
1. Intro
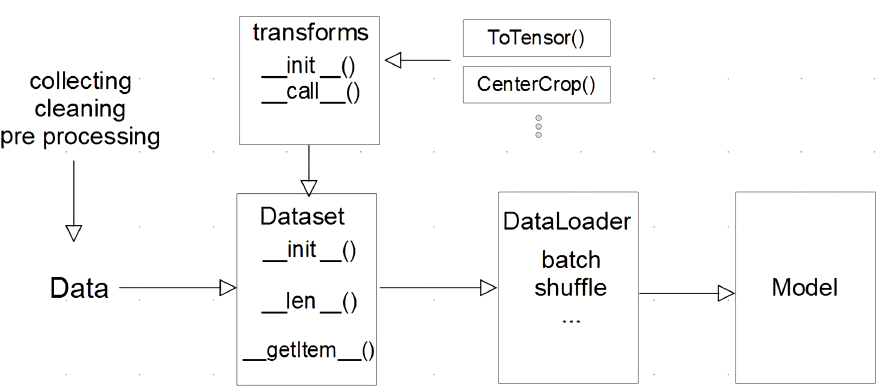
- 데이터 수집
- Dataset class
- init -> 어떤 데이터를 불러올것인지?
- len -> 길이가 얼마인지?
- getitem -> 하나의 데이터를 불러올때 어떻게 반환하는지?
- transforms: 전처리(이미지 변환 등)
- 데이터셋을 전처리 해주는 부분
- 텐서로 만들어주는 부분과 데이터 하나를 넘겨주는 부분이 다르다.
- DataLoader
- Data를 어떻게 처리할지 정의한대로 Data를 묶어서 Batch를 만들어줌
- Model에 feed
2. Classes
2.1 Dataset 클래스
- 데이터 입력 형태를 정의
- 데이터를 입력하는 방식의 표준화
- 유의사항
- 데이터 형태에 따라 각 함수를 다르게 정의
- 모든 것을 데이터 생성 시점에 처리할 필요가 없다
- Tensor변화는 학습에 필요한 시점에서!
- 데이터 셋에 대한 표준화된 처리방법 제공 필요
- HuggingFace등 표준화된 라이브러리 사용
- 허깅페이스는 트랜스포머 기반의 모델들과 학습 알고리즘을 구현해 놓은 라이브러리이다. 원래는 torch로 전부 구현해야 하지만, 허깅 페이스를 사용하면 간단하게 사용할 수 있다.
class CustomDataset(Dataset):
# 초기 데이터 생성방법을 지정
def __init__(self, text, labels):
self.labels = labels
self.data = text
# 데이터의 전체 길이
def __len__(self):
return len(self.labels)
# index를 주었을 때 반환되는 데이터의 형태
# index/data tpye 이름(?)을 사용할 수도 있다.
def __getitem__(self, idx):
label = self.labels[idx]
text = self.data[idx]
sample = {"Text": text, "Class": label}
return sample
2.2 DataLoader 클래스
- Data의 Batch를 생성해주는 클래스
- 학습 직전 변환 책임
- Tensor 변환 + Batch 처리가 메인
- 병렬적인 데이터 전처리 코드 고민 필요
- 파라미터
- sampler, batch_sampler: 데이터를 어떻게 뽑을지 인덱스를 정해주는 것
- collate_fn: variable정의, padding 등의 함수 정의
# Dataset 생성
text = ['Happy', 'Amazing', 'Sad', 'Unhapy', 'Glum']
labels = ['Positive', 'Positive', 'Negative', 'Negative', 'Negative']
MyDataset = CustomDataset(text, labels)
# Data 로딩
# batch size 만큼 묶어줌,
MyDataLoader = DataLoader(MyDataset, batch_size=2, shuffle=True)
next(iter(MyDataLoader)) # 다음 객체 호출
------
output
------
{'Class': ['Positive', 'Negative'], 'Text': ['Happy', 'Glum']}
3. NotMnist
3.1 라이브러리
from torchvision.datasets import VisionDataset # 다양한 데이터셋 제공
from tqdm import tqdm # 진행바
from skimage import io, transform # 이미지 입출력 및 변환
import matplotlib.pyplot as plt # plot
3.2 getitem
def __getitem__(self, index):
image_name = self.data[index] # index에 해당하는 image 경로반환
image = io.imread(image_name) # image read
label = self.targets[index] # index에 해당하는 label 값 반환
if self.transform: # 정의되어있으면, transform 적용
image = self.transform(image)
return image, label # 데이터와 라벨 반환
3.3 transform
- 이미지 전처리 예시
data_transform = transforms.Compose([
transforms.RandomSizedCrop(224), # 임의 구간 crop/데이터 크기 변환
transforms.RandomHorizontalFlip(), # 수평반전
transforms.ToTensor(), # 텐서로 변환
transforms.Normalize(mean=[0.485, 0.456, 0.406], # 정규화
std=[0.229, 0.224, 0.225])
])
3.4 DataLoader
# batch size = 128로 데이터 로딩
dataset_loader = torch.utils.data.DataLoader(dataset,
batch_size=128, shuffle=True)
# 데이터 형태
train_features, train_labels = next(iter(dataset_loader))
print(train_features.shape, len(train_labels))
------
output
------
torch.Size([128, 28, 28]) 128