데이터 제작의 A to Z
0. 강의 소개
- 데이터 구축 프로세스와 설계의 기초 개념에 대해 설명합니다.
- 데이터 구축이 전체 인공지능 서비스 개발에서 차지하는 역할에 대해 알아봅니다.
- 데이터 유형, 데이터 입출력 형식, 데이터 구분 방식에 대해 배웁니다.
- 자연어처리 데이터의 특징 및 종류에 대해 설명합니다.
1. 인공지능 서비스 개발 과정과 데이터
1.1 개발 과정
- 문제(서비스 기획)을 정의하고, 이와 관련된 데이를 수집 정제를 한다. 이 과정에서 발생한 데이터들을 학습과 검증, 개발에 사용하며 이 프로세스를 반복한다.
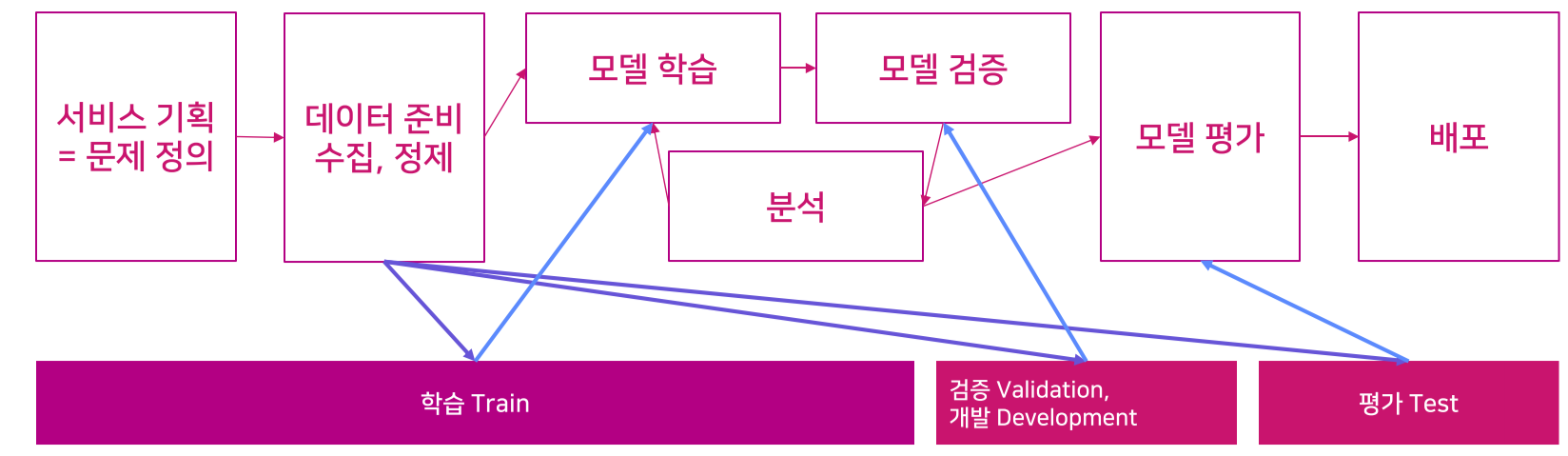
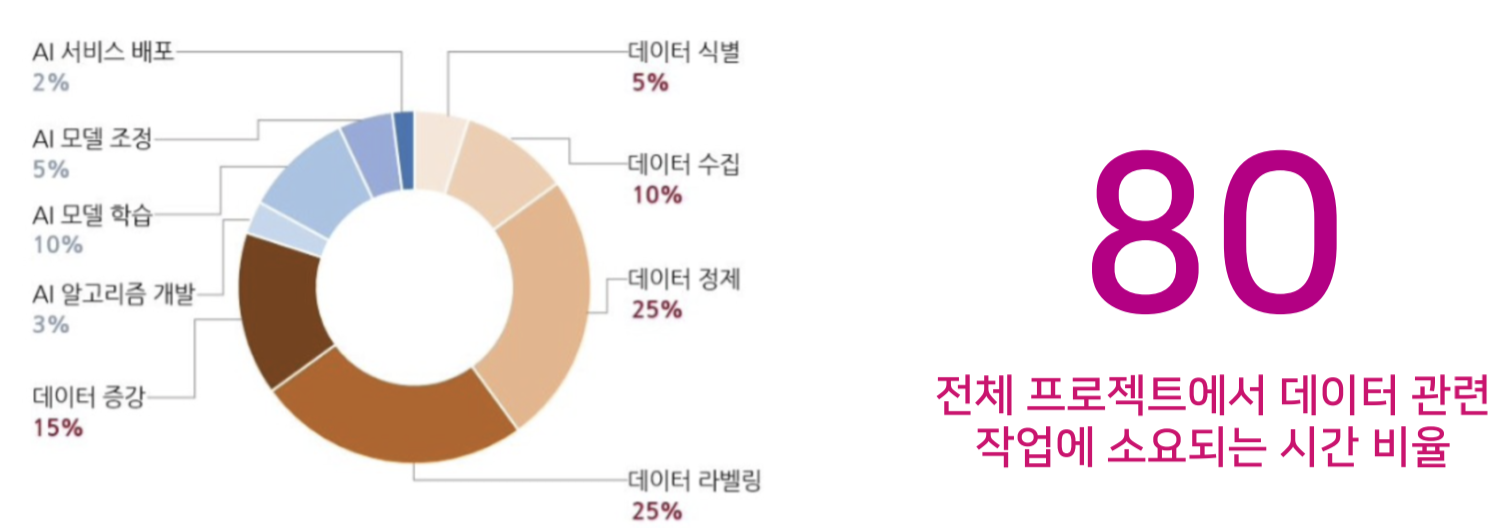
- AI 프로젝트에 소요되는 시간 비율
- 실제적으로 모델을 개발하는 시간보다 데이터를 개발하는 시간이 더 많이 차지한다.
1.2 데이터 구축 과정
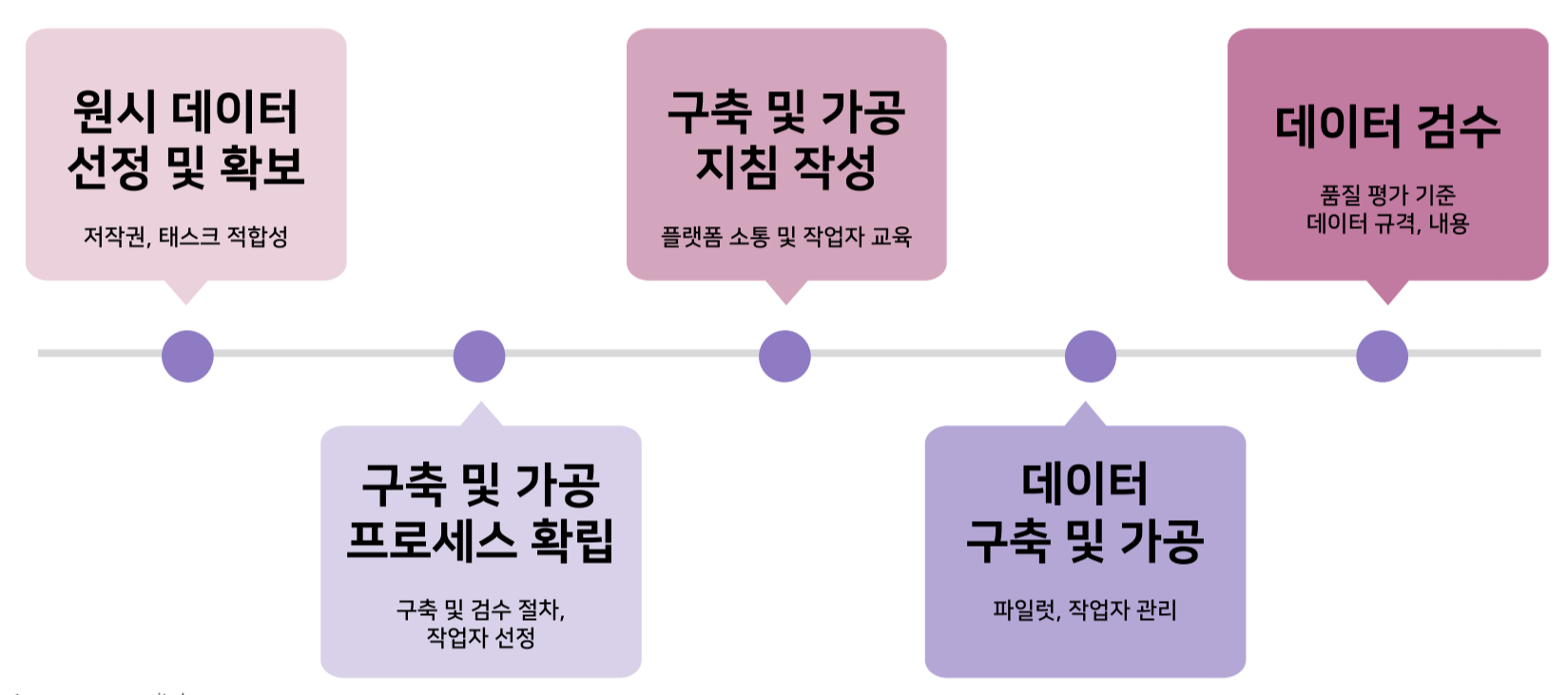
- 원시 데이터 선정 및 확보
- 저작권이 미치는 범위, 어떤 라이센스를 가지고 있는지?
