
1. Multi-Head attention
1.1 Problem of single attention
- Only one way for words to interact with one another
- 하나의 행렬 셋만 존재
- 여러 측면에서 정보를 병렬적으로 얻을 수 없음
1.2 Multi-Head attention
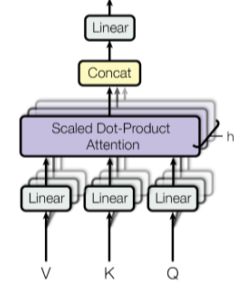
- $MultiHead(Q, K, V) = Concat(head_1, …, head_h)W^o$
- $Where \ head_i=Attention(QW_i^Q, \ KW_i^K, \ VW_i^V)$
- 여러버전의 어텐션을 수행하고 Concat하여 사용
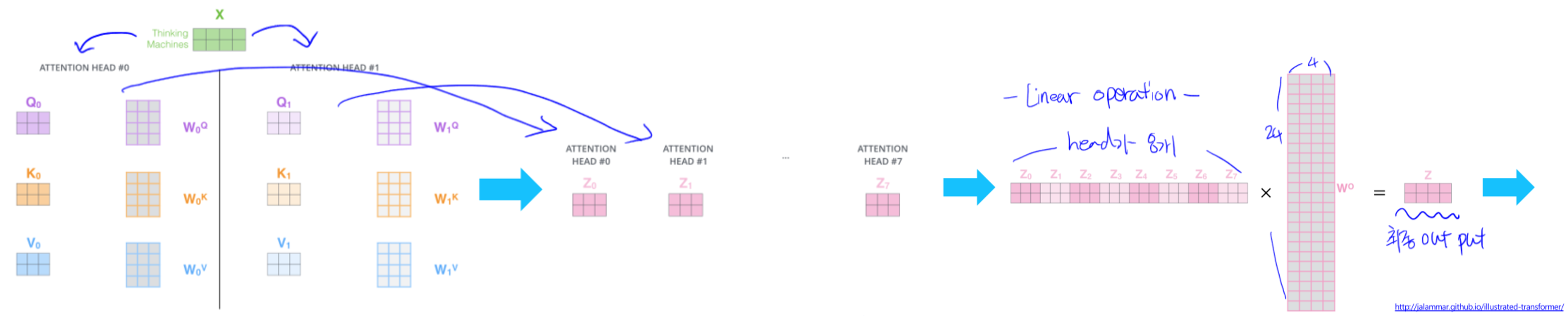
- 여러버전의 어텐션을 수행하고 Concat하여 사용
- 계산 복잡도
- n: sequence 길이
- d: representation의 차원
- k: convolution의 kernel size
- r: neighborhood의 크기
Layer type Complexity per Layer Sequential Operations Maximum Path Length Self-attention $O(n^2 \cdot d)$ $O(1)$ $O(1)$ Recurrent $O(n \cdot d^2)$ $O(n)$ $O(n)$ Convolution $O(k \cdot n \cdot d^2)$ $O(1)$ $O(log_k(n))$ Self-attention (restricted) $O(r \cdot n \cdot d)$ $O(1)$ $O(n/r)$
1.3 Transformer: Block-Based Model
- Block 구조
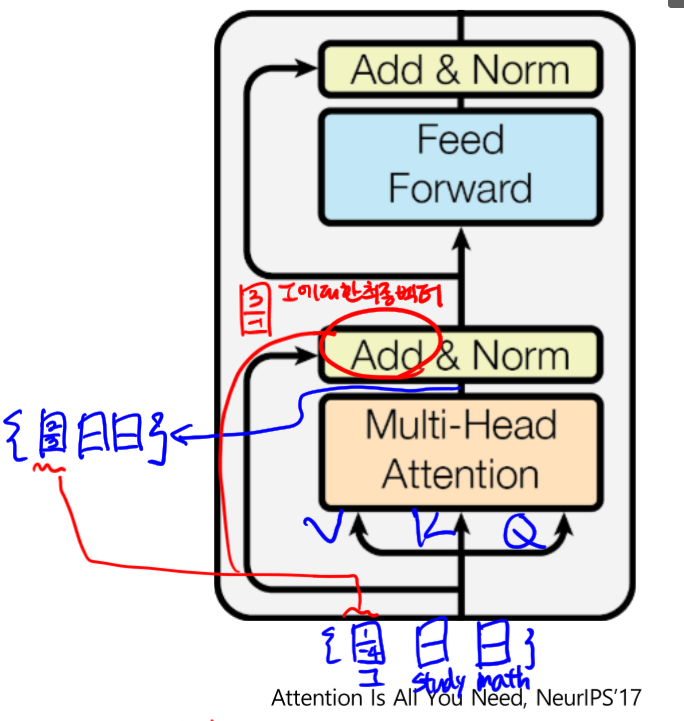
- $LayerNorm(x+sublayer(x))$
- 그림과 같이 ‘I’에 대한 벡터와 ‘I’를 쿼리로한 Attention 모듈의 출력을 Add 해 최종 임베딩 벡터를 얻음 (Why?)
