
1. 개념 정리
- Single vs Multi : 1개 vs 2개 이상
- GPU vs Node : GPU vs 1대 컴퓨터의 1대 GPU
- Single Node Single GPU : 1대 컴퓨터의 1대 GPU
- Single Node Multi GPU : 1대 컴퓨터의 여러 GPU
- Multi Node Multi GPU : 여러 컴퓨터의 여러 GPU
2. 다중 GPU에 학습을 분산하는 방법
- 모델을 나누기 : alexnet 같이
- 모델의 병목, 파이프라인의 어려움이 있어 병렬화는 고난이도 과제
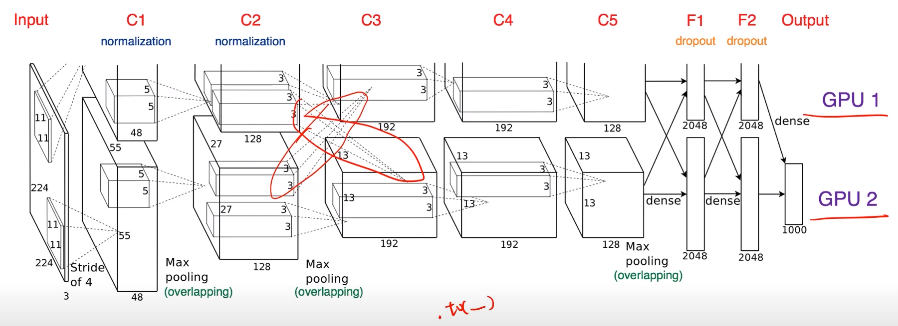
- 교차되는 지점: GPU간 병렬적인 계산을 위한 것
- 예시
class ParallelModel(ResNet): def __init__(): ... # cuda 0에 할당 self.layer1 = nn.Sequential(...).to('cuda:0') # cuda 1에 할당 self.layer2 = nn.Sequential(...).to('cuda:1') self.fc.to('cuda:1') def forward(self, x): x = self.seq2(self.seq1(x).to('cuda:1')) return self.fc(x.view(x.size(0),-1)) - 모델의 병목, 파이프라인의 어려움이 있어 병렬화는 고난이도 과제
- 데이터를 나누기
- 데이터를 나눠 GPU 할당후 결과의 평균을 취하는 것
- minibatch 수식과 유사, 한번에 여러 GPU에서 수행
- DataParallel
- 단순 분배후 평균
- GPU 사용 불균형 문제, Batch 사이즈 감소, GIL
- 예시
p_model = torch.nn.DataParallel(model) # 이게 전부 pred = p_model(input) # Forward 연산 loss = Loss(pred, real) # 로스계산 loss.mean().backward() # GPU 로의의 평균 + backward 계산 optimizer.step() # parameter 업데이트 - DistributedDataParallel
- 각 CPU마다 process 생성, 개별 GPU 할당
- 기본적으로 DataParallel로 하지만, 개별적으로 연산의 평균을 냄
- 예시
sampler = torch.utils.data.distributed.DistributedSampler(data) shuffle = False pin_memory = True # 메모리에 바로바로 올릴 수 있도록 처리해주는 것 trainloader = torch.utils.data.DataLoader(data, batch_size, shuffle=False, pin_memory, num_workers=3, shuffle=shuffle, sampler=sampler)