
0. 강의 소개
NLP분야에서도 경량화 기법들이 하루가 다르게 발전하고 있습니다. 모델 경량화 기법 NLP part에서는 Transformer 구조를 메인으로 사용하는 BERT 모델을 중심으로 경량화 기법을 다룹니다. Part 2인 본 강의에서는 Knowledge Distillation을 다룹니다. 특히 Knowledge Distilation은 NLP 경량화에서 큰 관심을 받고있는 분야이니 주의깊게 봐주세요!
1. Overview
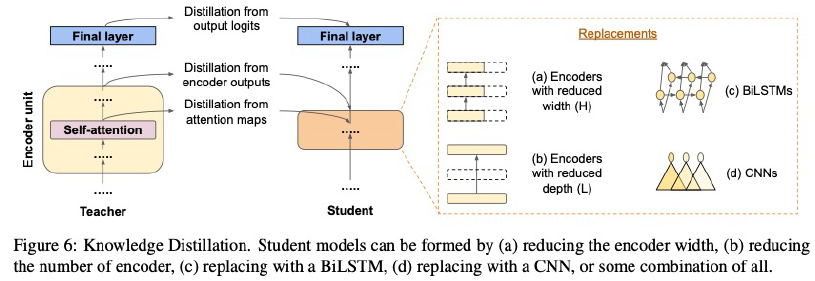
- 가장 핫한 연구 방향
- 큰 네트워크를 어떻게 사용할 것인가?
- 어떻게 네트워크를 줄일 것인가?
- 인코더 구조를 바꾸거나, 그대로 가져가면서 크기를 줄이는 것
- 대표적 연구: Distill BERT
2. Knowledge Distillation
2.1 Distill BERT
- Overview
- pre-training 단계에서 KD 적용
- 3가지 Loss
- MLM task, distillation, consine-similarity
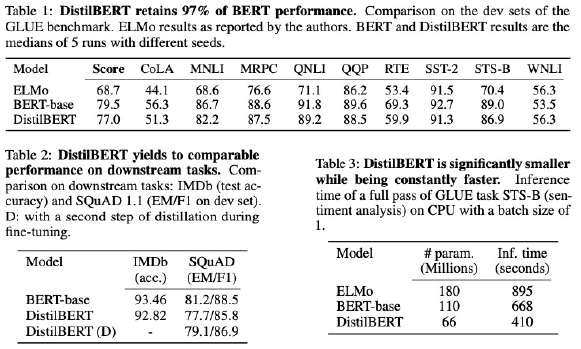
- 모델 크기 40% 줄이고, 60%빠른 모델, 성능은 base의 90%
- Triple loss
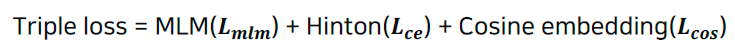
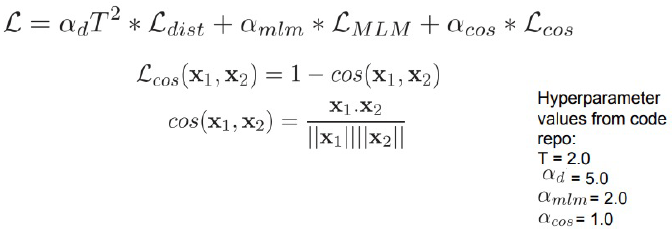
- MLM task, distillation, consine-similarity
- 3가지 loss를 선형결합하여 사용
- Hinton loss recap
- 0에 가까운 확률값들이 모델의 일반화 성능에 영향을 미친다.
- 즉, soft label로 학습을 하는 것이 더 의미적으로 많은 것을 학습할 수 있고 효과적이다.
