
0. torch에서 제공하는 기본 클래스
- HDF5Matrix와 동일하게, 해당 데이터를 사용할 때 메모리에 적재, 메모리에러로 부터 자유로워질 수 있다
- 아래 함수들을 필수로 구현해 주어야한다
- init(self,…): 초기화 함수
- len(data): 데이터의 길이 반환
- getitem(idx): idx번째 데이터 반환
import pandas as pd
import torch
import torch.utils.data as D
import torch.utils.data.Dataset as Dataset
class CustomDataset(Dataset):
def __init__(self, x_root, y_root, chunksize):
def __len__(self):
def __getitem__(self, idx):
1. init 및 len
- 데이터셋이 파일로 구분된 경우
- 이미지나 오디오같이 여러개의 파일로 이루어 져있을 경우는 파일 목록을 가지고 있는다
- 목록과 index를 이용해 해당 데이터에 접근
- 데이터셋이 하나의 파일인 경우
- 많이 사용되는 csv 형태로 하나의 파일로 존재하는경우
- chunksize와 iterator를 이용해 원하는 크기만큼의 데이터만 호출한다
def __init__(self, x_root, y_root, chunksize):
# 데이터셋이 파일로 구분되어 있는 경우 (Audio, Image)
self.file_path = root
y = pd.read_csv(y_root)
self.y = y.values
# 데이터셋이 하나의 파일인 경우 (CSV)
self.chunksize = chunksize
self.reader = pd.read_csv(x_root, chunksize=self.chunksize, iterator=True)
def __len__(self):
return len(self.y) # 데이터셋이 파일로 구분되어 있는 경우
return self.chunksize # 데이터셋이 하나의 파일인 경우
2. getitem
- 데이터셋이 파일로 구분되어 있는 경우
- 간단하게 원하는 파일만 불러와서 반환해 주면 된다
- 데이터셋이 하나의 파일인 경우
- y라벨이 같은 파일에 있다면 인덱스로 제어해주면 된다
- 청크 사이즈 만큼 얻어온 데이터를 반환해 주면된다
# 데이터셋이 파일로 구분되어 있는 경우
def __getitem__(self, idx):
# 원하는 index의 데이터만 호출해서 반환
x = np.load(self.file_path[idx])
self.x_data = torch.from_numpy(x).float()
self.y_data = torch.from_numpy(self.y[idx]).float()
return self.x_data, self.y_data
# 데이터셋이 하나의 파일인 경우
def __getitem__(self):
# 정해진 크기만큼 데이터를 호출해 사용
data = self.reader.get_chunk(self.chunksize)
tensorData = torch.as_tensor(data.values, dtype=torch.float32)
input = tensorData[:,:-1]
self.y_data = torch.from_numpy(self.y).float()
return input, self.y_data
3. 확인해보기
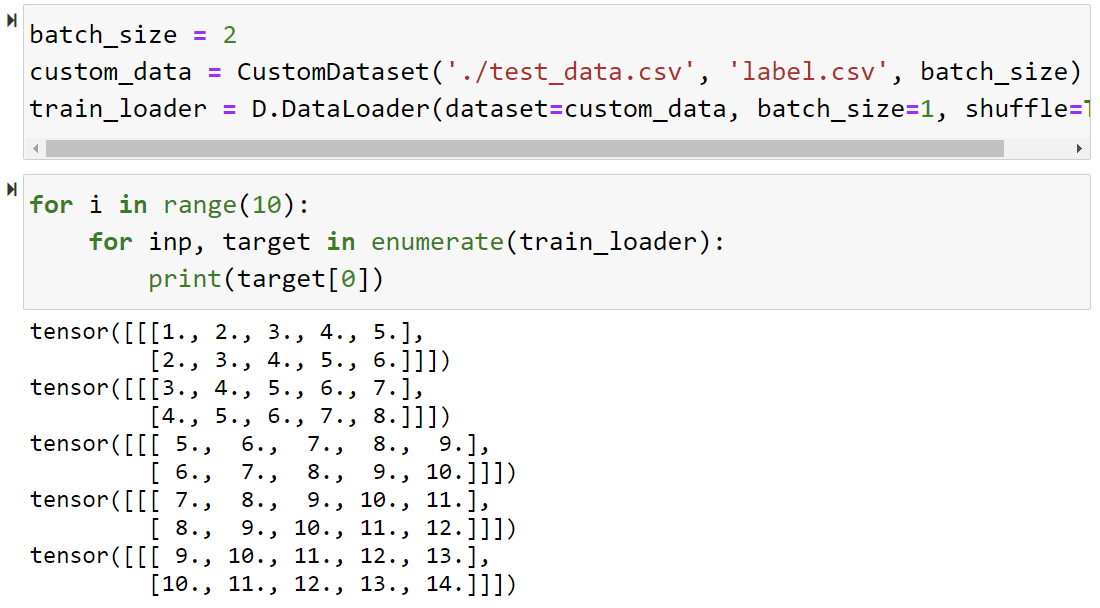
- 그림에서 보이는 것과 같이 2개씩 읽어 오는 것을 알 수 있다.
