
1. Intro
1.1 딥러닝 모델은?
- Layer = Block
- 논문에 있는 모델 => 수많은 반복의 연속
- Block들을 조립한것
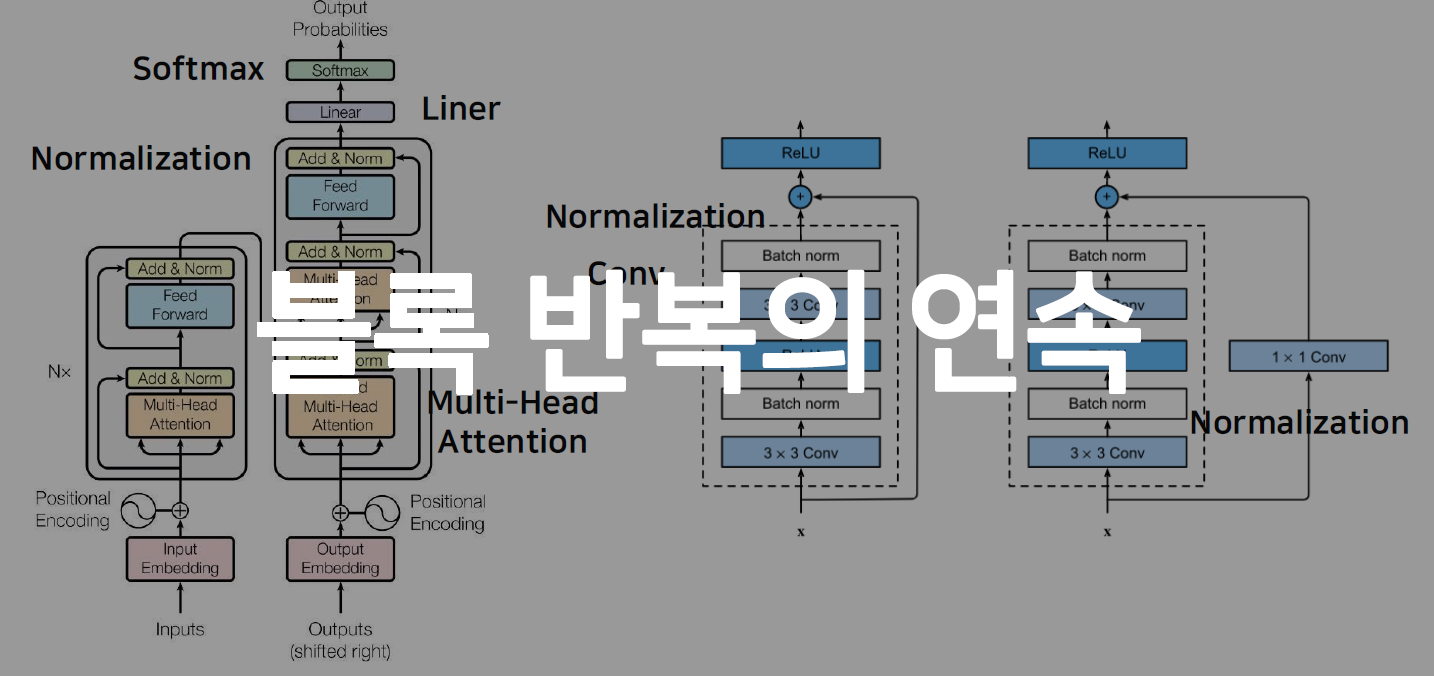
1.2 Base classes
- torch.nn.Module
- Layer의 base class
- Input, output, Forward, Backward(AutoGrad) 정의
- 학습 대상(parameter-tensor) 정의
- nn.Parameter
- Tensor 객체의 상속 객체
- nn.Module 내에 attribute가 되면 학습되상이 된다(required_grad=True)
- 대부분의 layer에는 이미 잘 지정되어있음(Dense, Conv, …)
1.3 Custom Layer 만들기
class CustomLayer(nn.Module):
def __init__(self, in_ft, out_ft, bias=True):
super().__init__() # 부모 __init__() 호출
self.in_ft = in_ft # 입력 피쳐 크기
self.out_ft = out_ft# 출력 피쳐 크기
# 파라미터 설정
# 평균이 0이고 표준편차가 1인 가우시안 정규분포를 이용해 난수 생성
self.W = nn.Parameter(torch.randn(in_ft, out_ft))
self.b = nn.Parameter(torch.randn(out_ft))
def forwrad(self, x):
