자연어처리 데이터 기초
0. 강의 소개
- 데이터 제작 전반에 걸친 기초 개념을 정의합니다.
- 주석 관련 용어, 텍스트 데이터의 단위 등을 정의합니다.
- 자연어처리 데이터의 형식에 대해 배웁니다.
1. 인공지능 모델 개발을 위한 데이터
1.1 데이터의 종류

- 실제 텍스트 기반의 데이터 - 말뭉치류
- 텍스트 분석시 참조로 사용되는 자원 - 사전/데이터베이스 류
- 인공지능을 위한 데이터는 보통 말뭉치류! 라고 볼 수 있다.
1.2 인공지능 기술의 발전
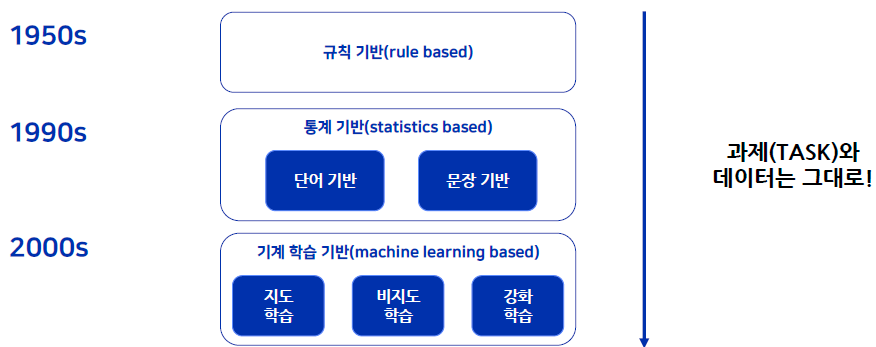
- Task와 데이터는 그대로, 인공지능 기술들이 발달
- 현재는 기계 학습 기반 방법이 주를 이룬다.
1.3 언어 모델 평가를 위한 종합적인 벤치마크 등장
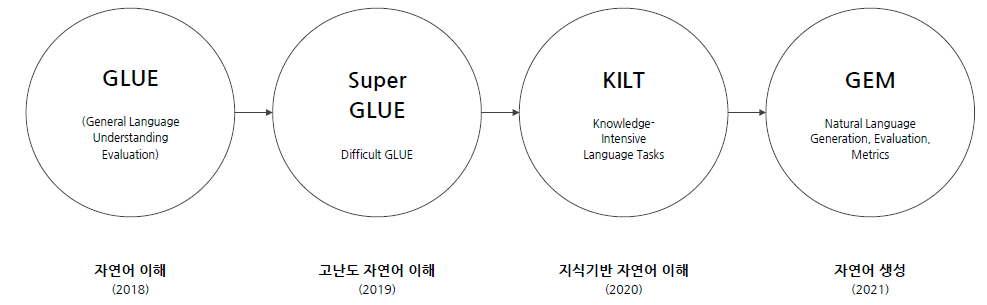
- 여러개의 Task를 묶어, 언어 모델이 얼마나 자연어를 잘 이해하는지 평가
- 기존에 존재하던 데이터들을 정제해 공유한 것
- 벤치 마크 구성
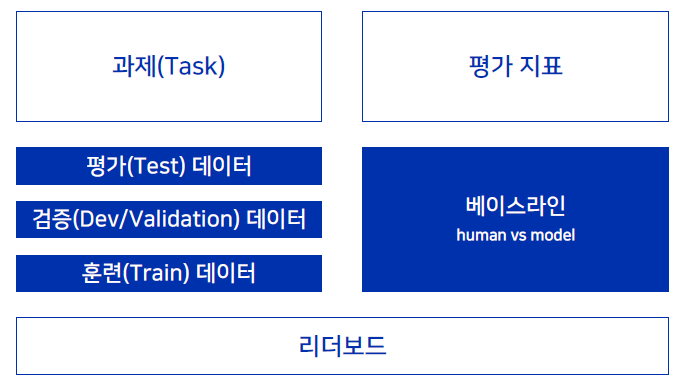
- 리더보드에서 자신의 모델의 성능을 확인 할 수 있음
2. 데이터 관련 용어 정리
2.1 기본용어
- 텍스트 (text)
- 주석, 번역, 서문 및 부록 따위에 대한 본문이나 원문.
