
1. 개인학습
1.1 Ensemble
- 여러 실험을 하다 모인 여러 모델들을 활용해 종합 결과 도출
- 현업에서는 serving을 해야하기 때문에 많이 사용하진 않음
- 대회에서는 성능을 높이기 위해 많이 사용
- Ensemble 기법
- Voting
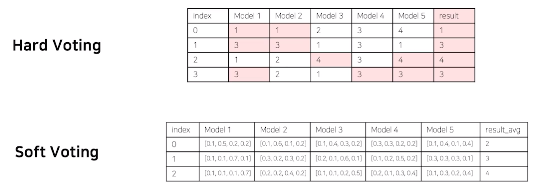
- Hard Voting
- 가장 많이 선택된 것을 최종결과로 결정
- Soft Voting
- 각 모델의 확률을 평균내어 최종결과로 결정
- Hard Voting
- Cross Validation
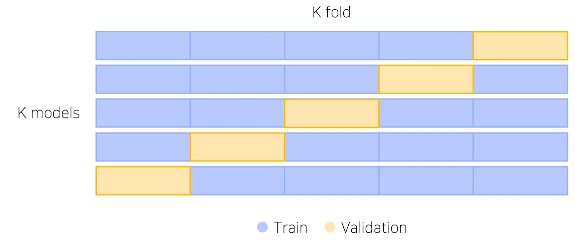
- 훈련 셋과 검증 셋을 분리는 하되, 검증 셋 까지 학습에 활용하기 위한 방안
- K fold: 일반적으로 5개 사용
- 정해진 것은 없음! 실험을 통해 적절히 선택 필요
- Stratified => class 분포와 동일하게 추출가능
- Test Time Augmentation(TTA)
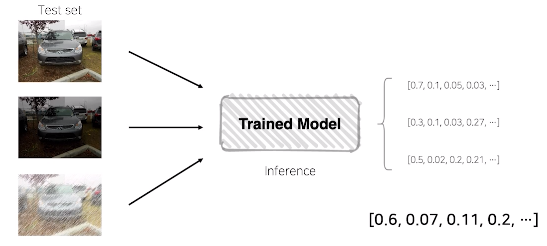
- Test에도 Noise를 섞어서 평가 -> 일반화 성능을 확인할 수 있음
- 동일한 이미지에 여러 Noise를 섞어 판단한 결과를 종합하여 최종결과로 결정
- 일종의 앙상블 효과로 볼 수 있음
- Trade-off
- 효과는 확실히 있지만, 그만큼 학습, 추론 시간이 배로 소모
1.2 Hyperparameter Optimization
- 효과는 확실히 있지만, 그만큼 학습, 추론 시간이 배로 소모
- 시스템의 매커니즘에 영향을 주는 주요한 파라미터
- 수 많은 조합… 모든 경우를 시도해보기는 불가능하다
- 시간과 효율이 떨어짐
- OPUNA
- 파라미터 범위를 주고, 범위 안에서 정해준 trials 만큼 시행
2. More tips
2.1 Experimet Toolkots
- Tensorboard
- loss, metric 변화 기록
- 샘플 이미지 출력
- 사용법
tensorboard --logdir PATH # log가 저장된 경로 --host ADDR # 원격 서버에서 사용시 0.0.0.0(default: locallhost) --port PORT # 포트번호 - loss, metric 변화 기록
- Weight & Bias
- 딥러닝 로그의 깃허브 같은 느낌
- 사용법
- wandb login (1회만)
- init, log 설정 후 값을 넣어주기만 하면 된다

2.2 Machine Learning Project
- Jupyter Notebook
- Cell 단위로 실행해볼 수 있는 것이 장점
- But, 창이 꺼지면 돌아 갈 수 없음
- Python IDLE
- 구현은 한번만
- 간편한 코드의 재사성
- 디버깅도 가능
2.3 Some Tips
- 분석 코드 보다는 설명글을 유심히!
- 언제든지 활용할 수 있을 정도로 코드를 구성요소 하나하나 디테일하게 이해
- Paper with Codes, 최신 논문과 코드 확인 가능
- 공유하기
2. 알고리즘 풀이
3. 경진대회 진행
-
Augmentation 후 [2770 2045 2490 3635 4090 3270 3324 2454 2282 4362 4908 2834 3324 2454 2292 4362 4908 2834] 어느정도 class imbalance를 해결한 데이터로 학습, 여기에 더해 학습 중 tranform을 적용하기 때문에 실질 적으로 더 다양한 이미지들을 학습한다고 볼 수 있다. StratfiedKfold를 사용했기 때문에 fold에 들어가 있는 데이터의 클래스 분포는 전체 데이터와 똑같다. 따라서 모든 클래스가 적당 수의 validation을 가지고 있다. 학습결과 validation f1_score가 0.998 까지 올라가, 로스변화, Confusion matrix를 그려보아 확인했을때, 편향되는 결과 없이 고르게 거의 다 맞추고 있었다. 하지만 제출을 하면 69% ~ 72% 사이에 머무른다. validation과 eval 이미지에 어떠한 차이가 있는 것이라고 생각된다. 그래서 Augmentation을 더 다양하게 진행해 일반화 성능 및 강건성을 높이려고 한다.
- Data Augmentation
- 학습 중 transform 적용 확률 증가(0.3 -> 0.5)
- Model
- Efficientnet (timm 라이브러리 활용) 현재 까지 가장 성능이 좋음
- lr: le-4, cosineanealing shceduler 사용
- 향후 계획
- 완벽하게 모듈화 하기
- 튜닝 포인트 찾기
- 데이터 Augmentation 보강 하기