- Gradient vanishing 방지 효과
- 학습안정화 효과
- LayerNorm
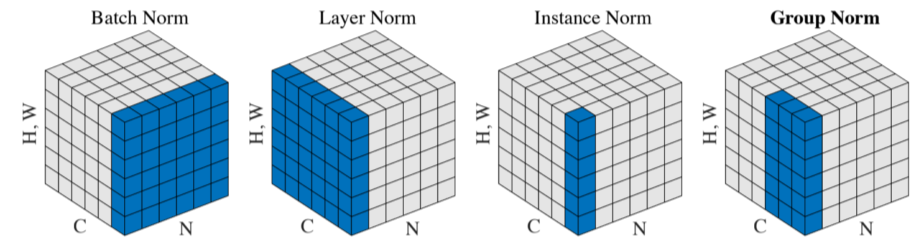
- 주어진 다수의 샘플들에 대해 평균 0, 분산 1로 만들어주고, 원하는 평균과 분산을 주입해 줄 수 있게 해줌
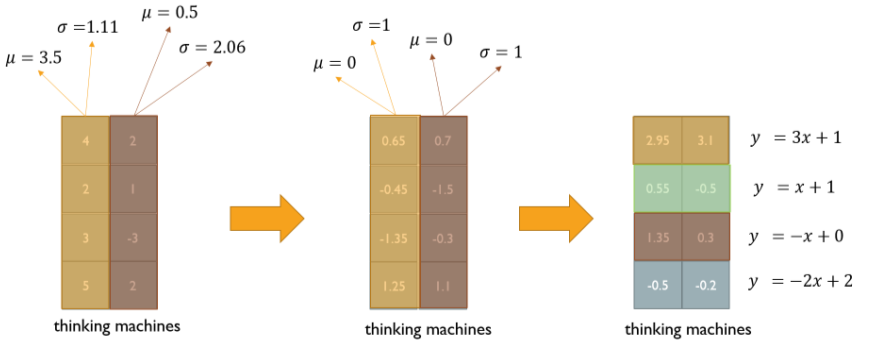
- Batch Normalization
- 주어진 다수의 샘플들에 대해 평균 0, 분산 1로 만들어주고, 원하는 평균과 분산을 주입해 줄 수 있게 해줌
1.4 Transformer: Positional encoding
- {home, go, I} / {I, go, home} 순서로 입력했을 때, I에 대한 임베딩 결과가 동일
- 가중평균을 낼 때, 교환법칙이 성립하기 때문
- 순서를 고려하지 않는 임베딩이 됨
- Positional Encoding
- $PE_{(pos, 2i)} = sin(pos/10000^{2i \over d_{model}})$
- $PE_{(pos, 2i+1)} = cos(pos/10000^{2i \over d_{model}})$
- E.g.