- 언어 문장보다 더 큰 문법 단위. 문장이 모여서 이루어진 한 덩어리의 글
- 말뭉치 (corpus, plural corpora)
- 어떤 기준으로든 한 덩어리로 볼 수 있는 말의 뭉치(한 저작자의 저작 전부, 특정 분야 저작 전체)
- E.g. 김소월의 시 말뭉치 -> 김소월의 시 전체
- text acrchive vs 말뭉치 corpus(selected, structed, designed)
- text acrchive: 텍스트를 모아 놓은것 - 기준이나 조건이 없음
- 말뭉치 corpus: 기준이나 조건에 따라 선별해 모아 놓은 것
- 데이터
- 컴퓨터가 처리할 수 있는 문자, 숫자, 소리, 그림 따위의 형태로 된 정보
- 주석
- tag, label, annotation
- E.g 감성 분석을 했을 때, positive / negative로 구분이 된다면 이것이 주석(label)
- 형태소 분석기 vs 형태소 주석기
- 형태소에 종류를 다는 것
- 한국어에서는 형태소 분석기라고 한다.
2.2 언어학의 연구 분야
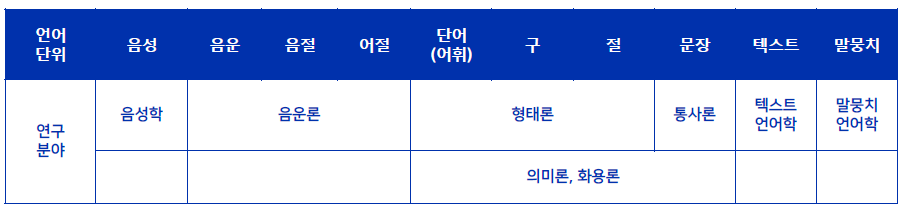
- 통사론, 텍스트 언어학, 말뭉치 언어학 -> 데이터 제작에 필요
- 텍스트 데이터의 기본 단위
- 영어: 단어/문장 또는 발화
- 한국어: 어절/문장 또는 발화
- 한국어 -> 9품사 (명사, 수사, 대명사, 동사, 형용사, 관형사, 부사, 조사, 감탄사)
- 조사는 명사, 수사, 대명사와 붙어 사용되 띄어쓰기 단위가 아니다.
- 어미는 하나의 품사로 인정되지 않고, 형태 단위로 독립된 단어가 아님
- 품사
- 단어를 문법적 성질의 공통성에 따라 몇 갈래로 묶어 놓은 것
- 품사 분류의 기준: 의미, 기능, 형식
- 타입(type) & 토큰(token)
- 토큰화: 표제어 추출(lemmatization), 품사 주석 POS(part of speech) tagging
- 토큰: 언어를 다루는 가장 작은 기본 단위
- 타입: 토큰의 대표 형태
- E.g “이 사람은 내가 알던 사람이 아니다”
- 토큰화: 이 / 사람 / 은 / 내 / 가 / 알 / 더 / ㄴ / 사람 / 이 / 아니 / 다
- 표제어 추출: 이, 사람, 나, 알다, 아니다
- 품사 주석
- 이/MM, 사람/NNG+은/JX, 나/NP+가/JKS, 알/VV+더/EP+ㄴ/ETM, 사람/NNG+이/JKS, 아니/VA+다/EF
- 토큰 수: 12개, 타입 수: 10개
- N-gram
- 연속된 N개의 단위. 입력된 단위는 글자, 형태소, 단어, 어절 등으로 사용자가 지정
- E.g. uni-gram, bi-gram, …
- 표상 (representation)
- 대표로 삼을 만큼 상징적인 것
- 자연어처리 분야에서 표현으로 번역하기도 하나, 자연어를 컴퓨터가 이해할 수 있는 기법을 표현한다는 차원에서 표상이 더 적합
- 사전학습 모델, word2vec 등등
3. 자연어처리 데이터 형식
- HTML (Hypertext Markup Language)
- XML (EXtensible Markup Language)
- JSON/JSONL (JavaScript Object Notation/Lines)
- CSV, TSV (comma/tab-separated values) - dlimiter 차이
- ,는 text 내에서 사용할 수 있기 때문에 오류 방지를 위해 TSV를 사용하는 것이 좋다
4. 공개 데이터
- 경진 대회 공개 데이터
- 국가 주도 공공 데이터
- 오픈소스 + benchmark
5. Further Questions
- 국내외 자연어 벤치마크에 포함된 과제(task)와 각각의 데이터는 어떻게 구성되어 있을까요?
- 한국어와 영어 데이터의 토큰화 및 표제어 추출에서 다른 특징은 무엇이 있나요?
Reference
- AI boot camp 2기 데이터 제작 강의
