주었음
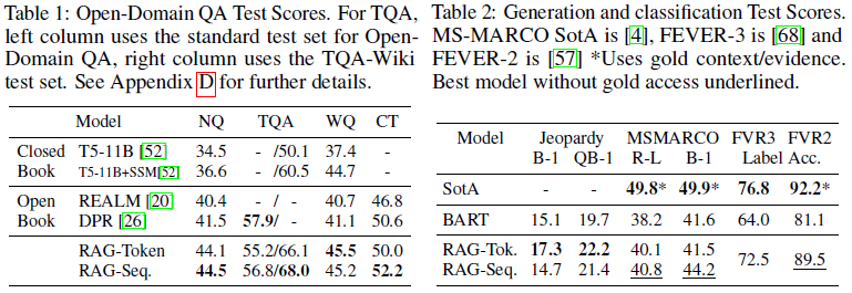
2.11 Jeopardy Question Generation
- RAG-Token 모델이 여러 문서로 부터 정답을 생성하기 때문에 가장 좋은 성능을 보임
-
“SUN” 을 생성할 때, document 2에서는 확률이 높음, 유사하게 document 1에서는 “A Farewell to Arms”가 생성 됬을 때의 확률이 가장 높음
-
첫 번째 token을 생성한후 확률이 flatten 되는 현상이 확인됨
-
- Generator가 특정 문서들에 의존하지 않고 문장을 완성할 수 있다고 suggests할 수 있음
- 즉, 모델의 parametric knowledge가 문장을 완성하기에 충분하다는 의미
- Bart에게 “The sun”을 입력으로 주었을 때
- “The Sun Also Rises” is a novel by this author of “The Sun Also Rises”
- “The Sun Also Rises” is a novel by this author of “A”는
- “The Sun Also Rises” is a novel by this author of “A Farewell to Arms”.

- “The Sun Also Rises” is a novel by this author of “A Farewell to Arms”.
2.12 Additional Results
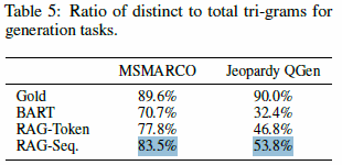
- Generation 성능
- RAG-Sequence > RAG-Token
- 두개다 BART보다는 뛰어남
- Index hot-swapping
- 2016년, 2018년 문서 기반의 index 준비
- 시기에 리더가 바뀐 사례를 82가지 준비
- 정확도=> 2016: 70%, 2018: 68%
- 2016년, 2018년 문서 기반의 index 준비
- Fixed-BM25
- FEVER가 entity centric이기 때문에, word overlap 방식의 BM25가 잘 맞았을 것
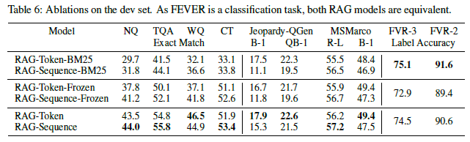
- FEVER가 entity centric이기 때문에, word overlap 방식의 BM25가 잘 맞았을 것
2.13 Discussion
- Hybrid generation model을 제안
- Non-parametric + parametric memory
- ODQA 분야에서 SOTA 달성
- Index hot-swap을 통해, 재 학습 없이 knowledge를 update 할 수 있음을 보임
- Future works
- 두 요소가 scratch 부터 pre-train 할 때 jointly 동작할 수 있다면 유익
- Denoising objective를 이용
- 다양한 NLP task들에 적용할 수 있도록, 두 요소를 어떻게 효과적으로 합치고, 상호작용하게 할지 새로운 방향성 탐구도 필요
- 두 요소가 scratch 부터 pre-train 할 때 jointly 동작할 수 있다면 유익