return x @ self.W + self.b # 선형회귀 계산
# layer 선언!
Mylayer = CustomLayer(5, 10)
# 설정한 파라미터 확인 가능
# Layer 구현시 parameter를 단순 Tensor로 선언시 parameter로 반영되지 않는다
for v in Mylayer.parameters():
print(v)
1.4 Backward
- Parameter들을 미분
- Forward의 결과값과 실제값의 차이에 대해 미분, 이 값으로 parameter 업데이트
- Loss functions
# criterion => [Loss functions]
criterion = torch.nn.MSELoss()
# optimizer 정하기
# 기본 인자: 모델 파라미터와, learning rate
# optimizer에 따라 다양한 인자가 있음
optimizer = torch.optim.SGD(model.parameters(), lr=learning_rate)
for e in range(epochs):
# grad 초기화
# 이전 epoch의 grad값에 대한 정보가 남아있음.
# 영향을 주길 원하지 않으면 초기화 필수
optimizer.zero_grad()
# Forward 연산
outputs = model(inputs)
# 예측과 실제값 차이 계산
loss = criterion(outputs, labels)
# Parmeter로 설정한 변수들 미분값 계산
loss.backward()
# Parameter 업데이트
optimizer.step()
# Disabling gradient calculation is useful for inference
# The Variable API has been deprecated: Variables are no longer necessary to use autograd with tensors.
# autograd_tensor = torch.randn((2, 3, 4), requires_grad=True)
from torch.autograd import Variable
with torch.no_grad():
if torch.cuda.is_available():
# .cpu(): Cpu 메모리로 해당 object 복사
# .data Object 내용/값
# .numpy() numpy array로 변환해 반환
pred = model(Variable(torch.from_numpy(x_train).cuda())).cpu().data.numpy()
#pred = model(torch.from_numpy(x_train).cuda()).cpu().data.numpy()
else:
pred = model(Variable(torch.from_numpy(x_train))).data.numpy()
#pred = model(torch.from_numpy(x_train)).data.numpy()
'''
+a .detach()
gradient가 계산될 tensor의 경우 graph로 기록되어있다
node: Tensor
edge: 입력 Tensor로 부터 출력 Tensor 생성
.cpu().detach() 로 사용하면 cpu를 만드는 edge가 생성된다.
.detach().cpu() 로 사용하면 추가적으로 edge가 생성되지 않는다.
그래서 주로, .detach().cpu() 순으로 사용한다.
1.5 Logistic Regression 구현해보기
class LR(nn.Module):
def __init__(self, dim, lr=torch.scalar_tensor(0.01)):
super(LR, self).__init__()
# intialize parameters
# 직접 미분하기 때문에 parameter로 선언할 필요 없음
self.w = torch.zeros(dim, 1, dtype=torch.float).to(device)
self.b = torch.scalar_tensor(0).to(device)
self.grads = {"dw": torch.zeros(dim, 1, dtype=torch.float).to(device) ,"db": torch.scalar_tensor(0).to(device)}
self.lr = lr.to(device)
def forward(self, x):
...
return output
def sigmoid(self, z):
return 1/(1 + torch.exp(-z))
def backward(self, x, yhat, y):
## compute backward
self.grads["dw"] = (1/x.shape[1]) * torch.mm(x, (yhat - y).T)
self.grads["db"] = (1/x.shape[1]) * torch.sum(yhat - y)
def optimize(self):
## optimization step
self.w = self.w - self.lr * self.grads["dw"]
self.b = self.b - self.lr * self.grads["db"]