if __name__ == '__main__':
batch_size = 2
custom_data = CustomDataset('./test_data.csv', 'label.csv', batch_size)
train_loader = D.DataLoader(dataset=custom_data, batch_size=1, shuffle=True)
for i in range(10):
for idx, target in enumerate(tarin_loader):
print(target[0])
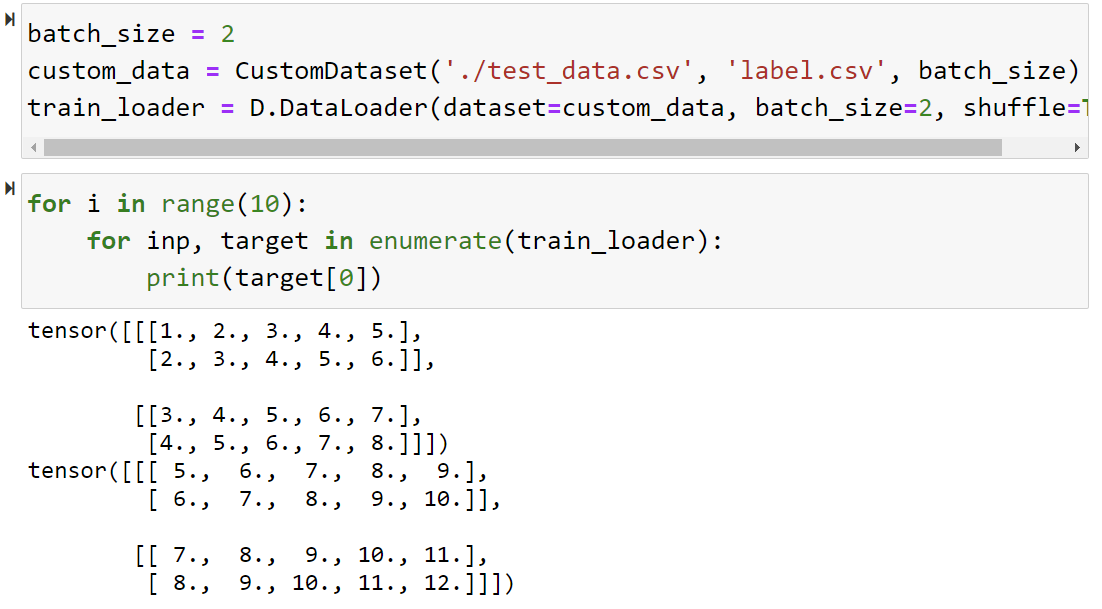
- 여기서 DataLoader의 배치 크기를 늘리면, 해당 묶음 만큼 가져온다
- 라벨 처리도 쉽게 하려면 동일한 방식으로 불러오도록 수정하면 좋을 것 같다