- 실제로 사용하는 sin, cos 조합 벡터
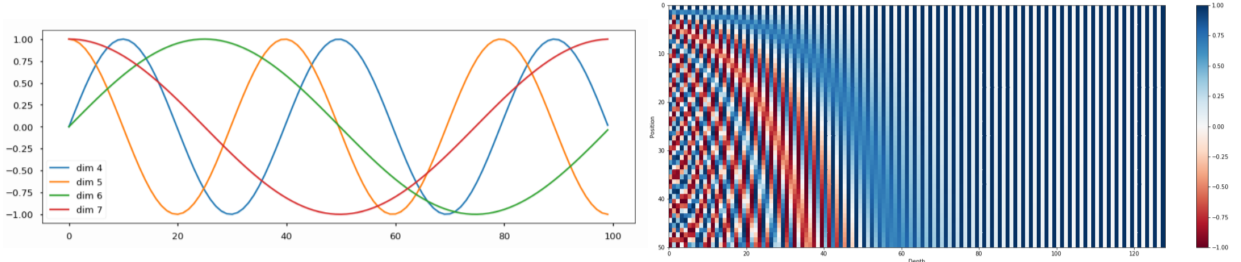
- 실제로 사용하는 sin, cos 조합 벡터
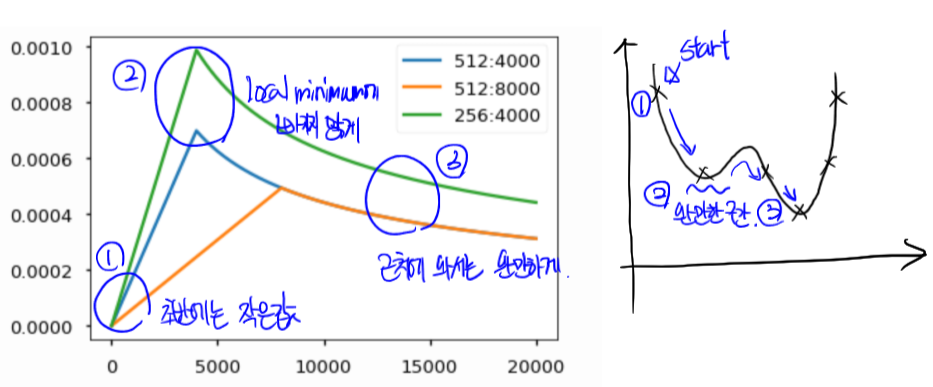
1.5 Tansformer: Warm-up Learning Rate Scheduler
- $learning rate = d_{model}^{-0.5} \cdot min(step^{-0.5}, step \cdot warmup_{steps}^{-1.5}) $
2. Transformer: High-Level View
2.1 Encoder: Self-Attention Visualization
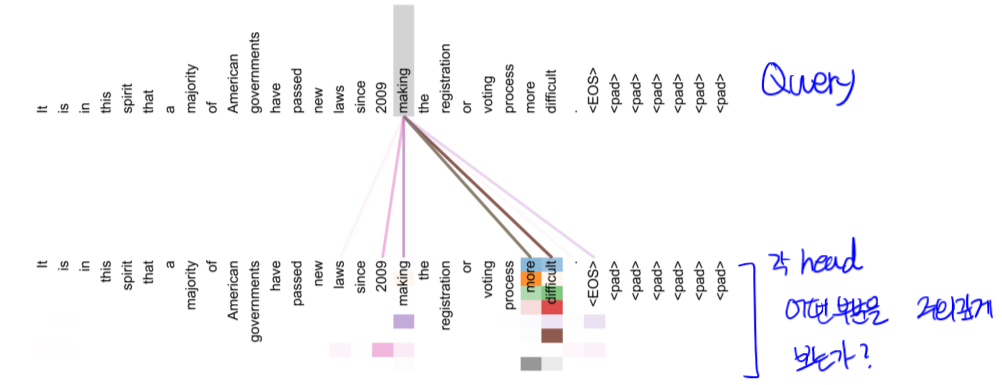
- 윗줄은 Query, 아래는 Attention Value, 색상은 각각 head를 의미
- ‘making’ 이라는 단어에 대해 ‘more’과 ‘difficult’가 큰 관계를 보임
- 이러한 방식으로 시각화를 통해 분석이 가능
2.2 Decoder: Masked Self-Attention