- 내가 풀고자 하는 Task에 얼마나 부합하는가?
- 먼저 기존 데이터들이 어떻게 만들어지고, 어떤 부분을 신경 썻는지 확인하고 습득하자!
- 구축 및 가공 프로세스 확립
- 누구에게 얼마나 맡겨 제작을 할지? 작업자 선정 등
- 어떻게 배포할지?
- 구축 및 가공 지침 작성
- 어떤 플랫폼을 기반으로 제작을 할 것인지?
- 작업자에게 플랫폼 활용법을 교육
- 데이터 구축 및 가공
- 실제 데이터 제작
- 문제가 있으면 앞단계로 돌아가 계획 수정
- 데이터 검수
- 품질 평가 기준에 따라 데이터 검수
- 데이터의 품질을 정하는 단계
1.3 AI 데이터 설계의 구성 요소
- 데이터 설계
- 데이터 수집-가공 설계
- 원천 데이터 수집 방식: 전산화, 스크래핑, 작업자 선정, 모델 생성
- 주석 작업: 전문가 구축, 크라우드 소싱
2. 데이터 설계
2.1 데이터의 유형
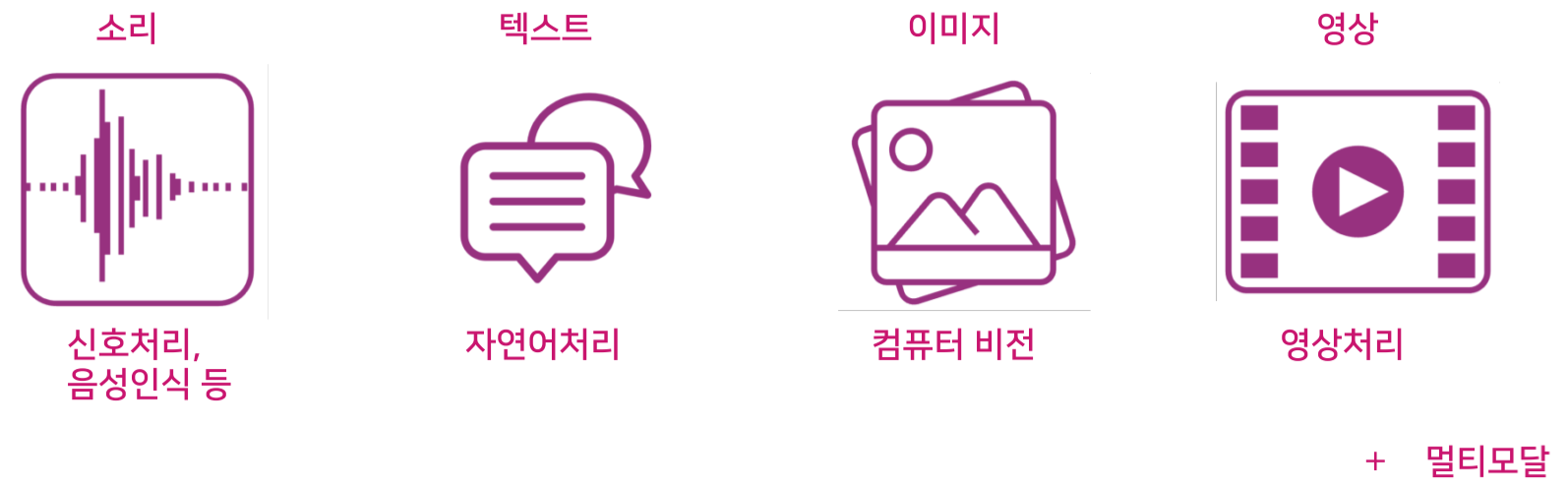
2.2 데이터의 IN/OUT 형식
- HTML, XML, CSV, TSV, TXT, JSON, JSONL, JPG, …
- 설계 당시 어떤 형식을 사용하는 것이 효율적인지 고민하고 정하는 과정이 필요
2.3 데이터(train/dev/test)별 규모와 구분 방식
- 규모 선정에 필요한 정보: 확보 가능한 원시데이어의 규모, 주석 작업 시간
