
1. Generation-based MRC
1.1 문제 정의
- 주어진 지문과 질의를 보고, 답변을 생성 -> 분류가 아니라 생성문제
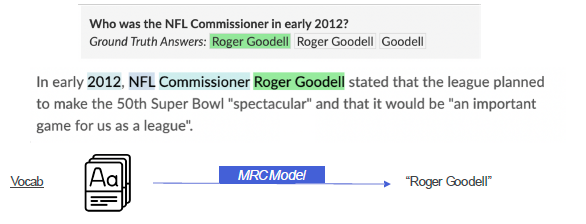
1.2 평가 방법
- Extraction-based MRC와 동일한 방법을 사용 (EM, F1 score)
- BLEU(Bilingual Evaluation Understudy Score) 나 ROGUE
1.3 Extraction vs Generation
- MRC 모델 구조
- PLM + Classifier 구조 vs Seq-to-seq PLM 구조
- Loss 형태 및 Prediction 형태
- 지문내 답의 위치 vs Free-form text 형태
- Extraction은 score계산을 위해 별도로 text 변환 과정이 필요
- BERT를 사용할 수 없음 (인코더 구조만 있기 때문에), BART 사용
2. Pre-processing
2.1 입력 표현
- 데이터 예시

- 토큰화
- WordPiece Tokenizer를 사용
- E.g 미국 군대 내 두번째로 높은 직위는 무엇인가?
- [‘미국’, ‘군대’, ‘내’, ‘두번째’, ‘##로’, ‘높은’, ‘직’, ‘##위는’, ‘무엇인가’, ‘?’]
- Special Token
- CLS, SEP, PAD, UNK 등
- 경우에 따라, question: , context: 도 사용
- Additional information
- Attention mask
- Token type ids
- BART에서는 입력시퀀스에 대한 구분이 없어 존재하지 않음
2.2 출력 표현
- 정답 출력
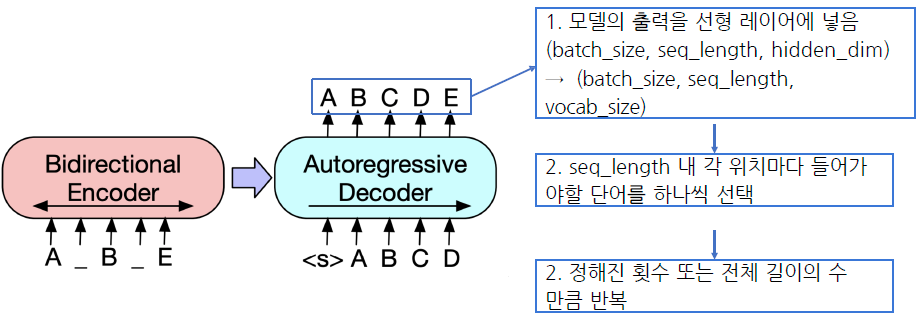
3. Model
3.1 BART
- 실제로 pretraining 과정에서도 mask된 단어를 알아 맞추는 방식이 아니라 생성하는 방향으로 학습을 한다.
