
1. 개인학습
2. 필수과제
- LSTM
# LSTM 설정
self.rnn = nn.LSTM(
input_size=self.xdim,hidden_size=self.hdim,num_layers=self.n_layer,batch_first=True)
# h와 c의 크기
h0 = torch.zeros(self.n_layer, x.size(0), self.hdim).to(device)
c0 = torch.zeros(self.n_layer, x.size(0), self.hdim).to(device)
- Transformer
- $\text{Attention}(Q,K,V) = \text{softmax} ({QK^T \over \sqrt{d_K}}) V \in \mathbb{R}^{n \times d_V} $
SPDA = ScaledDotProductAttention() # d_K(=d_Q) does not necessarily be equal to d_V n_batch,d_K,d_V = 3,128,256 n_Q,n_K,n_V = 30,50,50 Q = torch.rand(n_batch,n_Q,d_K) K = torch.rand(n_batch,n_K,d_K) V = torch.rand(n_batch,n_V,d_V) out,attention = SPDA.forward(Q,K,V,mask=None)- Multihead-attention
- $\text{head}{\color{red}i} = \text{Attention}(Q {\color{green}W}^Q{\color{red}i},K {\color{green}W}^K_{\color{red}i}, V {\color{green}W}^V_{\color{red}i}) $
3. Git 특강 2
- branch 만들고 합치기
- pull = fetch + merge
4. 피어 세션
- RNN, Tramsformer 강의요약
- 필수 과제 리뷰
- 코딩테스트 코드 리뷰
5. 선택과제
- Vision transformer
- Image(Patch) embedding
-
- 이미지를 패치 크기로 분할
-
- positioncal embedding 벡터를 붙인 class token vector 생성
# (1) Build [token; image embedding] by concatenating class token with image embedding # x: embedded patches c = repeat(self.cls_token, '() n d -> b n d', b=batch) x = torch.cat([c, x], dim=1)
- positioncal embedding 벡터를 붙인 class token vector 생성
-
- Transformer encoder
- $ z_l^{‘} = MSA(LN(z_{l-1})) + z_{l-1} $
- $ z_l = MLP(LN(z_l^{‘})) + z_l^{‘} $
# forward x = self.norm_1(x) _x, attention = self.mha(x) x = _x + x _x = self.norm_2(x) _x = self.mlp(_x) x = _x + x - Body
def forward(self, x): # ================ ToDo3 ================ # # (1) image embedding x = self.ie(x) # (2) transformer_encoder x, attentions = self.em(x) # ======================================= # x = x[:, 0, :] # cls_token output x = self.normalization(x) x = self.classification_head(x) return x, attentions - Result
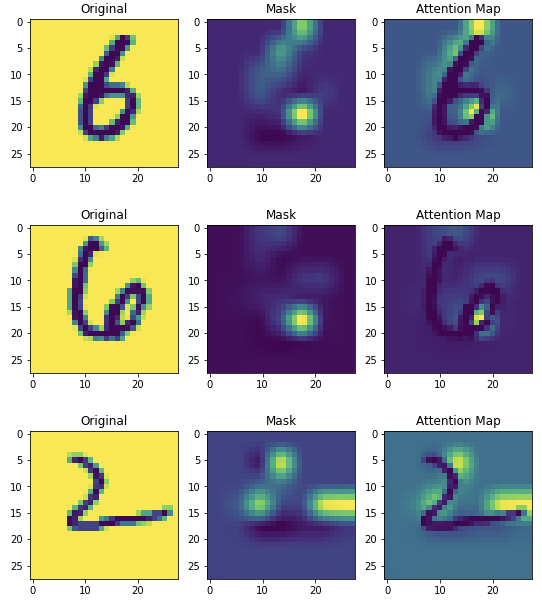
- Image(Patch) embedding
- AAE
- 모델 구현
# Encoder 일부 구조 self.model = nn.Sequential( nn.Linear(1024, 512), nn.Dropout(p=0.2), #TODO 1: dropout layer을 넣어주세요 nn.ReLU(), #TODO 2: relu layer을 넣어주세요 nn.Linear(512, 512), #TODO 3: linear layer을 넣어주세요 nn.Dropout(p=0.2), nn.ReLU() ) # Decoder 일부 구조 self.model = nn.Sequential( nn.Linear(latent_dim, 512), nn.Dropout(p=0.2), nn.ReLU(), nn.Linear(512, 512), nn.BatchNorm1d(512), nn.Dropout(p=0.2), nn.ReLU(), nn.Linear(512, 1024), #TODO 4: linear layer을 넣어주세요. 힌트: Encoder의 첫번째 layer를 주목해주세요. nn.Tanh(), ) # Discriminator 일부 구조 self.model = nn.Sequential( nn.Linear(latent_dim, 512), #TODO 5: linear layer을 넣어주세요. 힌트: Decoder의 첫번째 layer을 주목해주세요. nn.Dropout(p=0.2), nn.ReLU(), nn.Linear(512, 256), nn.Dropout(p=0.2), nn.ReLU(), nn.Linear(256,1), #TODO 6: linear layer을 넣어주세요. output의 dimension은 1입니다. nn.Sigmoid() #TODO 7: sigmoid layer을 넣어주세요. )- 결과
