
1. BERT 언어모델
1.1 Intro
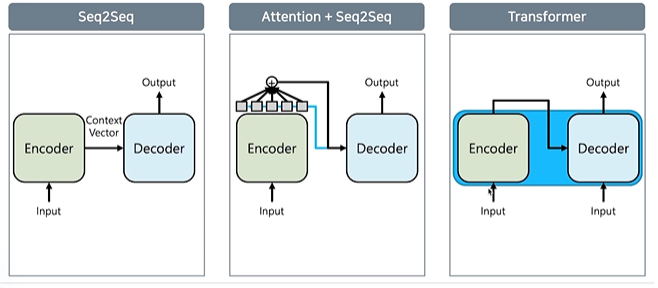
- Seq2Seq의 단점을 보완하기 위해 Seq2Seq + Attention, 최신 모델인 transformer로 발전중
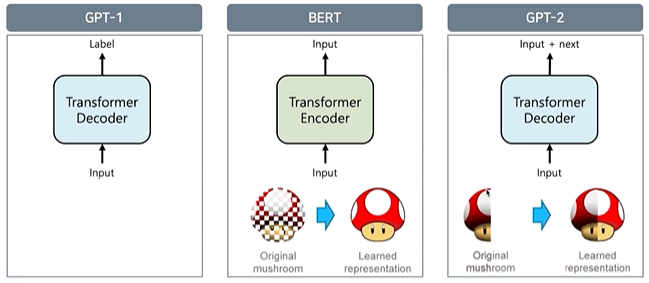
- GPT-1 $\rightarrow$ BERT $\rightarrow$ GPT-2 순으로 모델 제안
- BERT
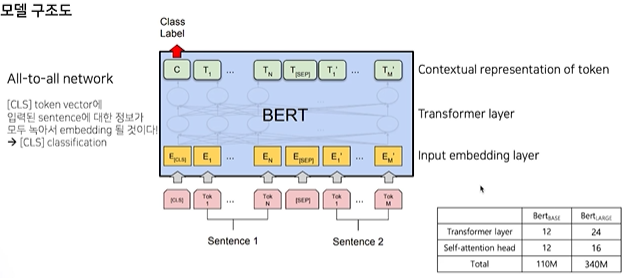
- [CLS] token은 sentence의 모든 정보가 담김
- Masked Language Model
- Dataset
- GLUE data, task
- SQuAD v1.1 질의응답
- CoNLL 2003 개체명 분류
- SWAG 다음에 이어질 자연스러운 문장 선택
1.2 BERT 응용
-
감정 분석
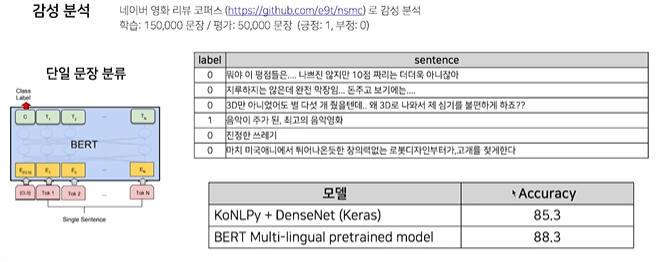
-
관계 추출
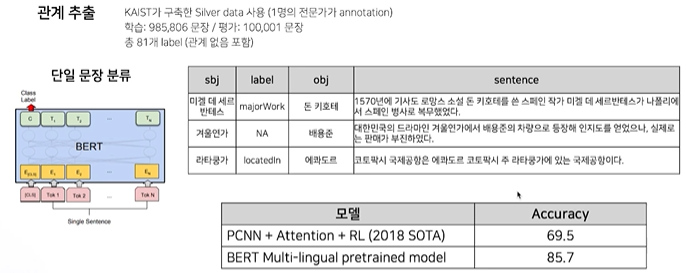
-
의미 비교
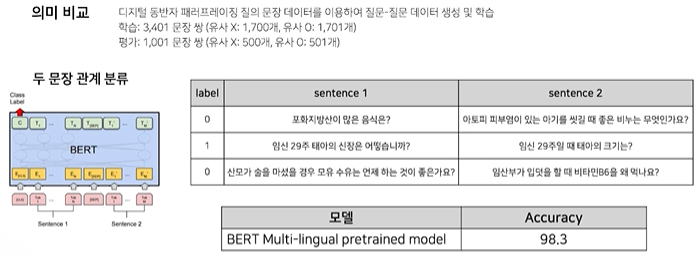
-
개체명 분석
-
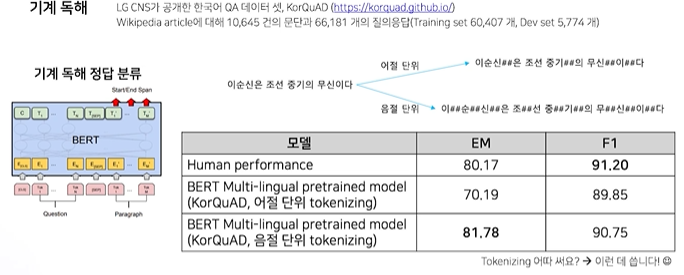
