1. 환경 셋팅
- torch == 1.10.0
- transformers == 4.11
2. 모델 선정
- Roberta-samll
- Loss: NLL loss
- DPR 논문에서 로스를 비교한 결과 NLL loss가 조금 더 성능이 좋았음.
- in-batch negative sampling 사용
3. 코드
3.1 데이터 셋 준비
- KLUE 데이터 korqud 등, MRC 용 데이터를 사용하면 된다.
dataset = load_from_disk('../data/train_dataset/')
3.2 Tokenizer 준비
- 여기서는 roberta 기준으로 진행하지만,
- Bert, Bigbird(sparse attention) 등등 사용이 가능하다.
model_name = 'klue/roberta-small'
# Tokenizer 불러오기
q_tokenizer = AutoTokenizer.from_pretrained(model_name)
p_tokenizer = AutoTokenizer.from_pretrained(model_name)
# Tokenizing 하기
q_seqs = q_tokenizer(training_dataset['question'], padding="max_length", truncation=True, return_tensors='pt')
p_seqs = p_tokenizer(training_dataset['context'], padding="max_length", truncation=True, return_tensors='pt')
# TensorDataset에 넣어주기
train_dataset = TensorDataset(p_seqs['input_ids'], p_seqs['attention_mask'], p_seqs['token_type_ids'],
q_seqs['input_ids'], q_seqs['attention_mask'], q_seqs['token_type_ids'])
3.3 모델 선언
- 마지막 레이어의 [CLS] token의 hidden state (임베딩 벡터)를 활용할 것이기 때문에, 다른 down-stream task가 적용되어있는 class가 아니라 기본적인 RobertaModel class에 pretrained 모델을 로딩해 줍니다.
p_encoder = RobertaModel.from_pretrained(model_name)
q_encoder = RobertaModel.from_pretrained(model_name)
3.4 훈련 pipeline 설계
- p_encoder, q_encoder 훈련을 위한 함수를 정의합니다. 자세한 내용은 주석으로!
# Dataloader
train_sampler = RandomSampler(dataset) # 랜덤으로 추출 하도록 설정해주기
train_dataloader = DataLoader(dataset, sampler=train_sampler, batch_size=args.per_device_train_batch_size)
# Optimizer 선언 및 학습할 parameter 선택
no_decay = ['bias', 'LayerNorm.weight']
optimizer_grouped_parameters = [
{'params': [p for n, p in p_model.named_parameters() if not any(nd in n for nd in no_decay)], 'weight_decay': args.weight_decay},
{'params': [p for n, p in p_model.named_parameters() if any(nd in n for nd in no_decay)], 'weight_decay': 0.0},
{'params': [p for n, p in q_model.named_parameters() if not any(nd in n for nd in no_decay)], 'weight_decay': args.weight_decay},
{'params': [p for n, p in q_model.named_parameters() if any(nd in n for nd in no_decay)], 'weight_decay': 0.0}
]
optimizer = AdamW(optimizer_grouped_parameters, lr=args.learning_rate, eps=args.adam_epsilon)
# 총학습 길이를 계산해서 scheduler에 넣어주기
t_total = len(train_dataloader) // args.gradient_accumulation_steps * args.num_train_epochs
scheduler = get_linear_schedule_with_warmup(optimizer, num_warmup_steps=args.warmup_steps, num_training_steps=t_total)
# 학습 초기, 초기화
# optimizer.zero_grad() -> 설정해준 파라미터만 초기화
# model.zero_grad() -> 모델의 전체 파라미터를 초기화
p_model.zero_grad()
q_model.zero_grad()
torch.cuda.empty_cache()
train_iterator = trange(int(args.num_train_epochs), desc="Epoch")