- 문장에 구멍을 뚫어놓고(노이즈를 주고) 복구(복원)하는 방식
- Reconstruction 과정이기 떄문에 denoising autoencoder 라고도 함
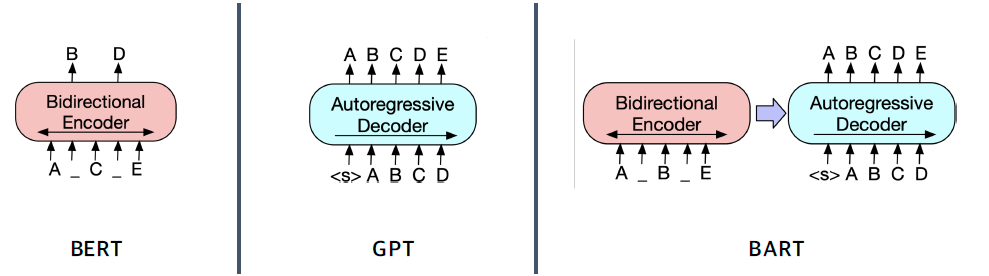
3.2 BART Encoder & Decoder
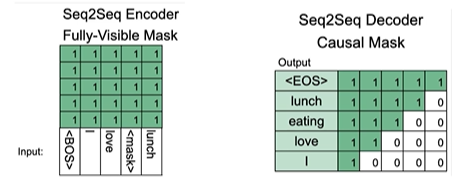
- 인코더는 BERT 처럼 bi-directional
- 디코더는 GPT 처럼 uni-directional(autoregressive)
4. Post-processing
4.1 Searching
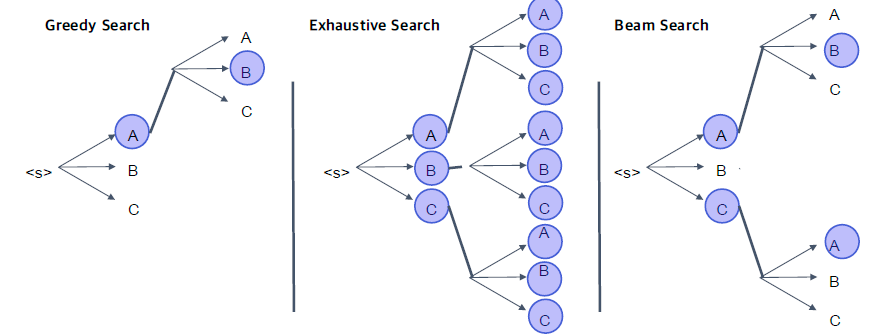
- Greedy search
- 가장 확률이 높은 단어로만 탐색 $\rightarrow$ 한번 잘 못된 선택을 하면 이상한 output이 나올 가능 성이 있다.
- Exhausitive search
- 모든 가능한 경우를 보는것 $\rightarrow$ 실제로 time complexity를 생각해보면 불가능한 방법
- Beam search
- time step 마다 랭킹을 매기고, 랭킹이 떨어진 후보들은 버리는 방법
- 상세!
5. 코드로 다루어 보기
-
Dataset 다운로드
from datasets import load_dataset datasets = load_dataset("squad_kor_v1") -
Metric 설정
from datasets import load_metric metric = load_metric('squad') -
Pretrained 모델 불러오기
from transformers import AutoConfig, AutoModelForQuestionAnswering, AutoTokenizer model_name = "google/mt5-small" # BART와 유사한 generation model config = AutoConfig.from_pretrained( model_name ) tokenizer = AutoTokenizer.from_pretrained( model_name, use_fast=True ) model = AutoModelForQuestionAnswering.from_pretrained( model_name, config=config ) -
Hyper paremters 셋팅하기
max_source_length = 1024 max_target_length = 128 # 생성할 문장의 길이 padding = False preprocessing_num_workers=12 num_beams = 2 max_train_samples = 16 max_val_samples = 16 num_train_epochs = 3 -
Fine-tunning 하기
args = Seq2SeqTrainingArguments( output_dir='outputs', do_train=True, do_eval=True, predict_with_generate=True, num_train_epochs=num_train_epochs ) trainer = Seq2SeqTrainer( model=model, args=args, train_dataset=train_dataset, eval_dataset=eval_dataset, tokenizer=tokenizer, data_collator=data_collator, compute_metrics=compute_metrics, ) train_result = trainer.train(resume_from_checkpoint=None) -
평가하기
metrics = trainer.evaluate( max_length=max_target_length, num_beams=num_beams, metric_key_prefix="eval" ) -
생성하기
document = "이순신의 직업은 뭐야?" input_ids = tokenizer(document, return_tensors='pt').input_ids outputs = model.generate(input_ids) tokenizer.decode(outputs[0], skip_special_tokens=True)