1. Intro
- Transfer learning?
- 이미 학습된 모델을 가져와 내 데이터로 추가로 학습시키는 방법
- Back bone 모델 선택을 잘 해야 한다.
2. 모델을 저장 및 불러오는 방법
2.1 model.save
- 학습 결과를 저장
- 모델 구조와 parameter 저장
- 학습 중간 저장을해 최선의 결과 모델 유지
- 외부에 공유해 결과 재연 가능
# 모델의 Parameter save
# 확장자는 .pt를 많이 사용한다.
torch.save(model.state_dict(), "저장할 path" + "model.pt")
# 동일한 모델에서 Parameter만 load
new_model = ModelClass()
new_model.load_state_dict(torch.load("저장했던 경로"))
# 모델의 구조 + Parameter save
torch.save(model, "저장할 path" + "model.pt")
# 모델의 구조 + Parameter load
new_model = torch.load("저장했던 경로")
2.2 모델 정보 확인
from torchsummary import summary
summary(model, (3, 224, 224)) # input size
2.3 Checkpoints
- 학습의 중간 중간 결과 저장 $\rightarrow$ 최선의 결과 선택
- Earlystopping 활용 $\rightarrow$ 이전 학습의 결과물 저장
- loss와 metric 값을 지속적으로 확인하고 저장
- 일반적으로 epoch, loss, metric을 함께 확인
# 정보들을 한번에 저장
# 파일 이름은 저장 당시의 정보를 활용
# loss/len(dataloader) : 저장 당시 loss
# metric/len(dataloader) : 저장 당시 평가 결과
torch.save({
'epoch': e,
'model_satate_dict': model.state_dict(),
'optimizer_state_dict': optimizer.state_dict(),
'loss': loss,},
f'checkpoint_model_{e}_{loss/len(dataloader)}_{metric/len(dataloader)}.pt'
)
# 저장한 정보들 불러오기
check_point = torch.load("저장한 경로")
model.load_state_dict(checkpoint['model_satate_dict'])
optimizer.load_state_dict(checkpoint['optimizer_state_dict'])
epoch = checkpoint['epoch']
loss = checkpoint['loss']
3. Pretrained model / Transfer learning
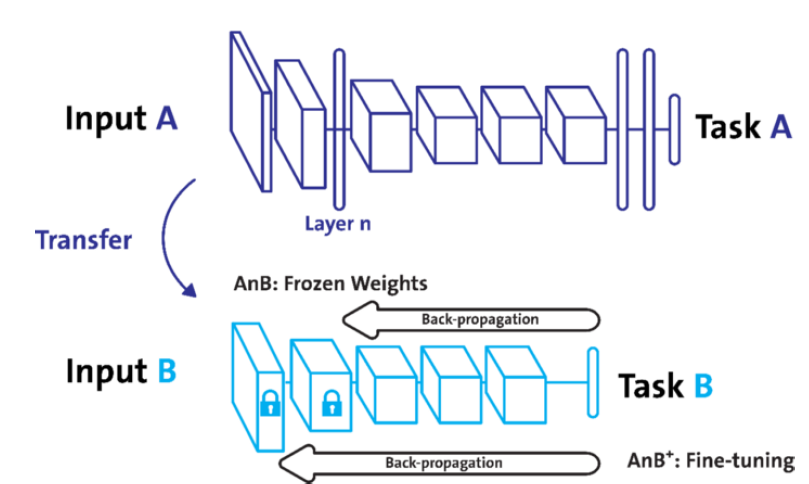
- Transfer learning
- 다른 데이터셋으로 만든 모델을 현재 데이터에 적용
- 일반적으로 대용량 데이터셋으로 만들어진 모델의 성능이 좋다
- 현재 가장 일반적인(?) 학습기법
- Backbone 구조가 잘 학습된 모델에서 일부만 변경해 학습 수행
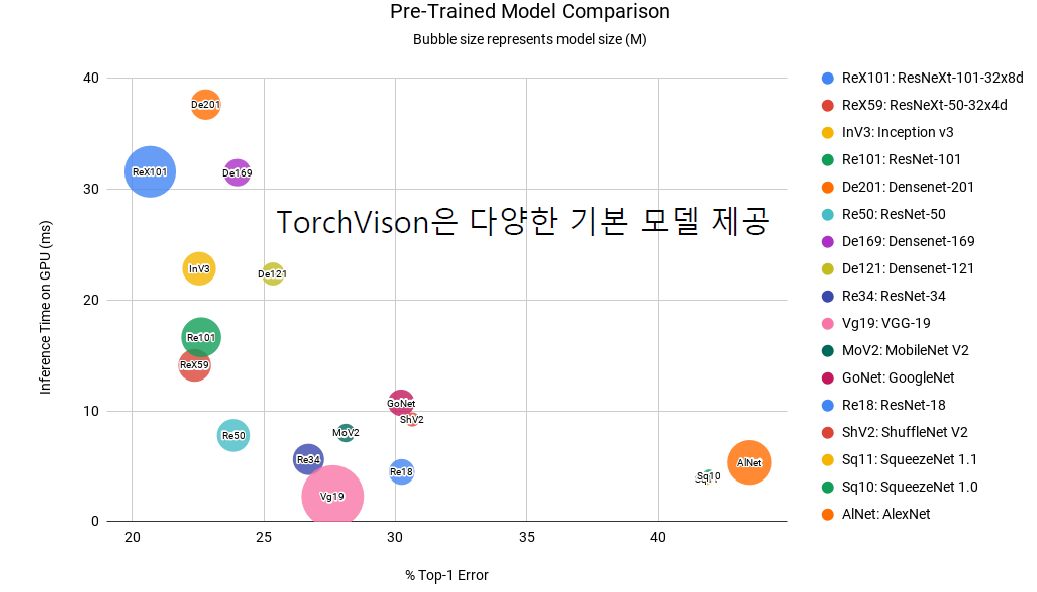
- TrochVision에서 다양한 기본 모델 제공
- How?
- 일부분의 parameter를 frozen 시킴 (parameter update가 일어나지 않도록)
class MyModel(nn.Moudle): def __init__(self): super().__init__() # 학습된 vgg19 모델 가져오기 self.pretrained_model = models.vgg19(pretrained=True) # 새로 추가하는 layer self.dense = nn.Linear(1000, 1) def forward(self, x): x = self.pretrained_model(x) x = self.dense(x) return x # 학습에서 제외할 Parameter Frozen 시키기 for p in mymodel.parameters(): # 전체 Parameter 학습 비활성화 p.requires_grad = False for p in mymodel.dense.parameters(): # 마지막 layer만 다시 활성화 p.requres_grad = True - 일부분의 parameter를 frozen 시킴 (parameter update가 일어나지 않도록)