기계 독해
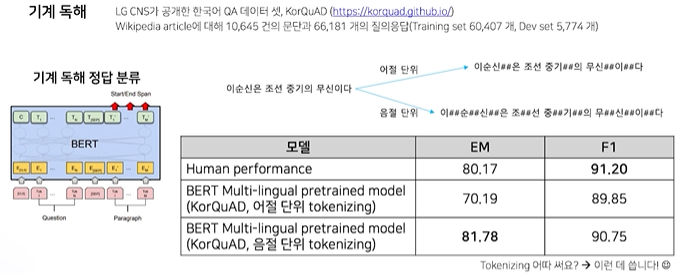
1.3 한국어 BERT 모델
- ETRI
- 형태소단위로 분리 후, Word piece 적용
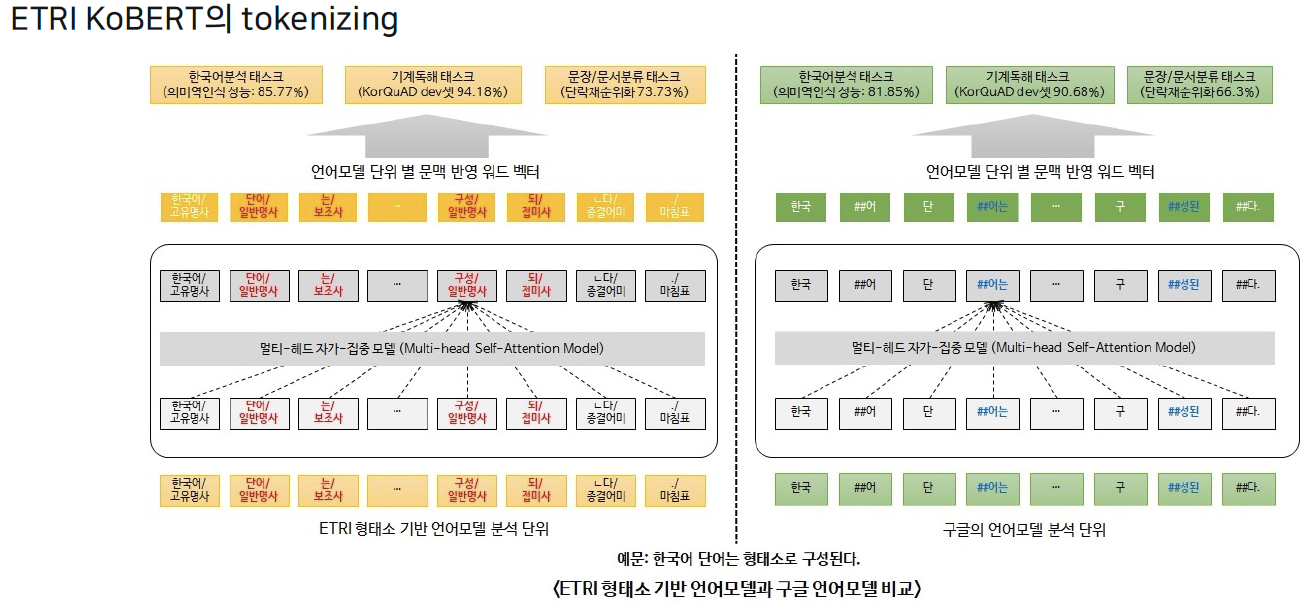
- 형태소단위로 분리 후, Word piece 적용
- 스캐터랩
- Advanced BERT model
- 중요한 정보에 따라 전처리를 잘 해주는 것이 중요
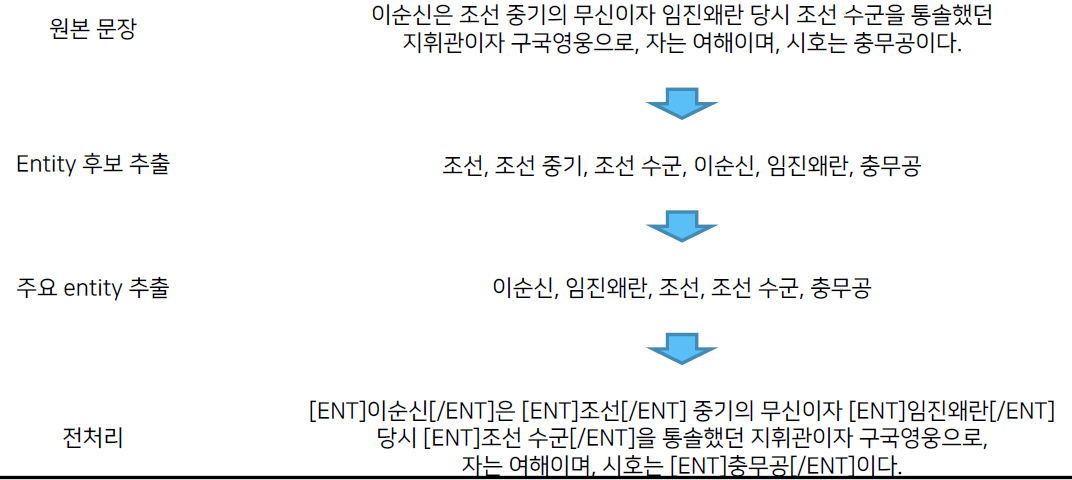
- 중요한 정보에 따라 전처리를 잘 해주는 것이 중요
2. BERT 기반 단일 문장 분류 모델
3. BERT Special Token 추가하기
# 추가 하고 싶은 Special token dict 정의
special_tokens_dict = {'additional_special_tokens': ['[C1]','[C2]','[C3]','[C4]']}
# tokenizer에 더해주기
num_added_toks = tokenizer.add_special_tokens(special_tokens_dict)
# 모델도 늘려줘야함!
model.resize_token_embeddings(len(tokenizer))