NLP 모델 경량화 (1)
0. 강의 소개
- NLP분야에서도 경량화 기법들이 하루가 다르게 발전하고 있습니다.
- 모델 경량화 기법 NLP part에서는 Transformer 구조를 메인으로 사용하는 BERT 모델을 중심으로 경량화 기법을 다룹니다.
- Part 1인 본 강의에서는 Structured/Unstructred Pruning과 Weight Factorization, Weight Sharing을 다룹니다.
- 각 기법을 적용하는데 있어, 장 단점과 어떤 상황에 사용해야 할지에 주목해주시면 좋겠습니다!
1. Over view
1.1 경량화?
- 어떤 경량화를 적용해야 할까?
- 주어진 환경에 따라적용할 수 있는 방향이 달라 질 수 있다.
- Deploy 환경(CPU? GPU?)
- 주된 문제 상황(Latency, Mobile device)
- 경량화 요구 정도(drop을 감수한 경량화)
- HW 리소스(From scratch로 재학습이 가능한가?)
- 논문은 각자의 novelty를 위해, 다른 기법과의 조합을 잘 언급하지는 않는 경향을 가짐
- 상황에 맞게 어떤 경량화 기법을 써야할지 고민이 필요
- NLP vs CV
- Large model -> small model 방식의 KD와 좋은 궁합
- 모델 구조가 거의 유사, 논문 재현의 가능성, 코드 재사용성이 높음
1.2 주요 경량화 기법
- 효율적인 Architecture
- Pruning(Structured)
- Knowledge distillation(Response based, Feature based, …)
- weight factorization(Tucker Decomp, …)
- quantization
1.3 BERT Profiling
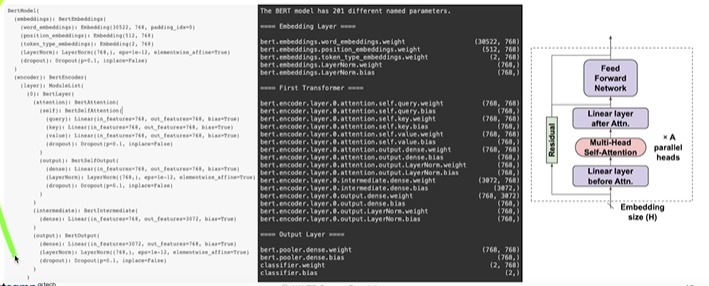
- Profiling
- Model size and computations

- 효율적인 GPU 연산을 위해 단독으로 CPU에서 사용하는 메모리보다 소비량이 더큼
- MHA 파트는 이론 연산 횟수 대비 속도가 느림, 연산이 여러 조합으로 이루어져있기 때문인 것으로 보여짐
- FFN 파트가 모델의 주된 bottleneck
2. Paper review
2.1 Pruning - structured
- Overview
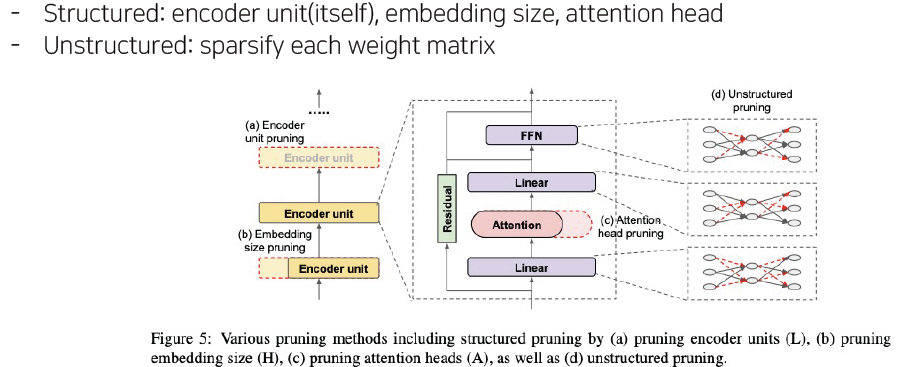
- 다양한 표현 학습을 위해 MHA를 제안했지만, 실제로 Head를 좀 줄여도 성능에 큰 변화가 없었다.