- E.g. 오늘
이 너무 좋다. - 날씨: 0.02, 기분: 0.32, 주식장: 0.25, …
- E.g. 오늘
- Student architecture & initialization
- 기존 bert에서 token-type embedding 제거
- pooler 제거
- 기본 구조를 반으로 줄임(E.g. 12 layer -> 6 layer)
- hidden dimension을 줄이는 것은 별 효과가 없었음
- teacher의 weight가져오기

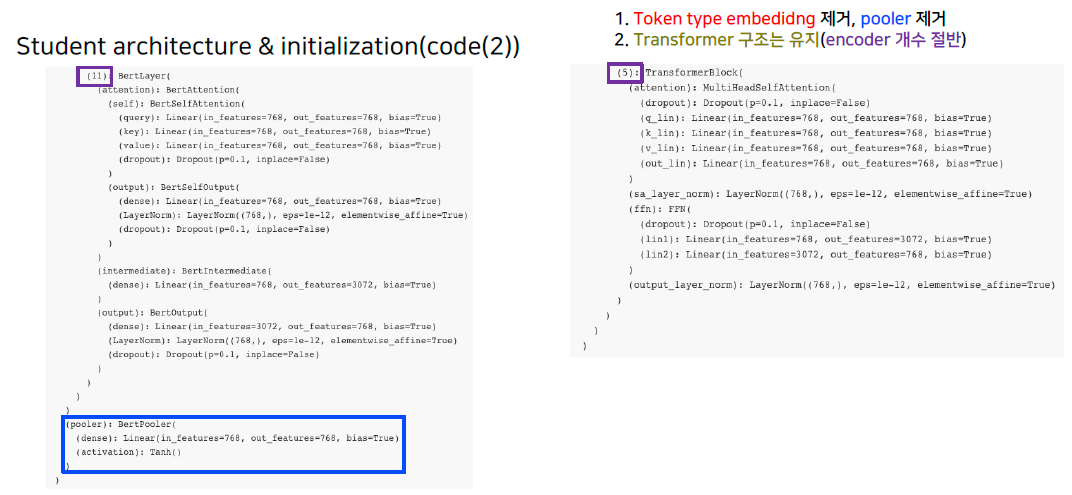
- 아래와 같은 방식으로
- 6번째 layer -> 3번째
- 4번째 layer -> 2번째
- 2번째 layer -> 1번째
- 아래와 같은 방식으로
- 실험결과
2.2 TinyBERT: Distilling BERT0for Natural Language Understanding
- Overview
- Propose
- distillation 방법
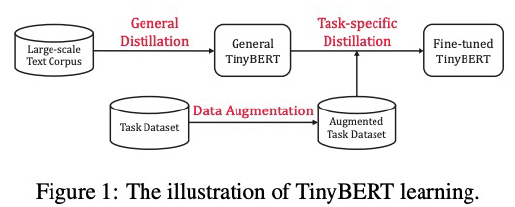
- 2단계 학습 구조
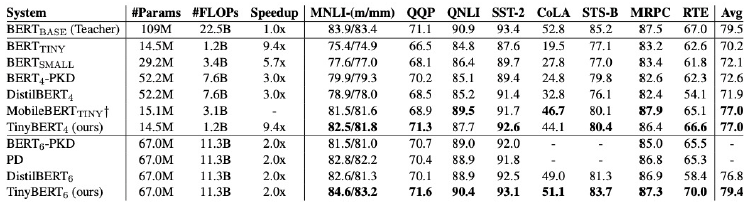
- 4 layer, bert-base의 96% 성능
- inference에서 7.5배 작고, 9.4배 빠름
- TinyBERT with 6 layers performs on-par with its teacher(BERT base)
- 6개 layer는 BERT-base와 거의 동등한 성능
- Propose
- 3 type of loss
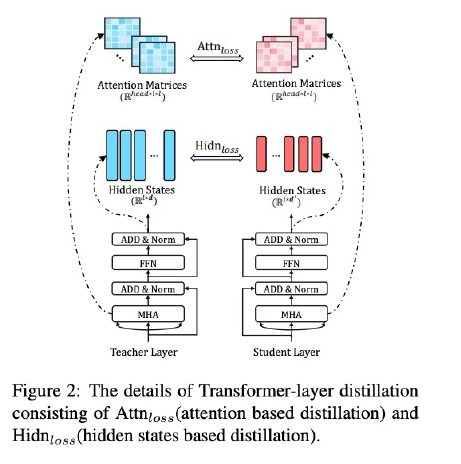

- embedding layer의 output
- hddenstates 와 attention matrices
- student의 weight 크기를 teacher의 크기로 변경해주는 learnable한 matrice를 두어 MSE 계산
- prediction layer의 logits output (hiton loss)
- Two stage learning
- 실험 결과
2.3 기타 논문
- MobileBERT
- BERT 대비 4.3배 소형화, 5.5배 속도 향상
- Exploring the Boundaries of Low-Resource BERT Distillation
- Conv 기반, BiLSTM 기반 + KD, 성능 Drop이 크지만 570배, 40배 속도 향상
- AdaBERT
- KD + NAS(CNN based)로 sub task 학습, avg-2,0 point의 성능 드랍 대비 약 20배의 속도 향상
3. 간단 정리!
Reference
- AI boot camp 2기 경량화 강의