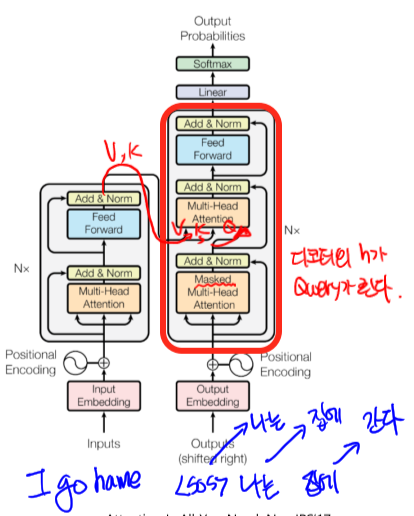
- 인코더로 부터 V, K를 받아옴
- 디코더의 입력으로 부터 생성된 Attention vector가 Query로 사용됨
- Masked Self-Attention
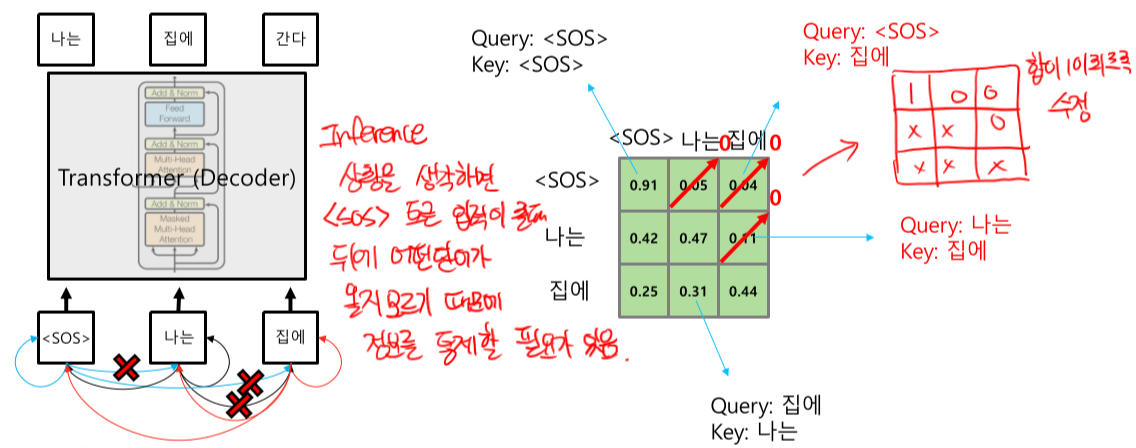
- Inference 상황을 생각해보면, 실제로 뒤에 어떤 단어가 입력으로 들어 올지 decoder는 알 수 없다. 학습 때는 모든 입력값을 넣어주지만, 실제 상황을 고려해 정보를 통제해 줄 필요가 있다. 따라서 그림과 같이 얻을 수 없는 정보에 대해 0으로 처리한 후, 남은 값들을 1이 되게 가중평균을 사용해 맞추어 준다.
2.3 성능비교
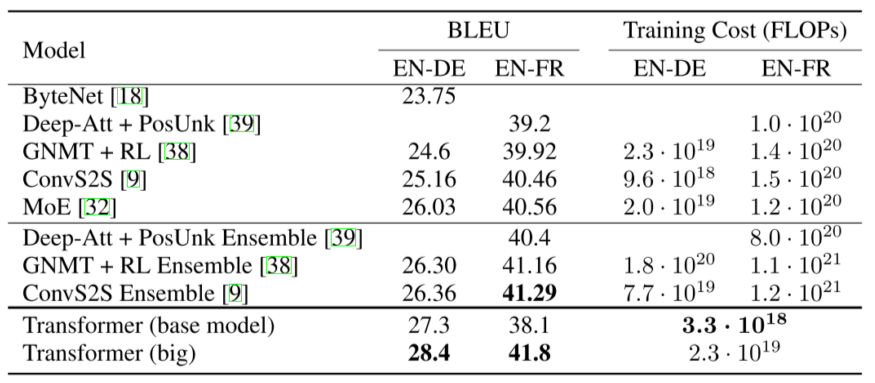
- BLEU score 20 ~ 40%는 서비스 중인 번역 성능과 유사
3. Further Question
- Attention은 이름 그대로 어떤 단어의 정보를 얼마나 가져올 지 알려주는 직관적인 방법처럼 보입니다. Attention을 모델의 Output을 설명하는 데에 활용할 수 있을까요?