- 구분 방식: 데이터별 비율과 기준 정하기
- 랜덤 VS 특정 조건
- E.g. 레이블 별로 분포가 일정하지 않을 수 있음. 적은 분포의 데이터를 어떤 비율로 반영할 지 잘 설계해야함
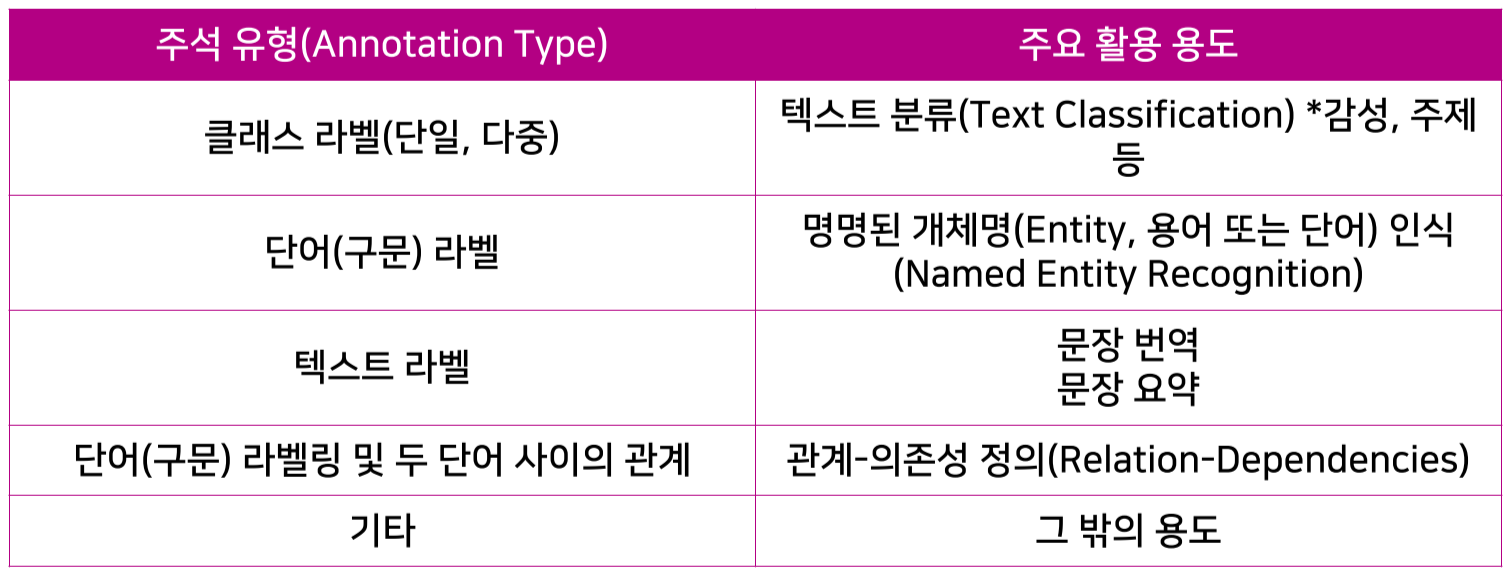
2.4 데이터의 주석 유형
3. 데이터 수집-가공 설계
3.1 원시 데이터 선정
3.2 작업자 선정
- 주석 작업의 난이도와 구축 규모에 맞는 작업자 선정 및 작업 관리
- 전문가: 난이도가 좀 높은 것
- 크라우드 소싱: 간단하고 직관적인 간단한 것
3.3 구축 및 검수 방법 설계 및 가이드라인 작성
- 파일럿으로 구축을 한번 해보고, 본 구축을 시도
- 보통 최소량이 만개
- 약 10%로 파일럿으로 작업해보는 것을 추천
- 파일럿
- 설계시 발견하지 못했던 이슈 발굴, 해결
- 가이드라인 보완 및 개정
- 작업자 선정
- 본구축
- 작업 일정 관리
- 작업자 관리
- 중간 검수를 통한 데이터 품질 관리
- 구축 작업의 난이도와 구축 규모, 태스크 특성에 맞는 구축 및 검수 방식(전문가, IAA) 설계
- 전문가 평가 및 분석
- 자동 평가 및 분석
- 데이터 형식
- 레이블별 분포 파악
- 일괄 수정 사항 반영
4. 자연어 처리 데이터
4.1 자연어란?