batch_loss = 0
# 학습 루프 시작!
for _ in train_iterator:
print(_)
epoch_iterator = tqdm(train_dataloader, desc="Iteration")
# batch 단위로 꺼내오기
for step, batch in enumerate(epoch_iterator):
q_encoder.train()
p_encoder.train()
if torch.cuda.is_available():
batch = tuple(t.cuda() for t in batch)
p_inputs = {'input_ids': batch[0],
'attention_mask': batch[1],
'token_type_ids': batch[2]
}
q_inputs = {'input_ids': batch[3],
'attention_mask': batch[4],
'token_type_ids': batch[5]}
p_outputs = p_model(**p_inputs).pooler_output # pooler_output이 [CLS] 토큰의 임베딩 벡터
q_outputs = q_model(**q_inputs).pooler_output
# 유사도 구하기 (batch_size * embedding_dims) * (embedding_dims, batch_size)
sim_scores = torch.matmul(q_outputs, torch.transpose(p_outputs, 0, 1))
targets = torch.arange(0, args.per_device_train_batch_size).long()
if torch.cuda.is_available():
targets = targets.to('cuda')
# log softmax를 취하고 nll_loss를 계산
sim_scores = F.log_softmax(sim_scores, dim=1)
loss = F.nll_loss(sim_scores, targets)
loss.backward()
optimizer.step()
scheduler.step()
q_model.zero_grad()
p_model.zero_grad()
batch_loss += loss.detach().cpu().numpy()
torch.cuda.empty_cache()
3.5 검증 코드 추가하기
- 각각 쿼리에 대해 top-passage를 구해, index 기준으로 평가
- index = 1이 정답 passage라면
- top-1: rank[0]가 1이어야 함!
- top-3: rank[0:3]에 1이 있으면 됨
- index = 1이 정답 passage라면
with torch.no_grad():
p_encoder.eval()
# 문서(passage의 임베딩 벡터를 구하기)
p_embs = []
for p in valid_corpus:
p = p_tokenizer(p, padding="max_length", truncation=True, return_tensors='pt').to('cuda')
p_emb = p_encoder(**p).pooler_output.to('cpu').numpy()
p_embs.append(p_emb)
p_embs = torch.Tensor(p_embs).squeeze() # (num_passage, emb_dim)
# top ~ acc 구하기
top_1 = 0
top_3 = 0
top_10 = 0
top_25 = 0
top_35 = 0
top_100 = 0
q_encoder.eval()
for sample_idx in tqdm(range(len(valid_dataset['question']))):
query = valid_dataset[sample_idx]['question'] # 쿼리를 꺼내서
# 토크나이저를 이용해 토크나이징 하고
q_seqs_val = q_tokenizer([query], padding="max_length", truncation=True, return_tensors='pt').to('cuda')
# q_encoder를 이용해 임베딩 벡터를 구한다.
q_emb = q_encoder(**q_seqs_val).pooler_output.to('cpu') #(num_query, emb_dim)
# 아까 구했던 passage 임베딩 벡터와 matmul을 해서 score를 구한다.
dot_prod_scores = torch.matmul(q_emb, torch.transpose(p_embs, 0, 1))
# 점수 순으로 정렬
rank = torch.argsort(dot_prod_scores, dim=1, descending=True).squeeze()
if sample_idx == rank[0]:
top_1 += 1
if sample_idx in rank[0:3]:
top_3 += 1
if sample_idx in rank[0:10]:
top_10 += 1
if sample_idx in rank[0:25]:
top_25 += 1
if sample_idx in rank[0:35]:
top_35 += 1
if sample_idx in rank[0:100]:
top_100 += 1
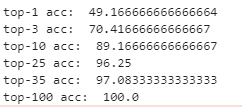
print('top-1 acc: ', top_1/240 * 100)
print('top-3 acc: ', top_3/240 * 100)
print('top-10 acc: ', top_10/240 * 100)
print('top-25 acc: ', top_25/240 * 100)
print('top-35 acc: ', top_35/240 * 100)
print('top-100 acc: ', top_100/240 * 100)
3.6 결과보기
- 당연할 수 도 있지만, top을 높일 수 록 잘 되는 것을 확인 할 수 있다.