- 하나의 Head만 있어도 성능을 유지 할 수 있었다.
- Are important heads the same across datasets?
- Ablation study on out-of-domain test set to check their generalizability to other datasets
- Iterative pruning of attention heads
- 기존의 MHA에 하이퍼파라미터를 추가
- head가 있다가 없어졌을때의 loss의 변화를 추적
- 값이 크면, 그 head가 큰 의미를 가짐을 의미

2.2 Pruning - unstructured
- Overview
- pretraining에서 finetuning을 적용하면 weight 변화가 크지 않다. 즉 pretraining에서 큰 weight가 그대로 큰값을 가져 pruning에 적용되지 않을 가능 성이 높다.
- pretraining에선 중요한 의미를 가지는데, down stream task에서는 중요하지 않을 수 있으니까.
- Magnitude pruning에서는 original task에서만 중요했던 weight들이 살아 남을 수 있음
- Movement pruning
- Transfer learning 과정에서 weight의 움직임을 누적해가며 pruning할 weight 결정
- Background

- Magnitude pruning can be seen as utilizing 0th order information(fixed value) of the running model.
- Movement pruning utilizes importance derived from 1st order information
- Intuitively, instead of selecting weights that are far from zero(magnitude), retain connections that are moving away from zero during training process
- Method interpretation
- Movement pruning의 score 유도
- Score의 변화에 따른 loss의 변화는 loss function의 weigth에 대한 gradient와 weight의 곱과 같다.

- weight가 0에서 멀어지면, Score가 커진다! -> 어떻게 움직이는 지를 본다.
- Expreiments
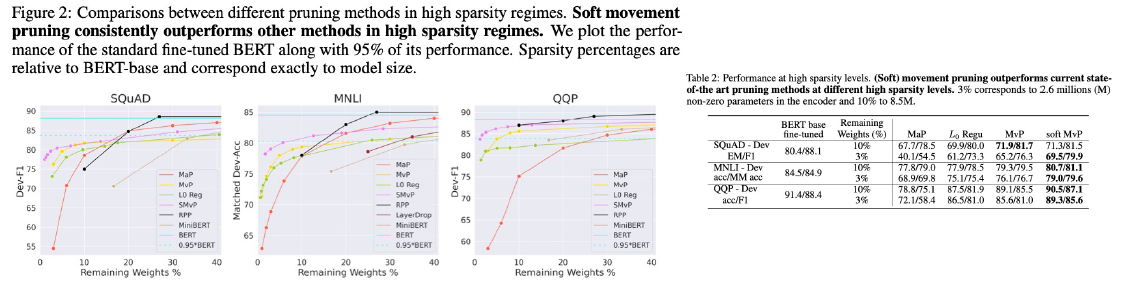
2.3 Pruning 논문
- On the Effect of Dropping Layers of Pre-trained Transformer Models
- https://arxiv.org/pdf/2004.03844.pdf
- Visualizing and Understanding the Effectiveness of BERT
- https://aclanthology.org/D19-1424.pdf
- 요약!
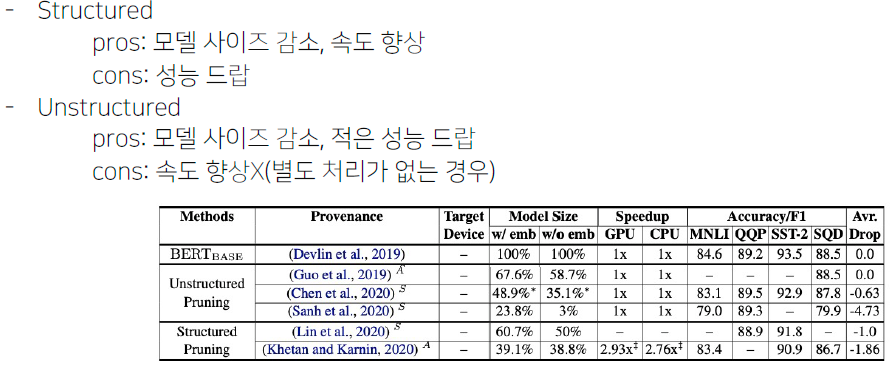
2.4
3. Notes on model compression
7. Further Reading
Reference