- 인공어: 원래 없는 언어인데 사람들이 인위적으로 만든 언어
- 자연어 처리란?
- 인공지능의 한분야로, 사람의 언어를 컴퓨터가 알아 들을 수 있도록 처리해주는 인터페이스
- 최종 목표: 컴퓨터가 사람의 언어를 이해하고 여러가지 문제를 수행할 수 있는 것
4.2 자연어처리와 관련 연구 분야
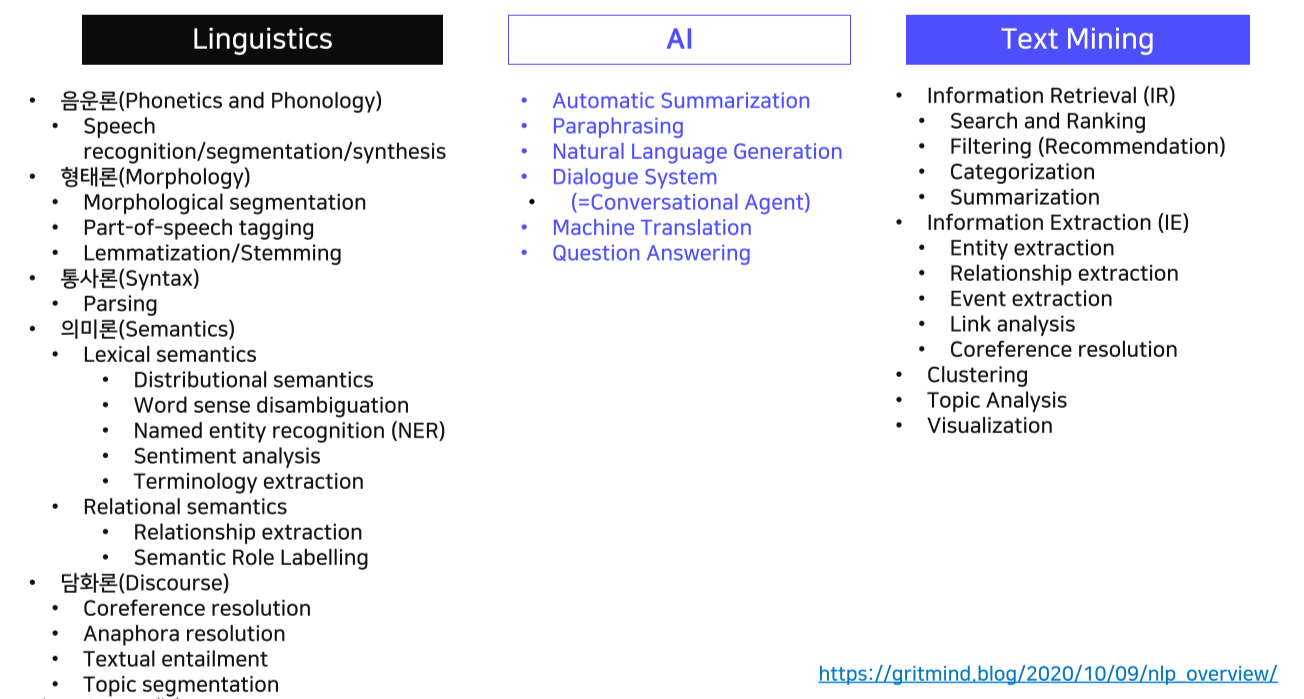
- Computer Science
- Linguistics
5. Further Questions
- 자연어 데이터와 다른 데이터를 구분짓는 특징은 무엇일까요?
- Sequence 형태를 가진다.
- 동일한 단어가 어떤 위치에 나오냐에 따라 의미가 달라질 수 있다.
- 유사하게, 동일한 단어이지만 다른 뜻을 가질 수 있다. (다의어, 발음으로 구분)
- 한국어 데이터의 제작 단계에서 어려운 점은 무엇이 있을까요?
- 문법에 맞지 않는 데이터를 어떻게 처리할지
- 계속해서 새롭게 발생하는 신조어, 등을 꾸준히 업데이트 하는 방법
Reference
- AI boot camp 2기 데이터 제작 강의
